Pytorch 7 :Memory Optimization(Freeing GPU/NPU Memory Early)
导言
- 对于不使用的python对象,如何释放?
- python 的对象管理机制
- del,empty_cache , gc_collect的原理
导言
learning rate、clip_norm、梯度累计、micro bs 这些通用超参,应该如何调整。
Train Stages: Pretrain, Mid-Train(CT), SFT, RL
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
RL Algorithms: PPO-RLHF & GRPO-family
导言
- RLHF 利用复杂的反馈回路,结合人工评估和奖励模型来指导人工智能的学习过程。(RLHF = 人类偏好数据 + Reward Model + RL(如 PPO), 所以RLHF是RL的一种实践方式)
- 尽管DPO相对于PPO-RHLF更直接,但是(Reinforcement Learning from Verifiable Rewards (RLVR))往往效果更好;
- 而RLVR算法在 2025年的GRPO提出后,其变种和应用范围迎来了井喷爆发。
- 本文详细介绍 PPO、GRPO以及DAPO。
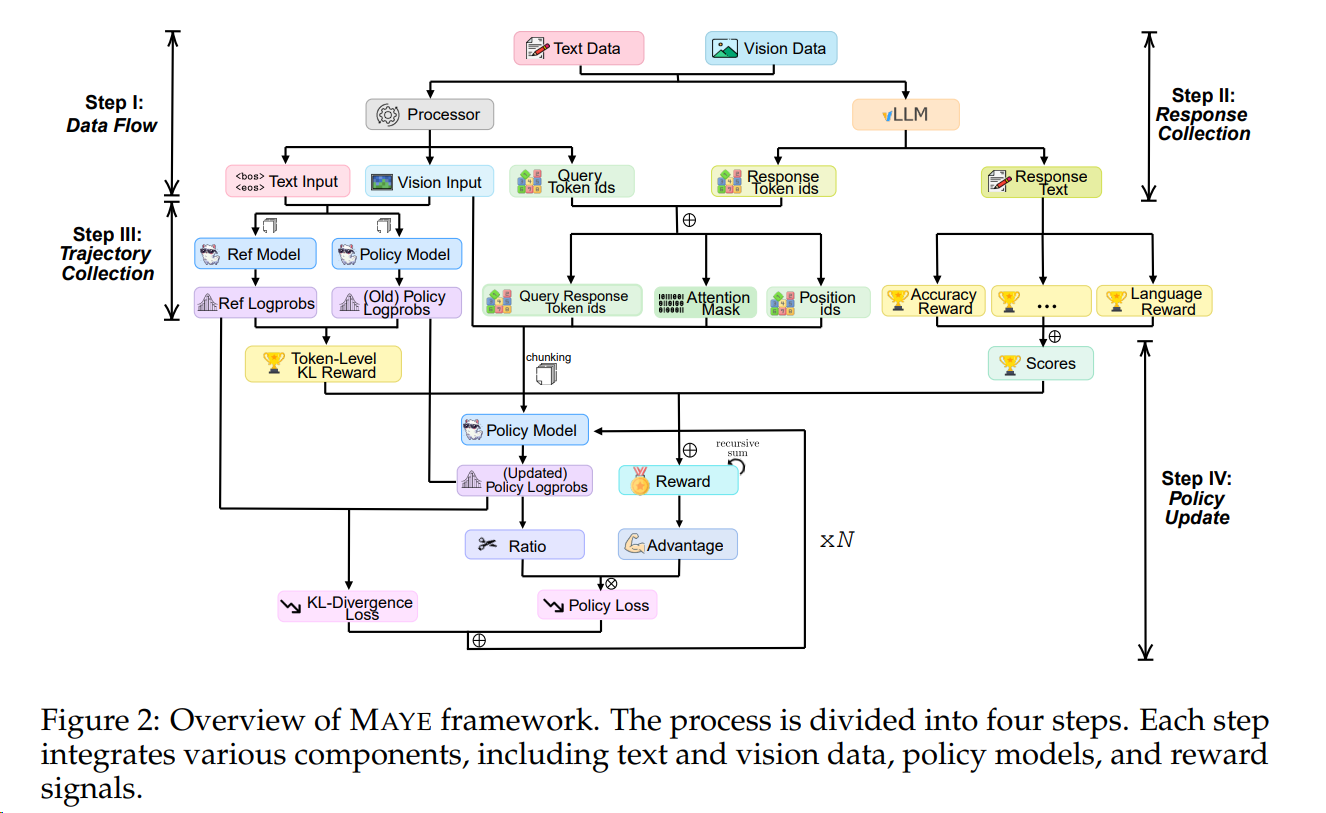 [^1]
[^1]
必看好文[^2]
导言
- 背景问题:传统RL的算法和奖励都要特殊设计,并且不同领域迁移性很差;
- 想法: 能不能系统自己迭代产生适合的RL算法
- 构建一个能够表征广泛强化学习规则的搜索空间,让系统通过多代智能体在复杂环境中的交互经验,元学习(Meta-Learning)出最优的强化学习更新规则。[^1]
Bridging the Gap: Challenges and Trends in Multimodal RL.
导言
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
- 说实话有点头大
- 多模态理解模型的主体就是LLM,LLM的RL基本半年后会迁移到多模态理解上,所以我要跟踪LLM RL的文章
- 多模态生成模型的RL偏向DPO为主的另一条路子;
- 多模态还涉及agent、具身智能,RL又有些不同;
- 文章多到看得头大。
导言
- 在训练开发部待了一年,发现一个人在集体里的作用是渺小的,只能负责了一个模块,但是领导却希望你是个全才。而且中国互联网是人力密集型产业。堆人力,不停试。开发人员大部分工作都是消耗在了繁琐的流程上,消磨了意志,相对于2012那些预研的人员,学习提升有限。
- 最主要是我花的时间,并产生不了技术壁垒,无法保护自己;
- 打工是不可能发财的,现在还能靠还灵光的脑子来学习新技术,等自己老了就只能被新员工淘汰了。
- 只有产生规模效应,加上低成本,自动化的工作才能真正积累财富。[^1] 简单来说就是在有需求的地方做平台收人头费。
- 我当前选择的就是自建自动量化投资平台(资金管理平台),
- 首先,可以弥补我欠缺的金融知识;学会合理的管钱
- 其次,在不成熟之前可以自用;
- 好用之后,可以商业化。
- 但是个人开发周期3~7年,希望重策略轻软件框架,毕竟时间跨度大,合适的软件框架估计变了。
- 唯一的问题:难度可能太高了,比如,最后发现不了赚钱的量化策略。
- 还有另一种可能,在洞察到平台商业机会后,通过快速软件化(前后端)上线。
Pytorch 2.5 :Dataset & Dataloader
导言
- 数据集与数据加载器:学习如何使用torch.utils.data.Dataset和DataLoader来加载和处理数据。
- 数据预处理:介绍常用的数据预处理方法,如归一化、数据增强等。
Why Choose Quantitative Finance
导言
为什么之前认为金融只是调配资源,并不产生生产价值的我。也会想搞量化。
Categories
- AI6
- Algorithms12
- Architecture41
- Artificial Intelligence47
- Camp1
- Databases2
- HPC1
- Math2
- Network8
- OOW35
- Operating system8
- Overview15
- Programming40
- ProjectRecord3
- Software1
- Thinking11
- Tips9
- Treasure1
- Tutorials118
- Values2
- architecture2
- diary4
- english4
- hardware2
- love1
- math3
- network19
- operating system5
- programming1
- security3
- software23
- thinking9
- tips5
- toLearn55
- values2
Subscribe for updates
follow.it
Recents
Archives
- February 20266
- January 20267
- December 202518
- November 20256
- October 20251
- September 20252
- May 20253
- April 20251
- March 20254
- February 20254
- January 20254
- December 20245
- November 20241
- October 20245
- September 202411
- August 20243
- July 20244
- June 20241
- May 20242
- April 20248
- March 20243
- February 20241
- January 202414
- December 202321
- November 202333
- October 202358
- September 202337
- August 202323
- July 202324
- June 202313
- May 202319
- April 20239
- March 20235
- February 20232
- January 20236
- December 20222
- November 20224
- October 20225
- September 20224
- August 20228
- July 20227
- June 20227
- May 202210
- April 20225
- March 20227
- February 20222
- January 20225
- December 20214
- November 20212
- October 202114
- September 202111
- August 202113
- July 202128