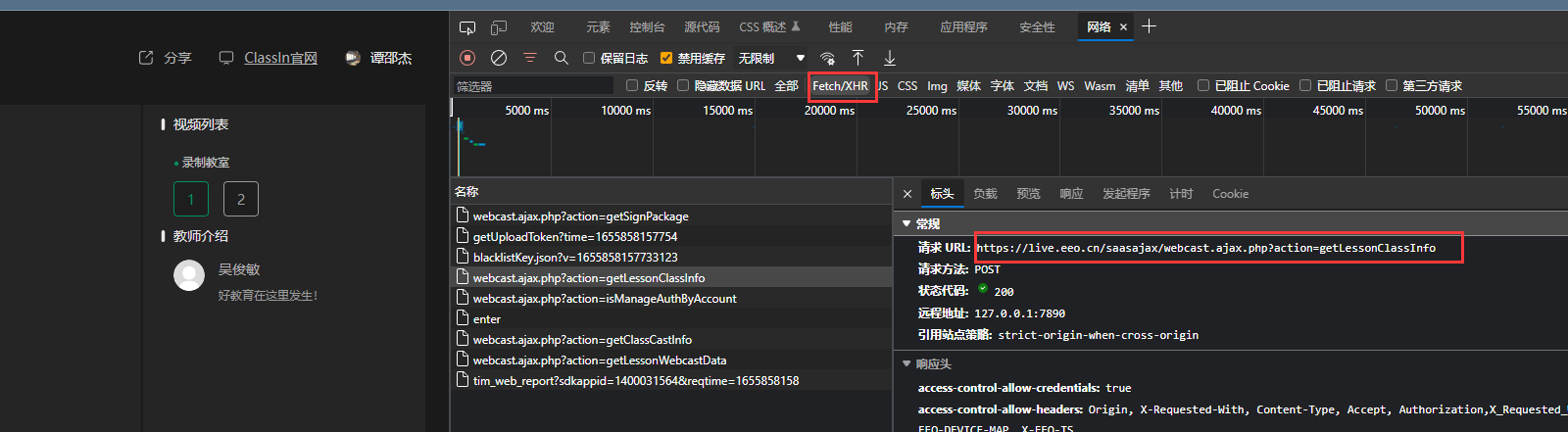
from urllib import request base_url = 'https://f.us.sinaimg.cn/001KhC86lx07laEy0PtC01040200y8vC0k010.mp4?label=mp4_hd&template=640x360.28&Expires=1528689591&ssig=qhWun5Mago&KID=unistore,video' #下载进度函数 def report(a,b,c): ''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100: per = 100 if per % 1 == 1: print ('%.2f%%' % per) #使用下载函数下载视频并调用进度函数输出下载进度 request.urlretrieve(url=base_url,filename='weibo/1.mp4',reporthook=report,data=None)
int main() { const float PI = 3.1415927; const int N = 150; const float h = 2 * PI / N; float x[N] = { 0.0 }; float u[N] = { 0.0 }; float result_parallel[N] = { 0.0 }; for (int i = 0; i < N; ++i) { x[i] = 2 * PI*i / N; u[i] = sinf(x[i]); } ddParallel(result_parallel, u, N, h); }
Kernel Launching
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
#define TPB 64 #define RAD 1 // radius of the stencil … void ddParallel(float *out, const float *in, int n, float h) { float *d_in = 0, *d_out = 0; cudaMalloc(&d_in, n * sizeof(float)); cudaMalloc(&d_out, n * sizeof(float)); cudaMemcpy(d_in, in, n * sizeof(float), cudaMemcpyHostToDevice);
// Set shared memory size in bytes const size_t smemSize = (TPB + 2 * RAD) * sizeof(float); ddKernel<<<(n + TPB - 1)/TPB, TPB, smemSize>>>(d_out, d_in, n, h); cudaMemcpy(out, d_out, n * sizeof(float), cudaMemcpyDeviceToHost); cudaFree(d_in); cudaFree(d_out); }
Kernel Definition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
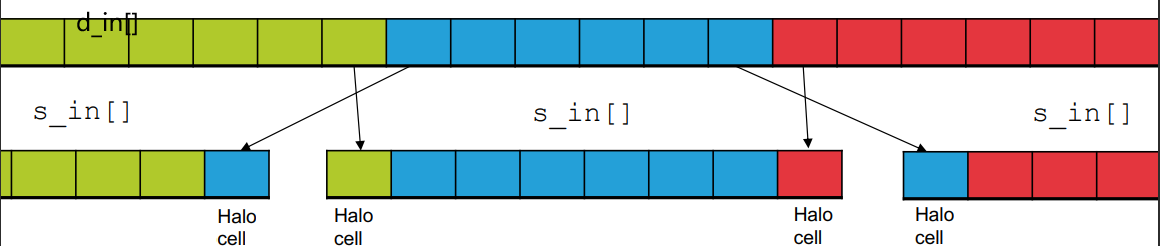
__global__ void ddKernel(float *d_out, const float *d_in, int size, float h) { const int i = threadIdx.x + blockDim.x * blockIdx.x; if (i >= size) return; const int s_idx = threadIdx.x + RAD; extern __shared__ float s_in[];
对齐(Starting address for a region must be a multiple of region size)集体访问,有数量级的差异Coalesced
利用好每个block里的thread,全部每个线程各自读取自己对齐(Starting address for a region must be a multiple of region size 不一定是自己用的)数据到shared memory开辟的总空间。由于需要的数据全部合力读取进来了,计算时正常使用需要的读入的数据。
特别是对于结构体使用SoA(structure of arrays)而不是AoS(array of structures), 如果结构体实在不能对齐, 可以使用 __align(X), where X = 4, 8, or 16.强制对齐。
对齐读取 float3 code
对于small Kernel和访存瓶颈的Kernel影响很大
由于需要对齐读取,3float是12字节,所以只能拆成三份。
有无采用对齐shared读取,有10倍的加速。
利用好Shared Memory
比globalMemory快百倍
可以来避免 non-Coalesced access
SM的线程可以共享
Use one / a few threads to load / compute data shared by all threads
__global__ void reduce0(int *g_idata, int *g_odata) { extern __shared__ int sdata[];
// each thread loads one element from global to shared mem unsigned int tid = threadIdx.x; unsigned int i = blockIdx.x*blockDim.x + threadIdx.x; sdata[tid] = g_idata[i]; __syncthreads();
// do reduction in shared mem for(unsigned int s=1; s < blockDim.x; s *= 2) { if (tid % (s) == 0) { sdata[tid] += sdata[tid + s]; } __syncthreads(); }
// write result for this block to global mem if (tid == 0) g_odata[blockIdx.x] = sdata[0]; }
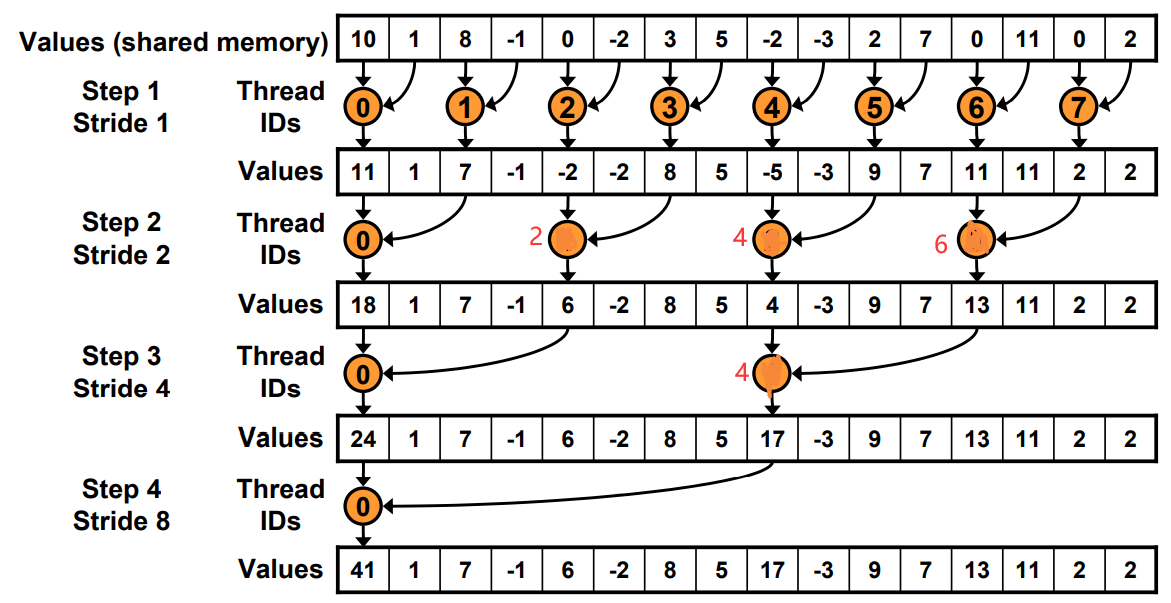
工作的线程越来越少。一开始是全部,最后一次只有thread0.
Step1 : 使用连续的index
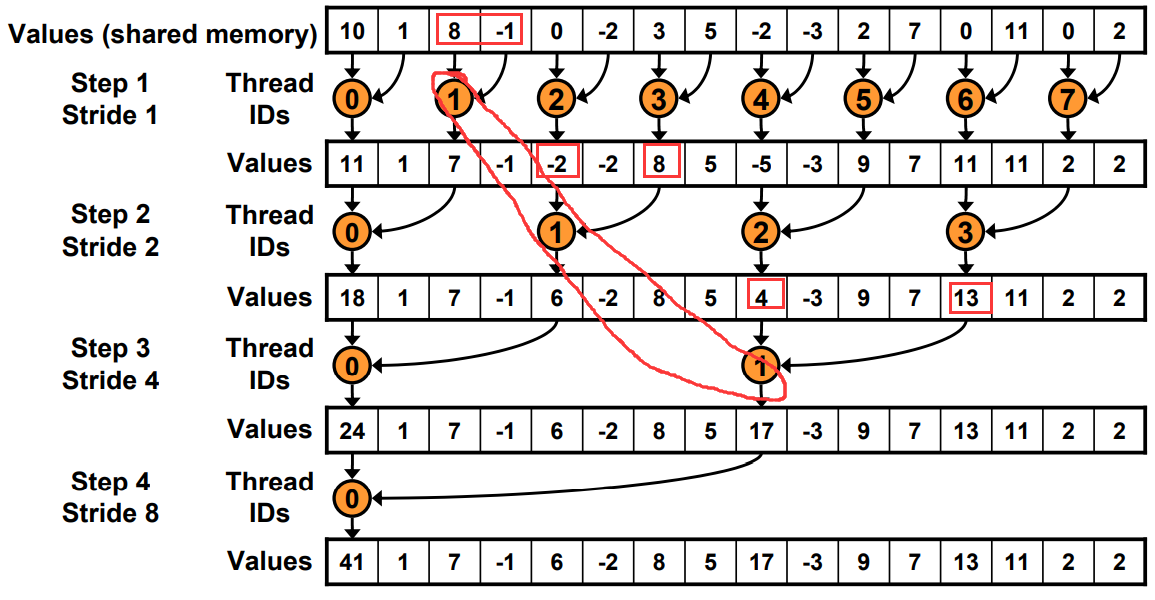
Just replace divergent branch With strided index and non-divergent branch,但是会带来bank conflict。
原理和Warp发射有关,假如在这里每个Warp并行的线程是2。一个Warp运行耗时为T.
Step0: 4+4+2+1=11T
Step1: 4+2+1+1=8T
1 2 3 4 5 6 7
for (unsignedint s=1; s < blockDim.x; s *= 2) { int index = 2 * s * tid; if (index < blockDim.x) { sdata[index] += sdata[index + s]; } __syncthreads(); }
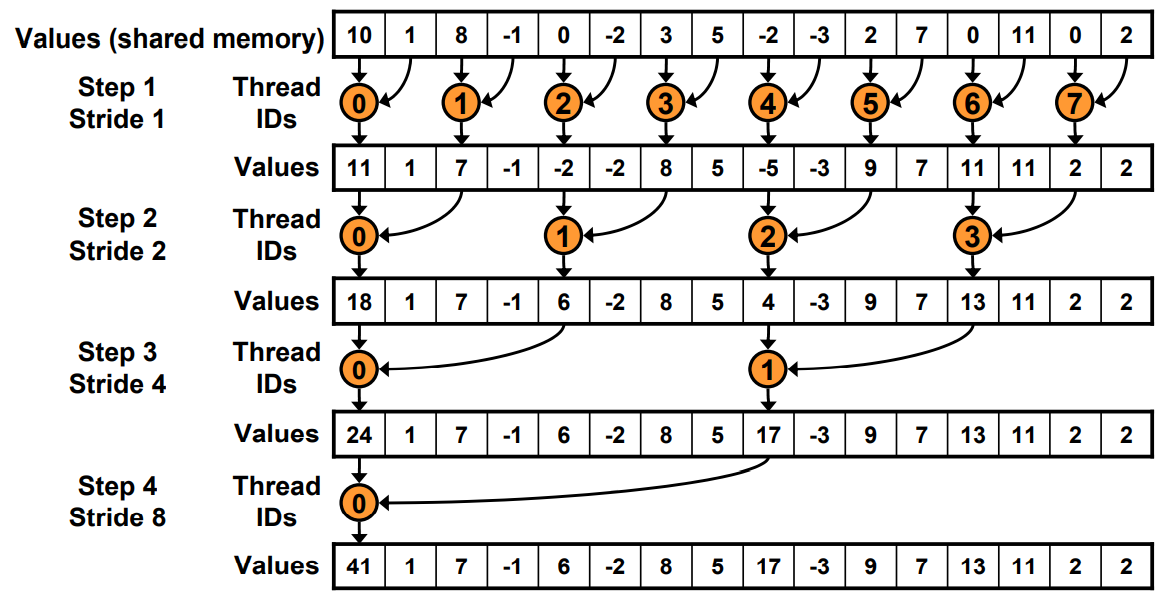
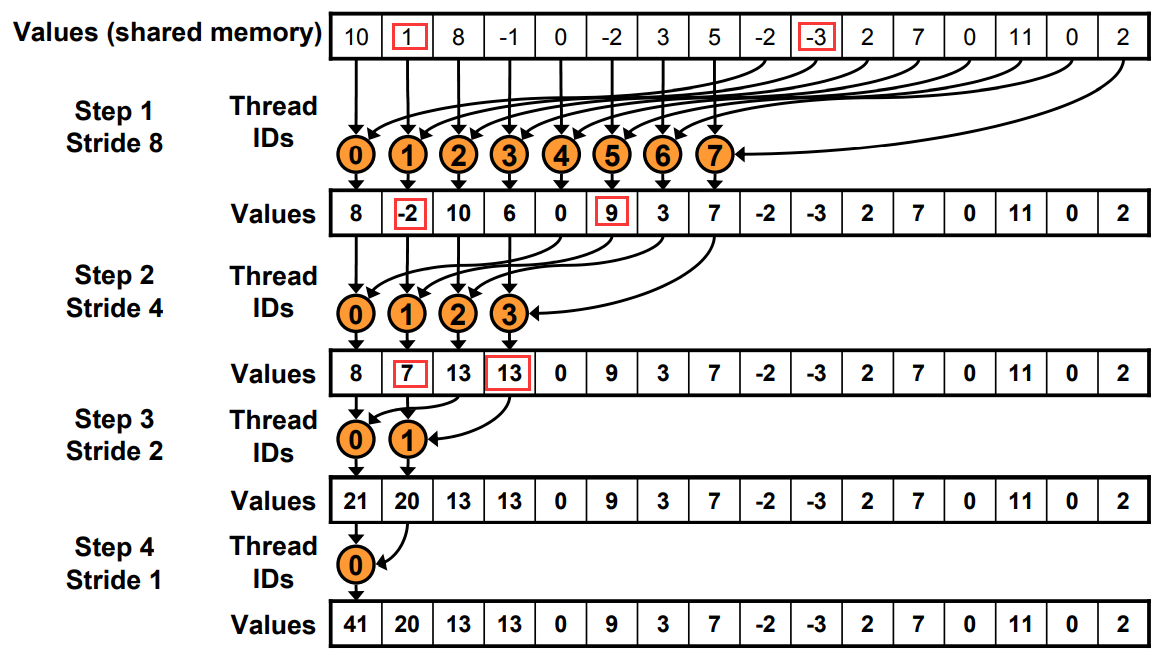
Step2: 连续寻址
1 2 3 4 5 6
for (unsignedint s=blockDim.x/2; s>0; s>>=1) { if (tid < s) { sdata[tid] += sdata[tid + s]; } __syncthreads(); }
// perform first level of reduction, // reading from global memory, writing to shared memory unsignedint tid = threadIdx.x; unsignedint i = blockIdx.x*(blockDim.x*2) + threadIdx.x; sdata[tid] = g_idata[i] + g_idata[i+blockDim.x]; __syncthreads();
Hugo is a Go-based static site generator known for its speed and flexibility in 2013.
Hugo has set itself apart by being fast. More precisely, it has set itself apart by being much faster than Jekyll.
Jekyll uses Liquid as its templating language. Hugo uses Go templating. Most people seem to agree that it is a little bit easier to learn Jekyll’s syntax than Hugo’s.^1
ctrl + alt + F3 #jump into command line login su - {user-name} sudo -s sudo -i # If invoked without a user name, su defaults to becoming the superuser ip a |less #check ip address fjw弄了静态IP就没这个问题了
限制当前shell用户爆内存
宕机一般是爆内存,进程分配肯定会注意不超过物理核个数。
在zshrc里写入 25*1024*1024 = 25GB的内存上限
1
ulimit -v 26214400
当前shell程序超内存,会输出Memory Error结束。
测试读取200GB大文件到内存
1 2 3
with open("/home/shaojiemike/test/DynamoRIO/OpenBLASRawAssembly/openblas_utest.log", 'r') as f: data= f.readlines() print(len(data))