AntiCheat
运行卡拉比丘时,报错 Anti-Cheat Expert (ACE)
1 | ACE安全中心 |
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
运行卡拉比丘时,报错 Anti-Cheat Expert (ACE)
1 | ACE安全中心 |
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
: to change mode?/ to search? to up search* to search cursor current word1 | :{作用范围}s/{目标字符}/{替换的字符}/{替换标志} |
1,3表示替换第一行至第三行,1,$表示替换第一行到最后一行,也可以直接用%表示。c: confirm,每次替换前都会询问 e:不显示error g: globe,不询问,整个替换 i: ignore,即不区分大小写:new[CTRL] [W] s[CTRL] [W] v:split [FILENAME] #或 :sp [FILENAME]:vsplit [FILENAME] #或 :vs [FILENAME]:only[CTRL] W o:q #或者: :quitsudo apt-get install exuberant-ctagsctags -R . /path/another/include will generate tags file1 | echo "set tags=$PWD/tags" >> ~/.vimrc |
1 | Ctrl + ] # forword |
huawei programming : dev machine 使用tmux和zsh可以实现统一的开发环境
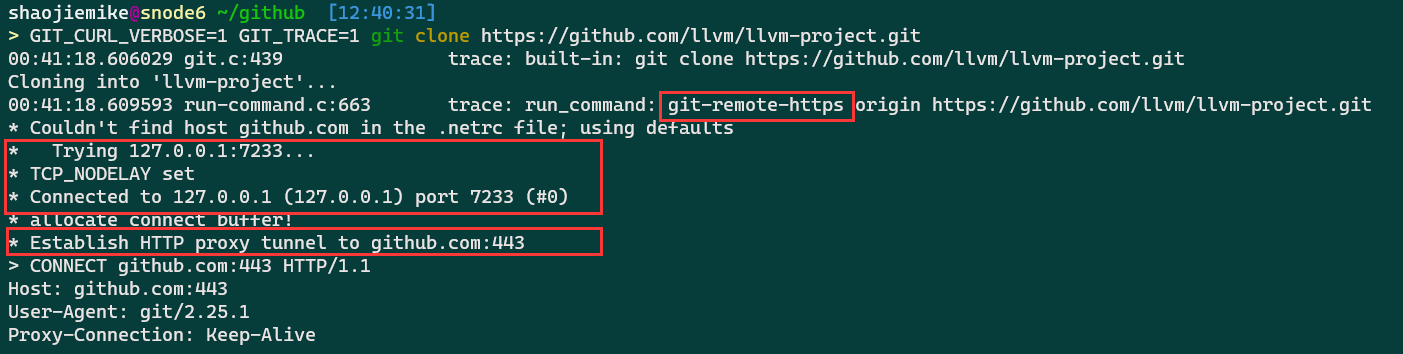
linux下通过按照如下修改.ssh/config设置账号密码,并 ssh -vT git@github.com,成功后输出Hi Kirrito-k423! You've successfully authenticated, but GitHub does not provide shell access.。
1 | # .ssh/config |
There are tons of identical solutions over the internet for defining proxy tunnel for git’s downloads like this one, which all is by setting git’s https.proxy & http.proxy config. but those answers are not working when you try to clone/push/pull etc. over the ssh protocol!
For example, by setting git config --global https.proxy socks5://127.0.0.1:9999 when you try to clone git clone git@github.org:user/repo.git it does not go through the defined sock5 tunnel!
1 | # Method 1. git http + proxy http |
%h %p 是host和post的意思
或者
After some visiting so many pages, I finally find the solution to my question:
1 | [step 1] create a ssh-proxy |
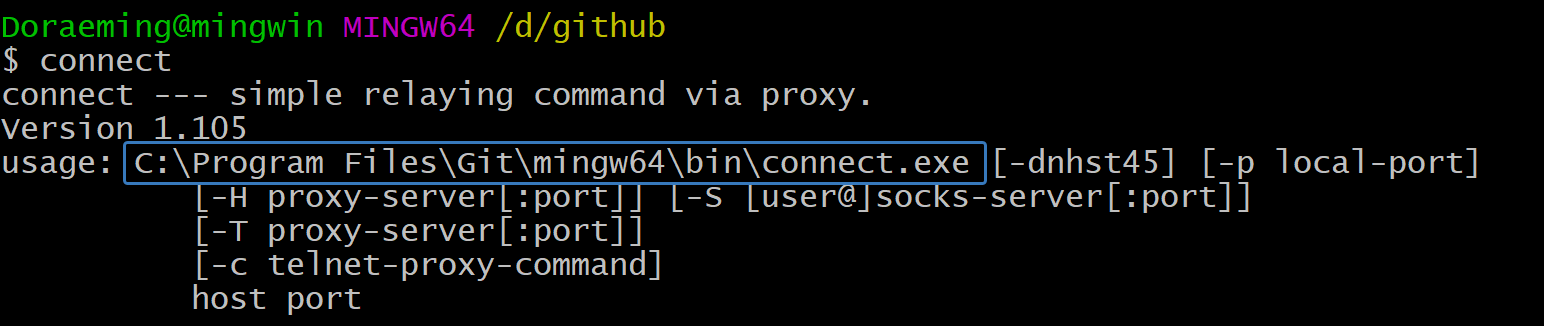
To install connect on Ubuntu:
1 | sudo apt install connect-proxy |
1 | ssh -vT -o "ProxyCommand connect -S 127.0.0.1:7890 %h %p" git@github.com |
post request forward is an all-in-one solution.
1 | interface: warp |
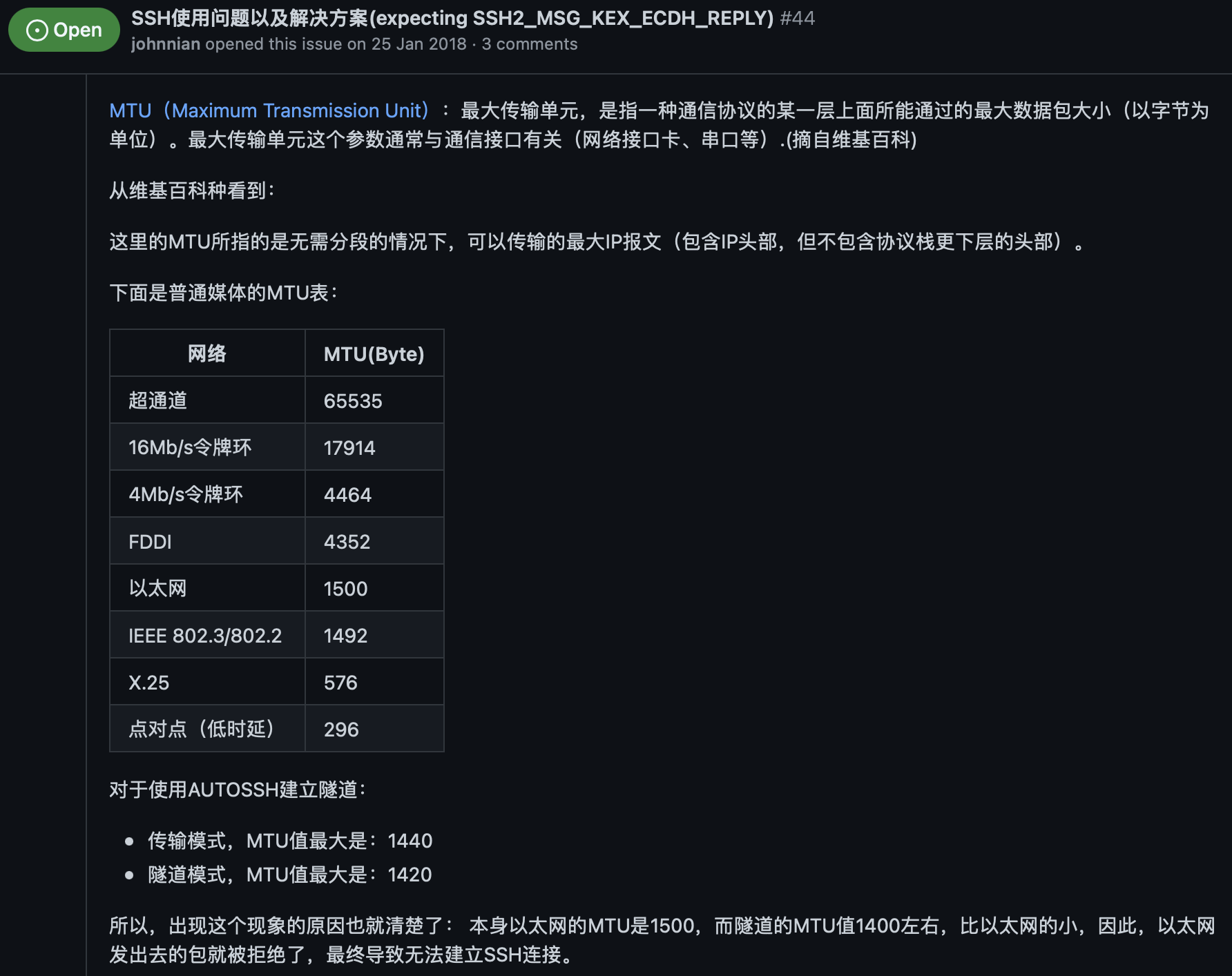
latest handshake: 89 days ago demonstrate wg is done for a long time. At the same time mtr github.com shows no output prove the bad situation.
STEP1: first try is to bring the wg-proxy up again
1 | python register.py #自动生成warp-op.conf,warp.conf和warp-helper |
and test brainiac machine is back online
Sometimes,it‘s the big log fault.
1 | # find file |
1 | t00906153@A2305023964 MINGW64 ~/github |
虽然MPI属于OSI参考模型的第5层和更高层,但实现可以覆盖大多数层,其中在传输层中使用套接字和传输控制协议(TCP)。
MPI hardware research focuses on implementing MPI directly in hardware, for example via processor-in-memory, building MPI operations into the microcircuitry of the RAM chips in each node. By implication, this approach is independent of language, operating system, and CPU, but cannot be readily updated or removed.
MPI硬件研究的重点是直接在硬件中实现MPI,例如通过内存处理器,将MPI操作构建到每个节点中的RAM芯片的微电路中。通过暗示,这种方法独立于语言、操作系统和CPU,但是不能容易地更新或删除。
Another approach has been to add hardware acceleration to one or more parts of the operation, including hardware processing of MPI queues and using RDMA to directly transfer data between memory and the network interface controller(NIC 网卡) without CPU or OS kernel intervention.
另一种方法是将硬件加速添加到操作的一个或多个部分,包括MPI队列的硬件处理以及使用RDMA在存储器和网络接口控制器之间直接传输数据,而无需CPU或OS内核干预。
进程间通信都是Inter-process communication(IPC)的一种。常见有如下几种:
|mkfifo,具有p的文件属性线程共享存储器编程模型(如Pthreads和OpenMP)和消息传递编程(MPI/PVM)可以被认为是互补的,并且有时在具有多个大型共享存储器节点的服务器中一起使用。
后四个是MPI-2独有的
1 | #include <unistd.h> |
输出X个当前机器hostname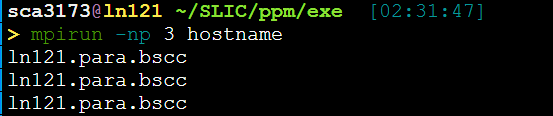
mpirun -np 6 -machinefile ./machinelist ./a.out 即可多节点执行。
MPI_Finalize()之后 ,MPI_Init()之前
https://www.open-mpi.org/doc/v4.0/man3/MPI_Init.3.php
不同的进程是怎么处理串行的部分的?都执行(重复执行?)。执行if(rank=num),那岂不是还要同步MPI_Barrier()。
而且写同一个文件怎么办?
MPI的两种最基本的并行程序设计模式 即对等模式和主从模式。
对等模式:各个部分地位相同,功能和代码基本一致,只不过是处理的数据或对象不同,也容易用同样的程序来实现。
主从模式:分为主进程和从进程,程序通信进程之间的一种主从或依赖关系 。MPI程序包括两套代码,主进程运行其中一套代码,从进程运行另一套代码。
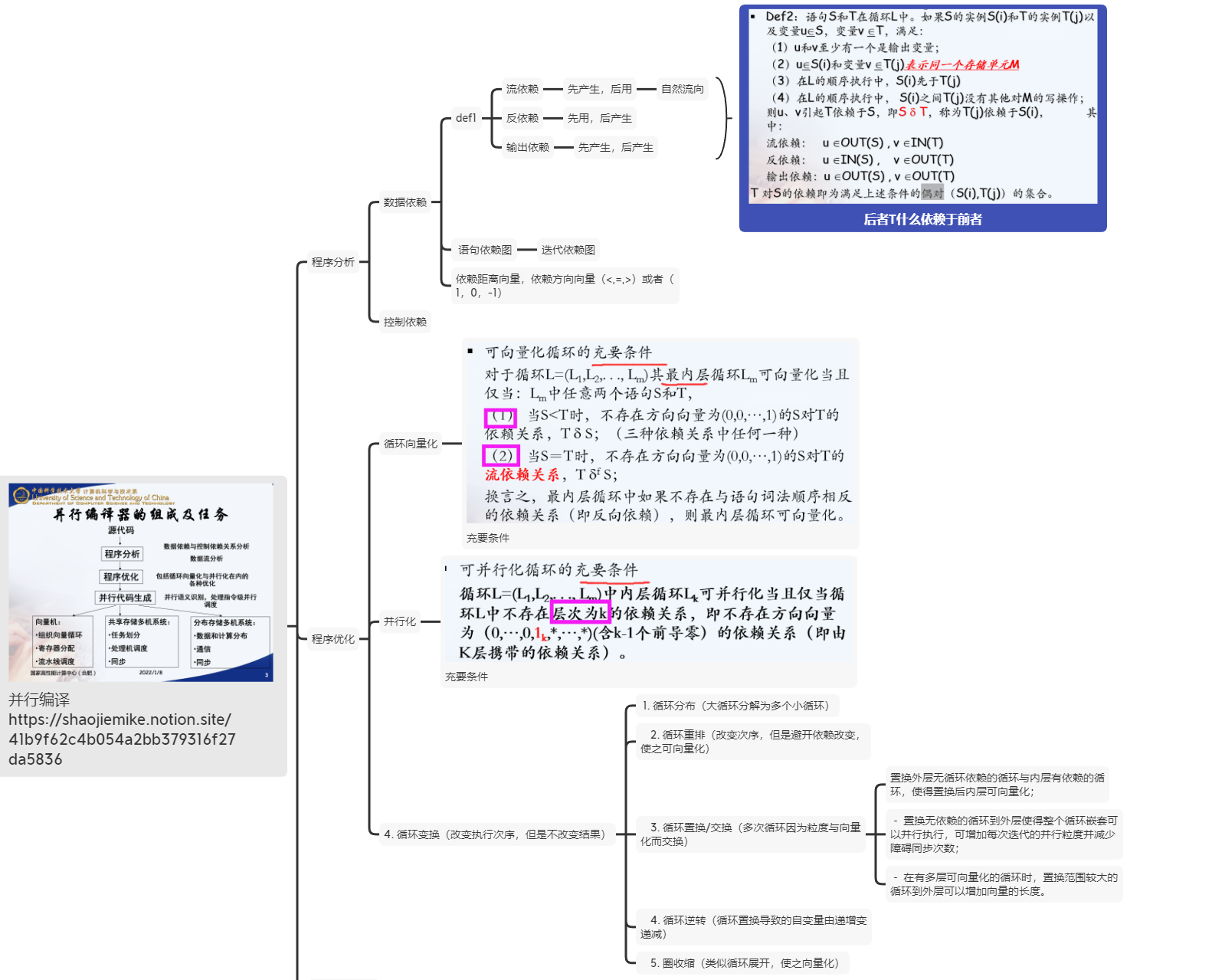
圈收缩(cycle shrinking)-此变换技术一般用于依赖距离大于1的循环中,它将一个串行循环分成两个紧嵌套循环,其中外层依然串行执行,而内层则是并行执行(一般粒度较小)
https://shaojiemike.notion.site/41b9f62c4b054a2bb379316f27da5836

MPI_PACKED预定义数据类型被用来实现传输地址空间不连续的数据项 。
1 | int MPI_Pack(const void *inbuf, |

The input value of position is the first location in the output buffer to be used for packing. position is incremented by the size of the packed message,
and the output value of position is the first location in the output buffer following the locations occupied by the packed message. The comm argument is the communicator that will be subsequently used for sending the packed message.
1 | //Returns the upper bound on the amount of space needed to pack a message |

例子:
这里的A+i*j应该写成A+i*2吧???
来定义由数据类型不同且地址空间不连续的数据项组成的消息。
1 | //启用与弃用数据类型 |

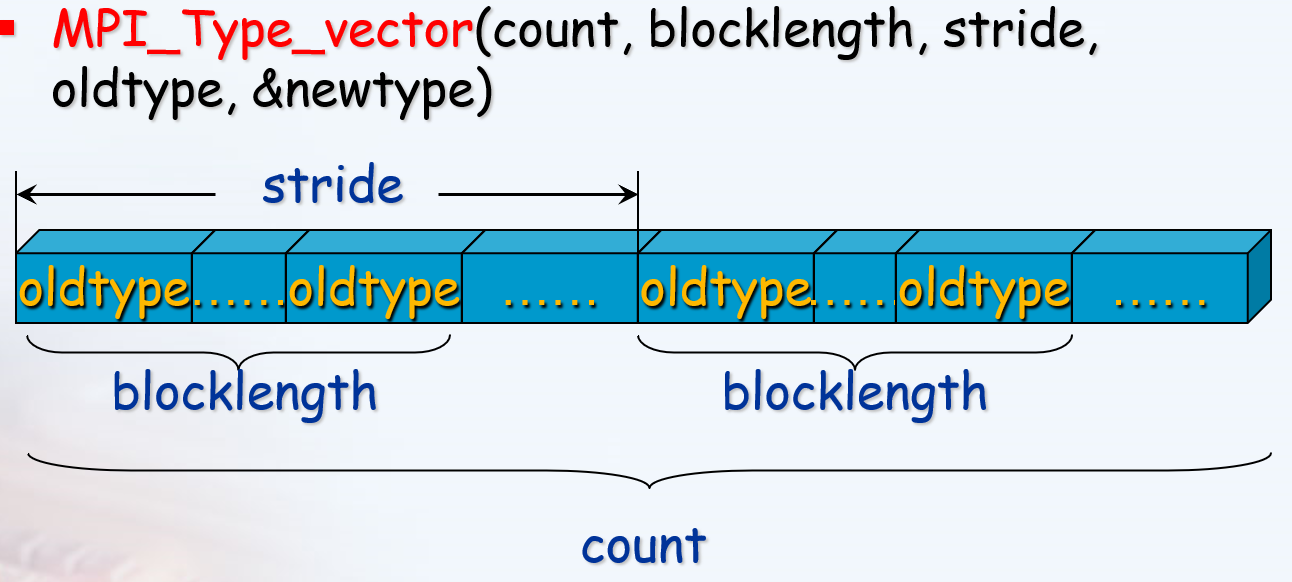
1 | //成块的相同元素组成的类型,块长度和偏移由参数指定 |

1 | //由不同数据类型的元素组成的类型, 块长度和偏移(肯定也不一样)由参数指定 |

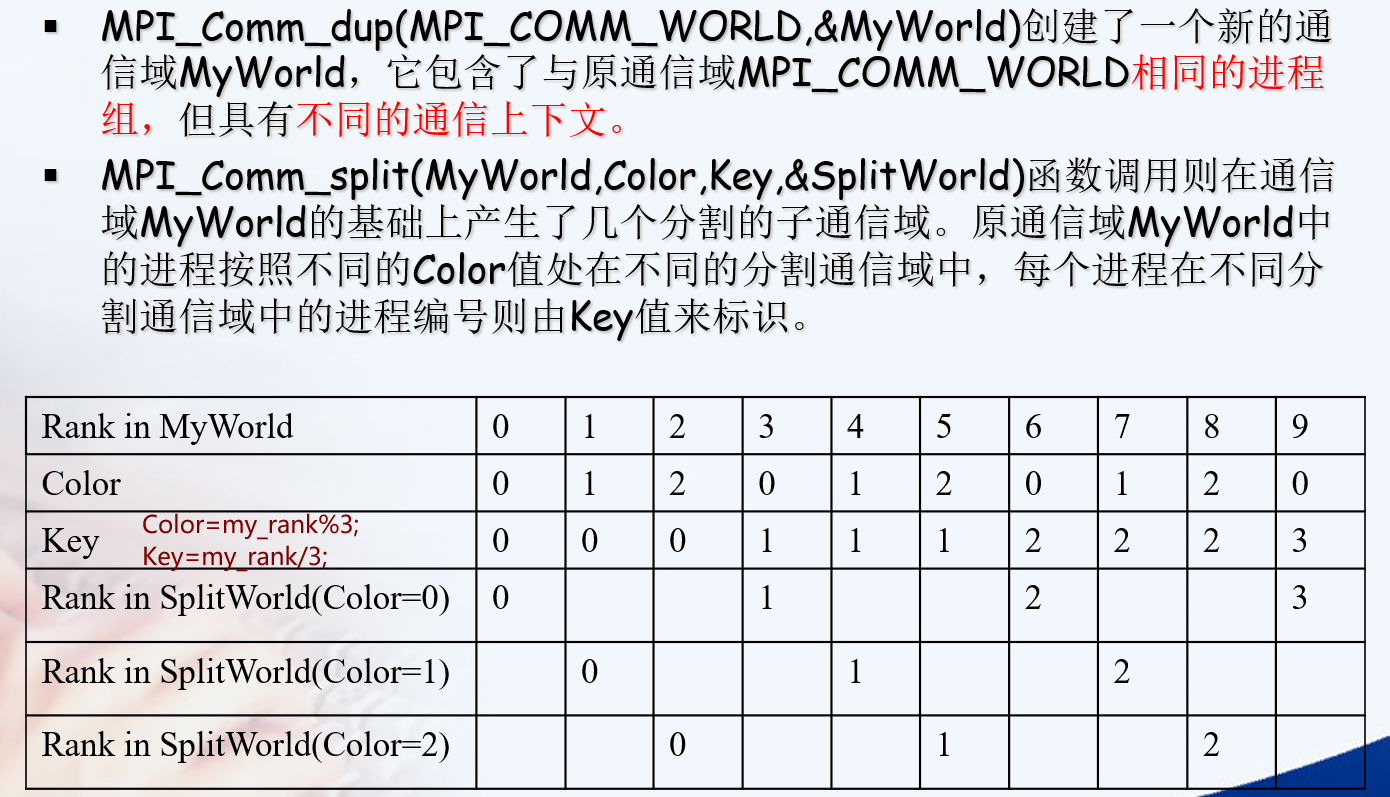
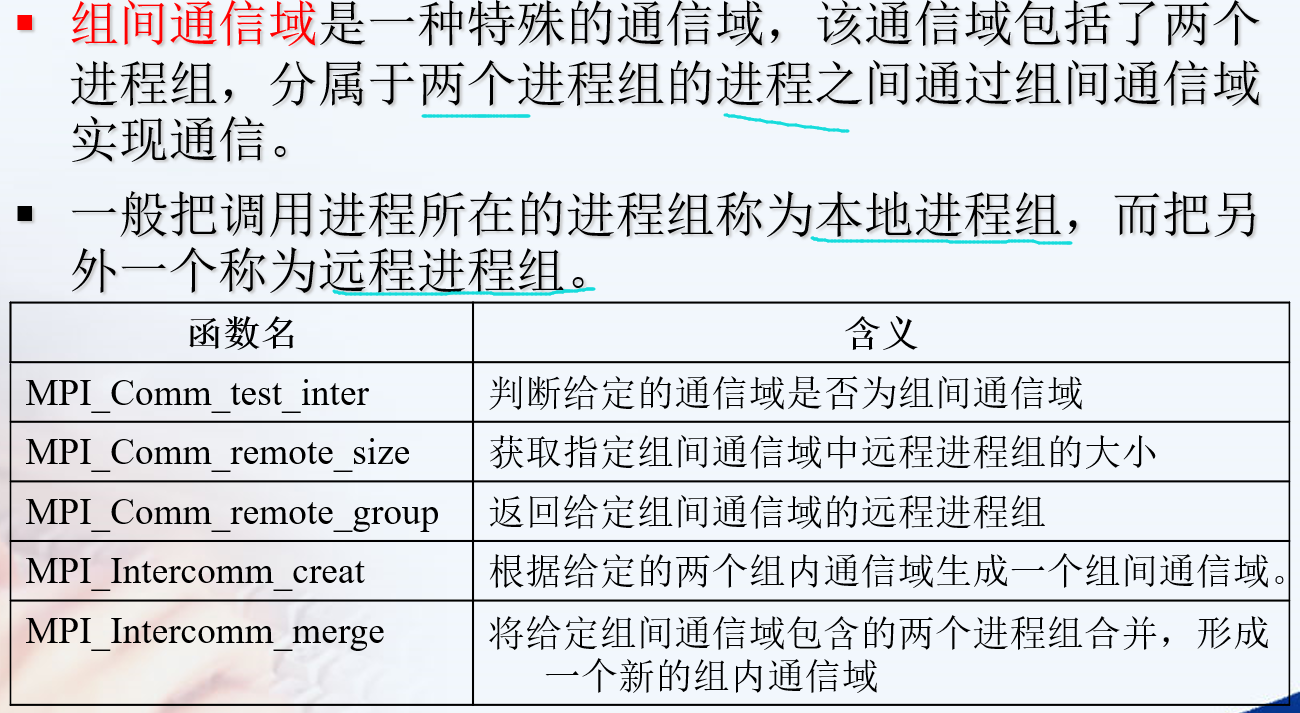
MPI_Cart_create
确定了虚拟网络每一维度的大小后,需要为这种拓扑建立通信域。组函数MPI_Cart_create可以完成此任务,其声明如下:
1 | // Makes a new communicator to which topology拓扑 information has been attached |
1 | int MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm * newcomm) |
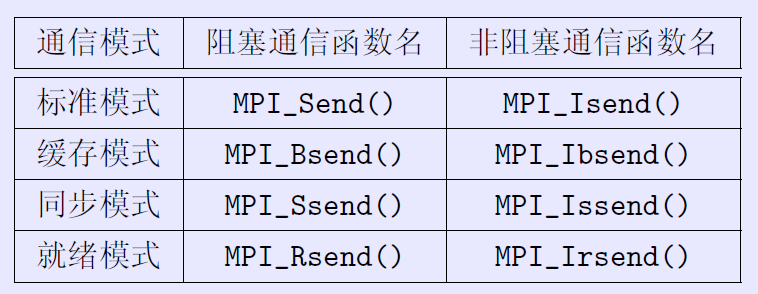
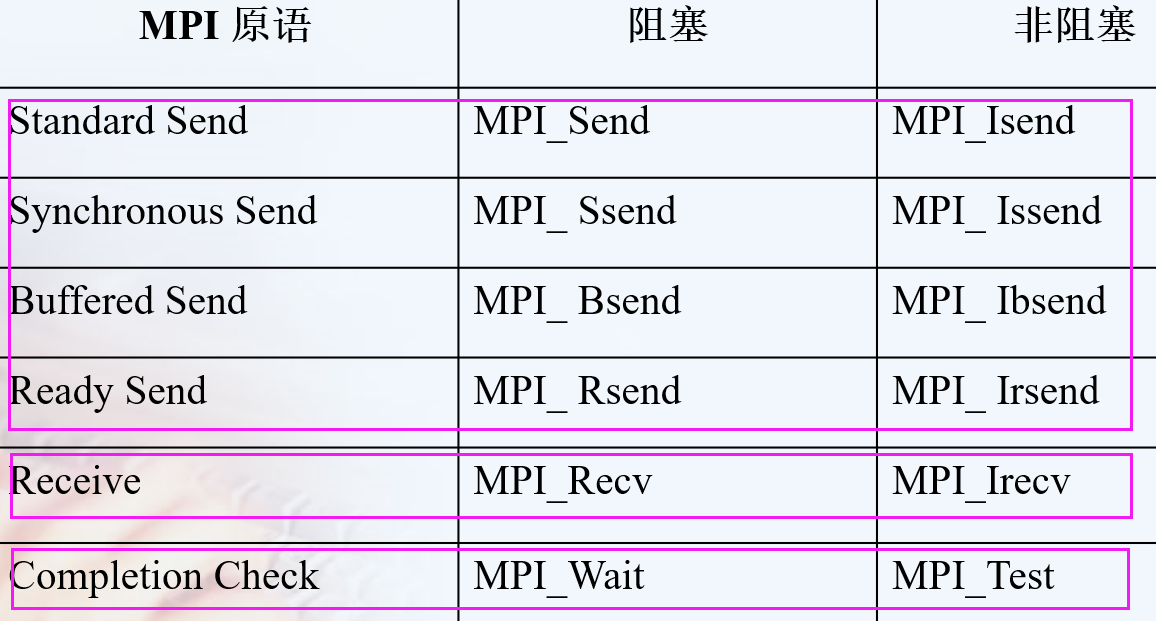
特殊的函数
1 | int MPI_Sendrecv(const void *sendbuf, int sendcount, MPI_Datatype sendtype, |
特别适用于在进程链(环)中进行“移位”操作,而避免在通讯为阻塞方式时出现死锁。
There is also another error. The MPI standard requires that the send and the receive buffers be disjoint不相交 (i.e. they should not overlap重叠), which is not the case with your code. Your send and receive buffers not only overlap but they are one and the same buffer. If you want to perform the swap in the same buffer, MPI provides the MPI_Sendrecv_replace operation.
1 | //MPI标准阻塞通信函数,没发出去就不会结束该命令。 |

可能大家会想到这会死锁,如下图:
但是实际情况可能并不会死锁,这与调用的MPI库的底层实现有关。

MPI_Send将阻塞,直到发送方可以重用发送方缓冲区为止。当缓冲区已发送到较低的通信层时,某些实现将返回给调用方。当另一端有匹配的MPI_Recv()时,其他一些将返回到呼叫者。
但是为了避免这种情况,可以调换Send与Recv的顺序,或者**使用MPI_Isend()或MPI_Issend()**代替非阻塞发送,从而避免死锁。
1 | /* |
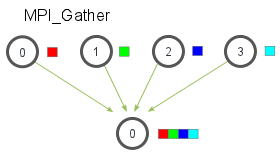
一个进程组中的所有进程都参加的全局通信操作。
实现三个功能:通信、聚集和同步。
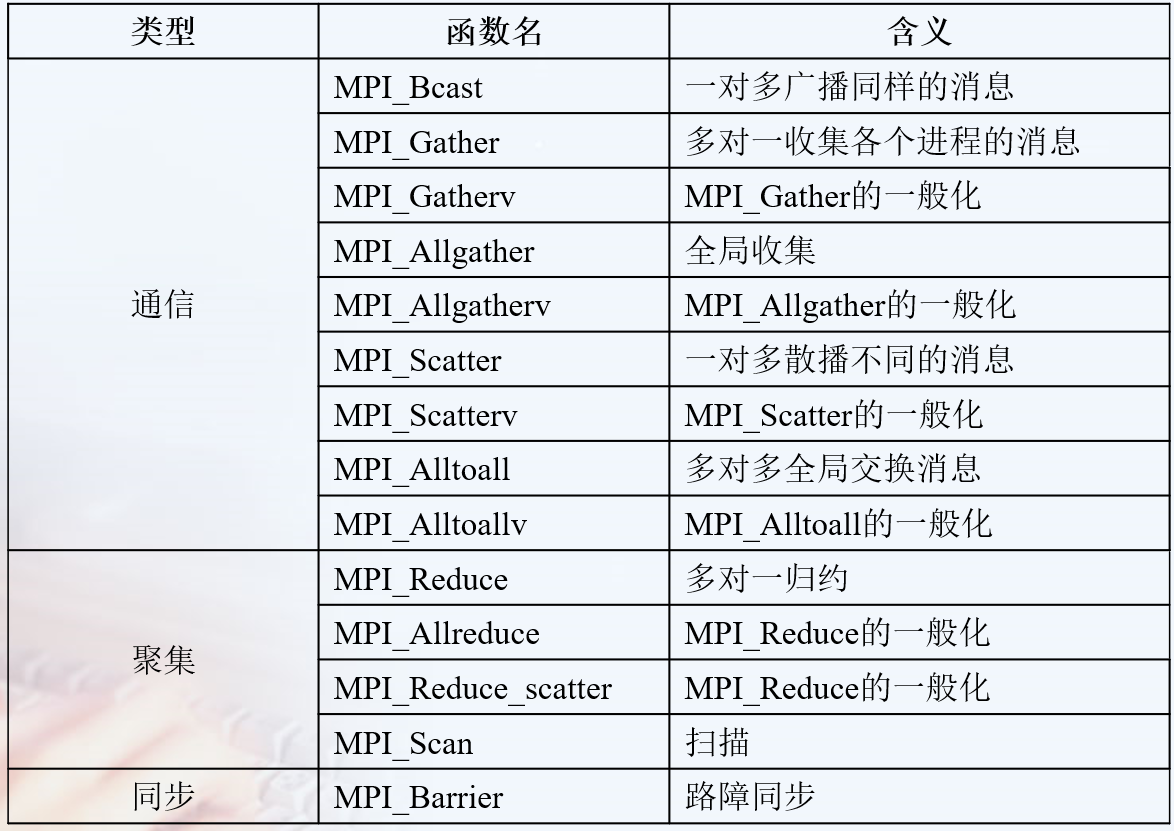
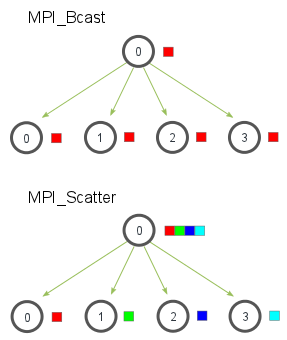
1 | //将一个进程中得数据发送到所有进程中的广播函数 |
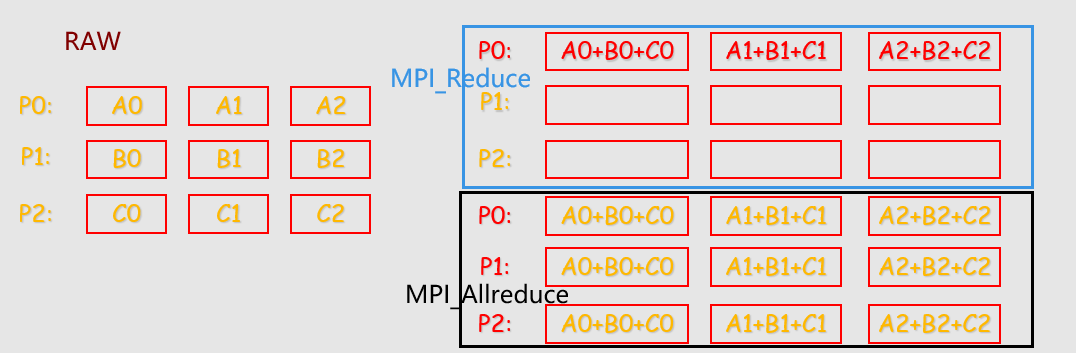
注意data_p在root 或者scr_process进程里是发送缓存也是接收缓存,但是在其余进程里是接收缓存。
MPI_Scatter?
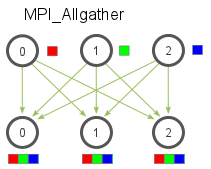
1 | int MPI_Allgather(void * sendbuff, int sendcount, MPI_Datatype sendtype, |
number of elements received from any process (integer)
MPI聚合的功能分三步实现
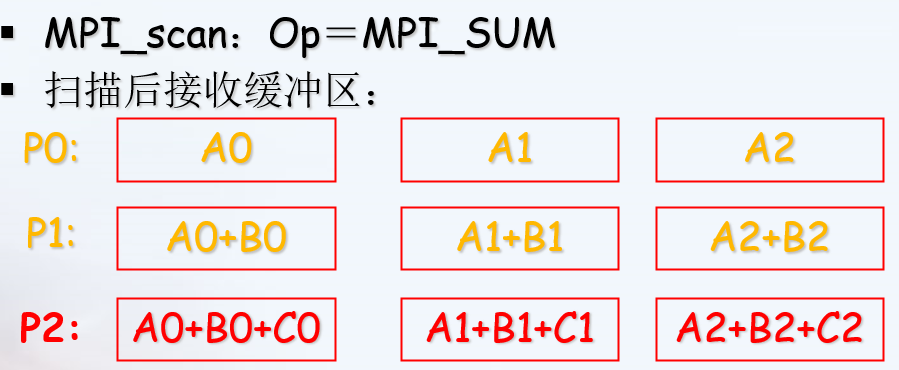
MPI提供了两种类型的聚合操作: 归约和扫描。
1 | int MPI_Reduce( |
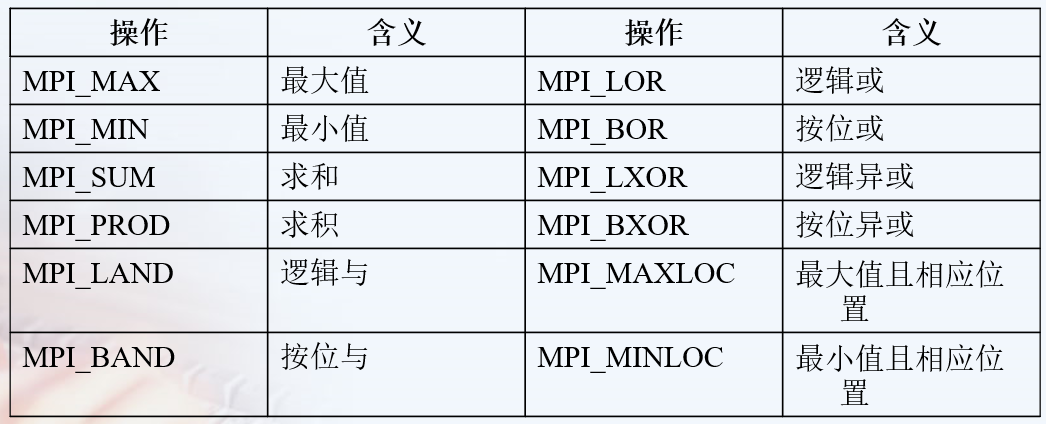
1 | int MPI_Op_create(MPI_User_function *function, int commute, MPI_Op *op) |
用户自定义函数 functiontypedef void MPI_User_function(void *invec, void *inoutvec, int *len, MPI_Datatype *datatype)
1 | for(i=0;i<*len;i++) { |
必须具备四个参数:
也可以认为invec和inoutvec 是函数中长度为len的数组, 归约的结果重写了inoutvec 的值。
1 | /* |
MPI_Group https://www.rookiehpc.com/mpi/docs/mpi_group.php
并行IO文件
1997年推出了MPI的最新版本MPI-2
MPI-2加入了许多新特性,主要包括
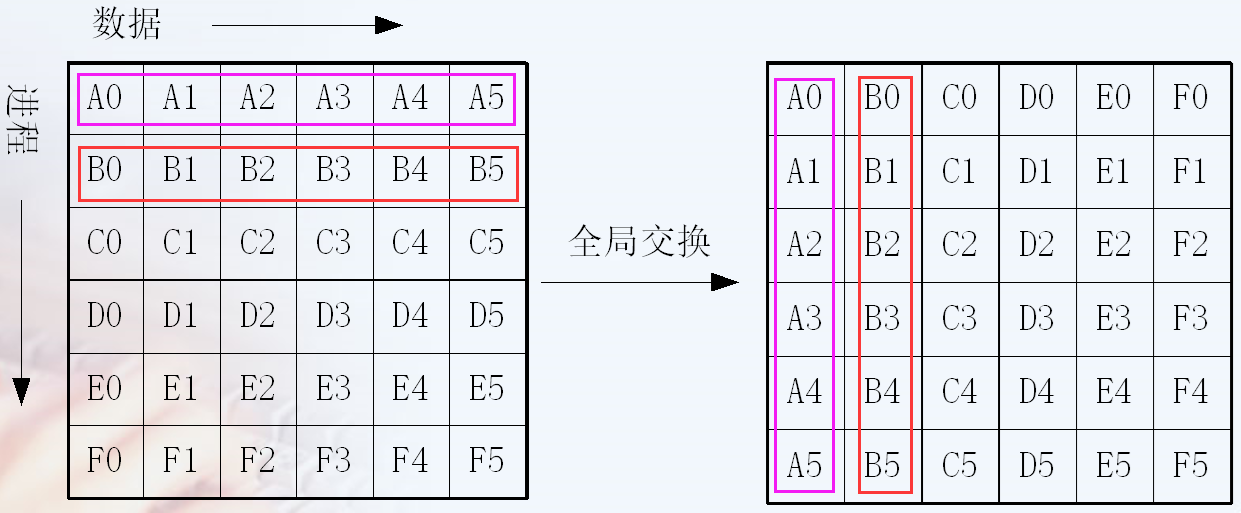
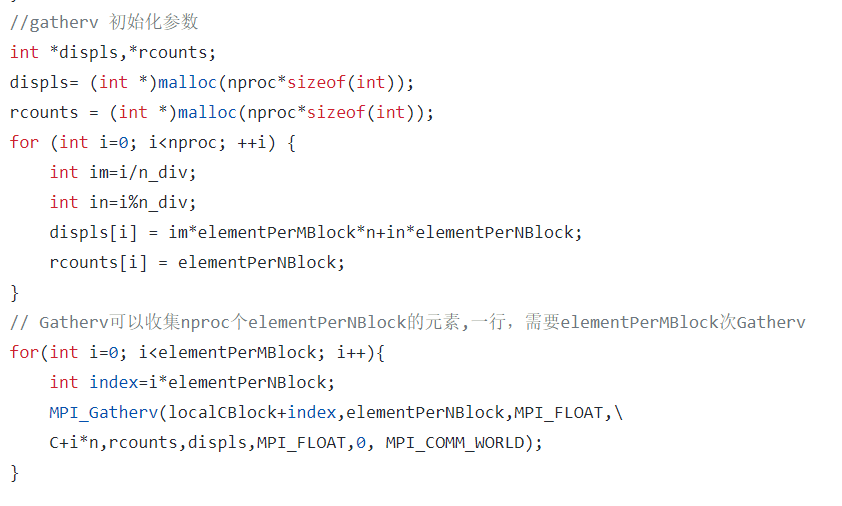
数据发送和收集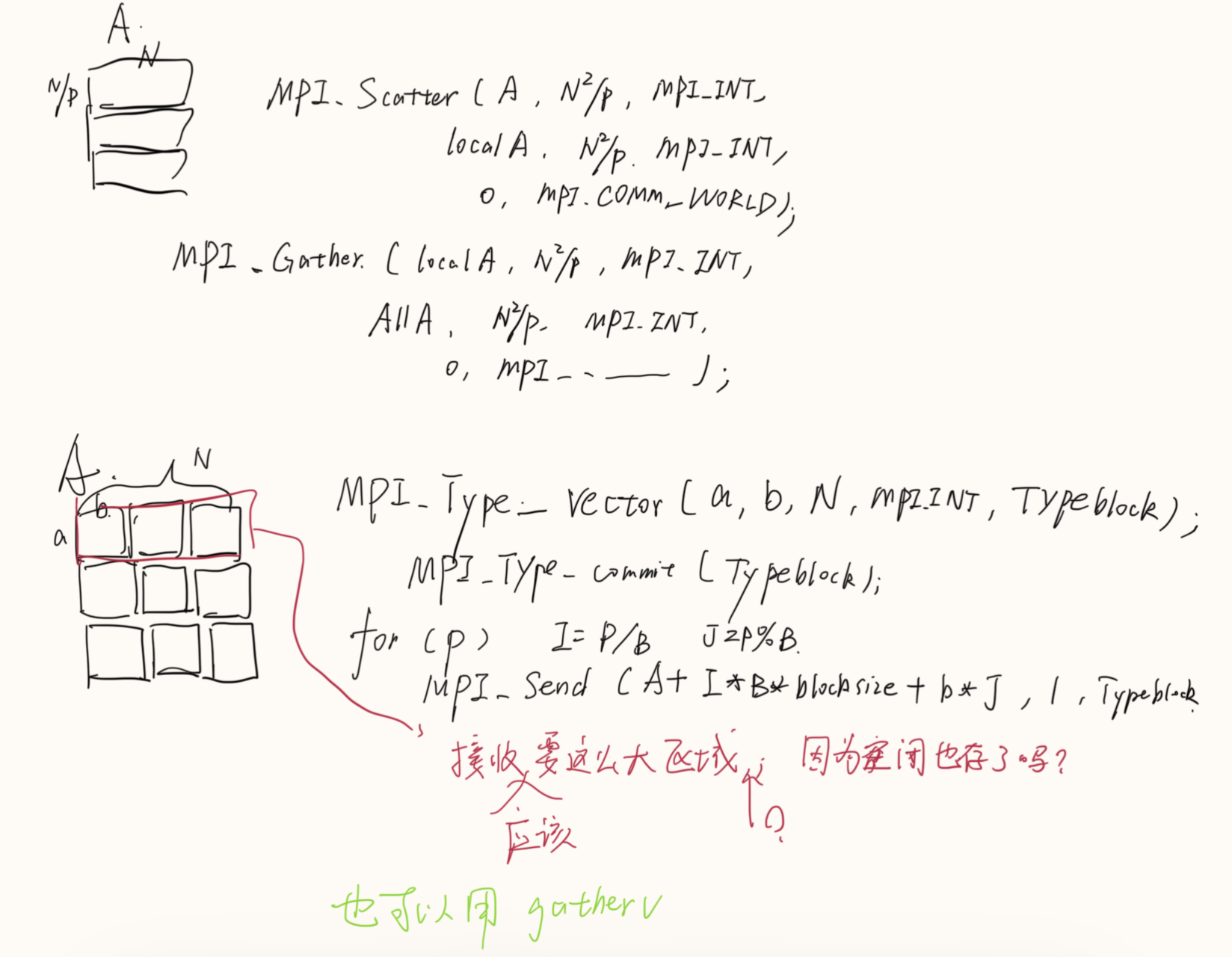
https://blog.csdn.net/susan_wang1/article/details/50033823
https://blog.csdn.net/u012417189/article/details/25798705
是否死锁: https://stackoverflow.com/questions/20448283/deadlock-with-mpi
https://mpitutorial.com/tutorials/
http://staff.ustc.edu.cn/~qlzheng/pp11/ 第5讲写得特别详细
Disk C: make room for installation
C 盘没空间了,啊啊啊~
It’s a fucking crazy thing when you reuse a Bluetooth device, because forget how to make pair.
My keyboard encounter Poor contact of keyboard keys, esepeacially the ctrl
iOS fn + i
Mac OS X fn + o
Windows fn + p
Read more: official ref and ref_photo
It seems that just
you can Turn on the Bluetooth.
连接蓝牙方法:(我们键盘没有送蓝牙适配器)需要您电脑有蓝牙功能,
Windows weird option 输入 FC980MBT 的PIN,也可以选择关闭,尤其是鼠标也需要输入时:
00000 using original keyboard,click confirm.00000 using new keyboard, enter.暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无