Read more
导言
大语言模型、多模态模型是如何设计来实现高效Mem机制。
导言
Step-3-VL 10B
导言
大语言模型、多模态模型是如何设计来实现高效Mem机制。
World Model/UFMs/Omni-Modal: AR vs DiT
导言
视觉领域的GPT moment要来了吗?[^4]
当前多模态设计中AR和DiT的组合关系,单独学习一下
Ideas around Vision-Language Models (VLMs) / Reasoning Models
导言
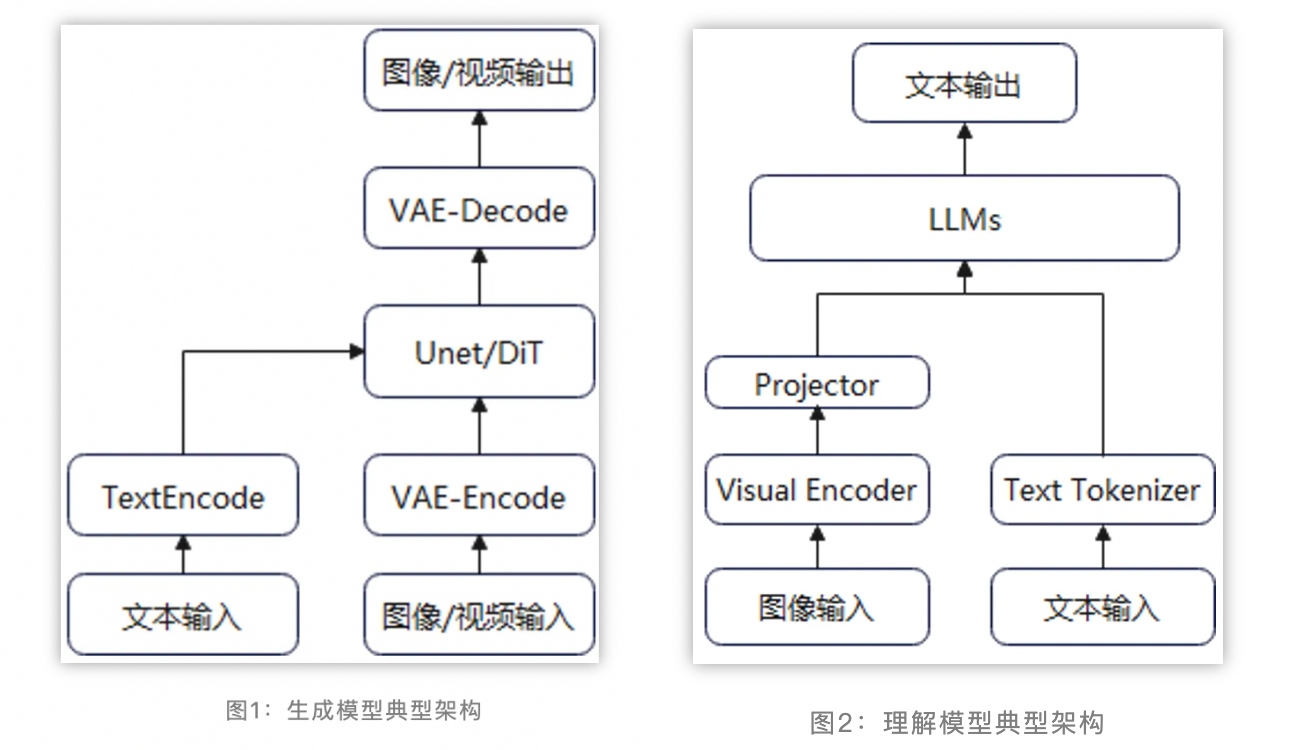
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。
排行榜:
250217 Step-Video-T2V Reading & Porting
导言
阅读Step-Video-T2V代码(git id d3ca3d6),移植到昇腾。
导言
当前主流的多模态生成模型(如图像生成text2image和视频生成text2video)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
排行榜: (T2I, ImageEdit, T2V, I2V, )
当前主流的多模态生成模型(如图像生成和视频生成)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。