Ideas around Vision-Language Models (VLMs) / Reasoning Models
Read more
Ideas around Vision-Language Models (VLMs) / Reasoning Models
导言
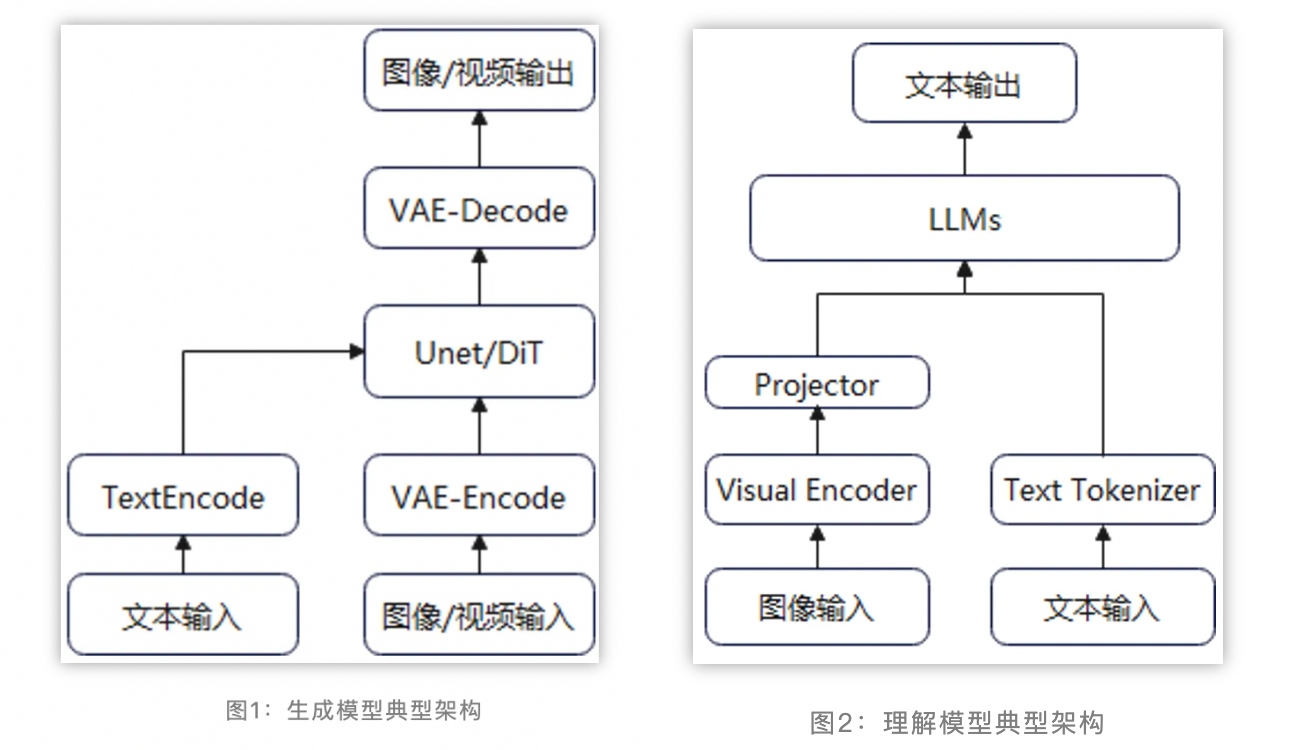
当前主流的多模态理解模型一般采用视觉编码器 + 模态对齐 + LLM的算法流程,充分复用已有视觉编码器的理解能力和LLM的基础能力。训练过程一般分为多个阶段,如先进行模态对齐的一阶段预训练,然后进行二阶段的参数微调。
排行榜: