The Mechanics of RL: How Inference Sampling Shapes the Probability Landscape
Read more
The Mechanics of RL: How Inference Sampling Shapes the Probability Landscape
导言
推理采样如何重塑概率地图:在普通监督学习(SFT)中,模型是被“喂饭”——你告诉它正确答案是什么,它去模仿。而在强化学习(RL)中,模型是在“试错”——它自己写几个答案,然后根据好坏来调整自己。
导言
DiffusionNFT 直接在前向加噪过程(forward process)上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。在GenEval任务上,DiffusionNFT仅用约1.7k步就达到0.94分,而对比方法FlowGRPO需要超过5k步且依赖CFG才达到0.95分。这表明DiffusionNFT的训练效率比FlowGRPO快约25倍。
导言
VeRL 作为RL领域趋势最火的开源仓,值得学习。
导言
VeRL 基于ray的多进程管理,并结合 推理、训练等多个阶段。其E2E时间组成和如何加速都是待研究的课题。
Train Stages: Pretrain, Mid-Train(CT), SFT, RL
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
RL Algorithms: PPO-RLHF & GRPO-family
导言
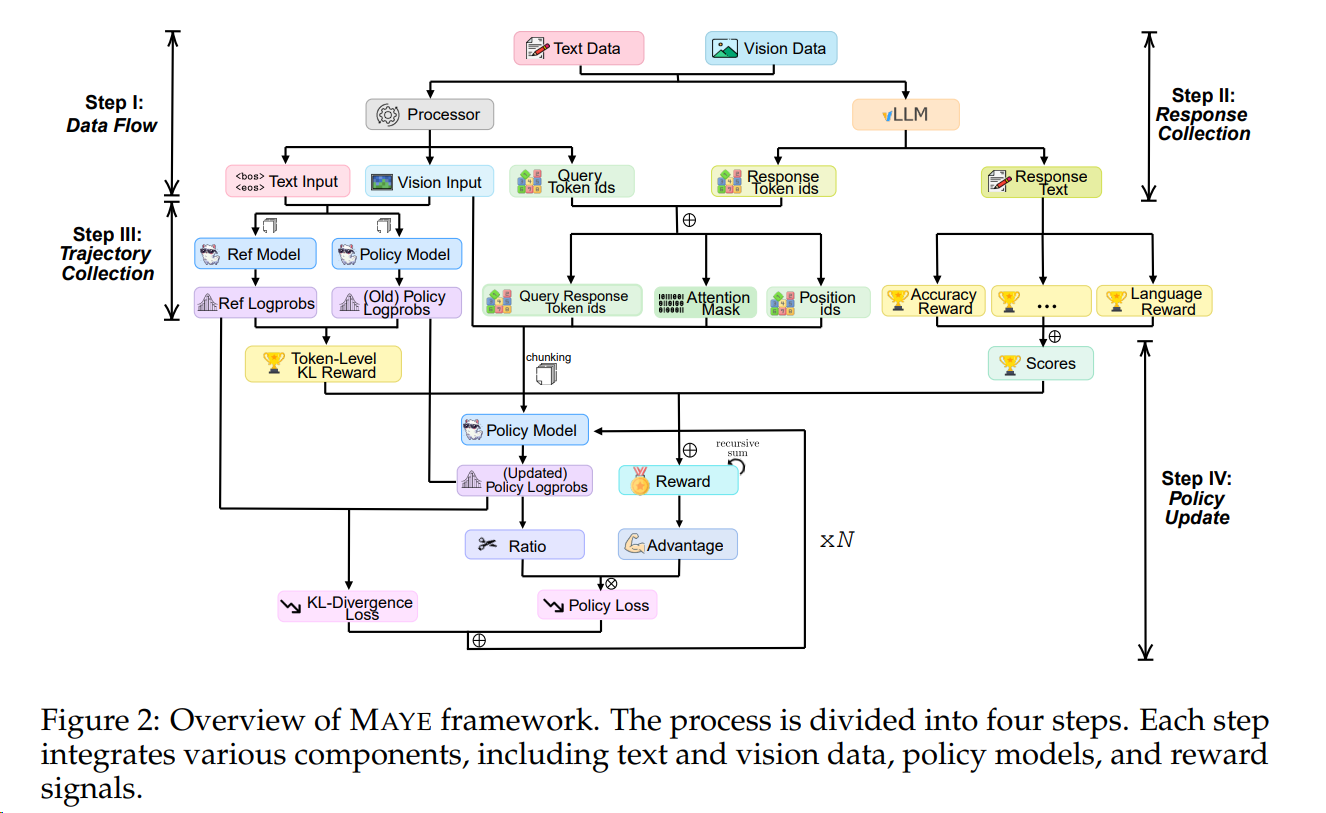 [^1]
[^1]
必看好文[^2]
导言
Bridging the Gap: Challenges and Trends in Multimodal RL.
导言
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
导言
在LLM对齐的早期探索中,研究者们建立了两种影响深远的基础范式。
鉴于PPO-RLHF的复杂性,研究者们开始寻求更简洁、更直接的对齐方法。直接偏好优化(Direct Preference Optimization, DPO)应运而生,它巧妙地绕过了显式的奖励建模和复杂的RL优化循环,为偏好对齐提供了一个优雅的替代方案。
这篇文章介绍DPO, 和Step-Video论文介绍了Video-DPO, 这类训练中最后通过人工标注优化的方法。
必看好文[^7]