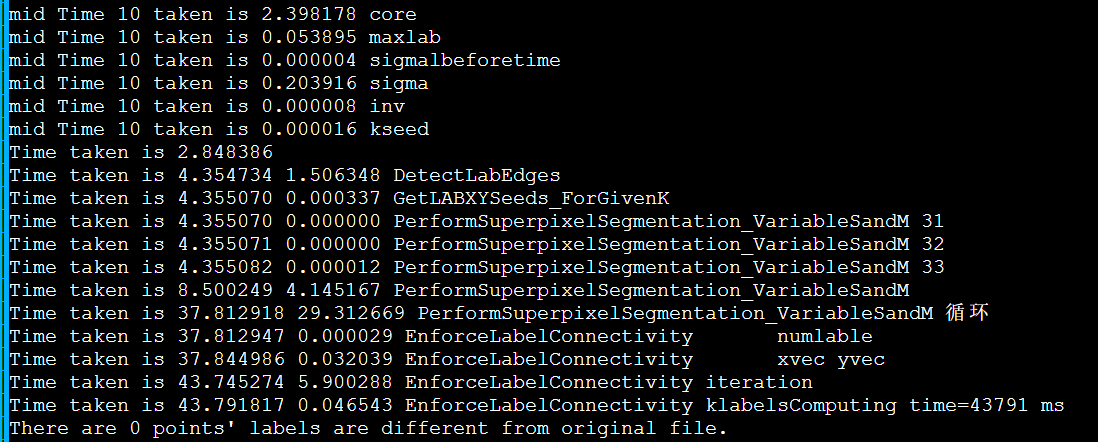
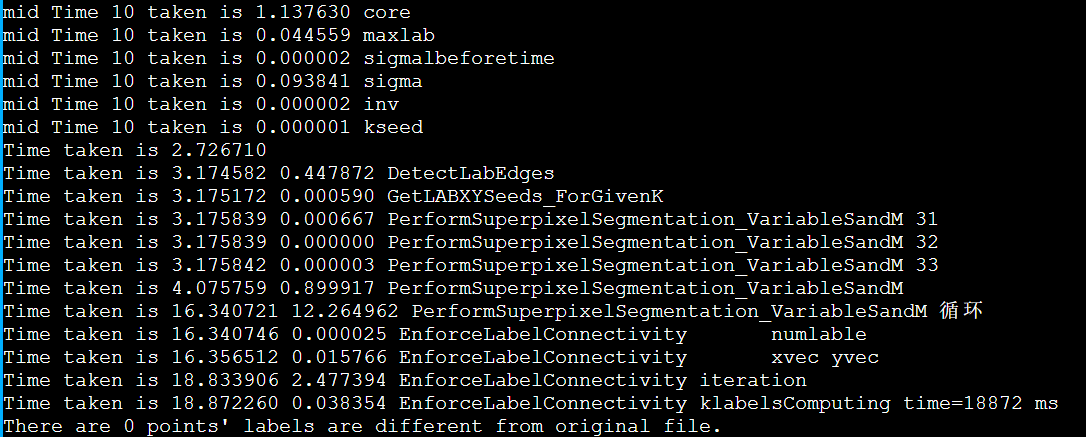
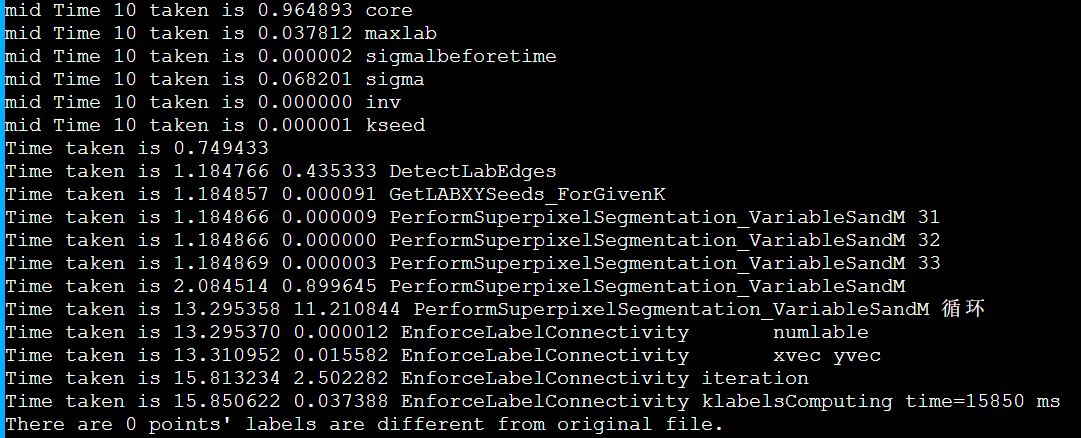
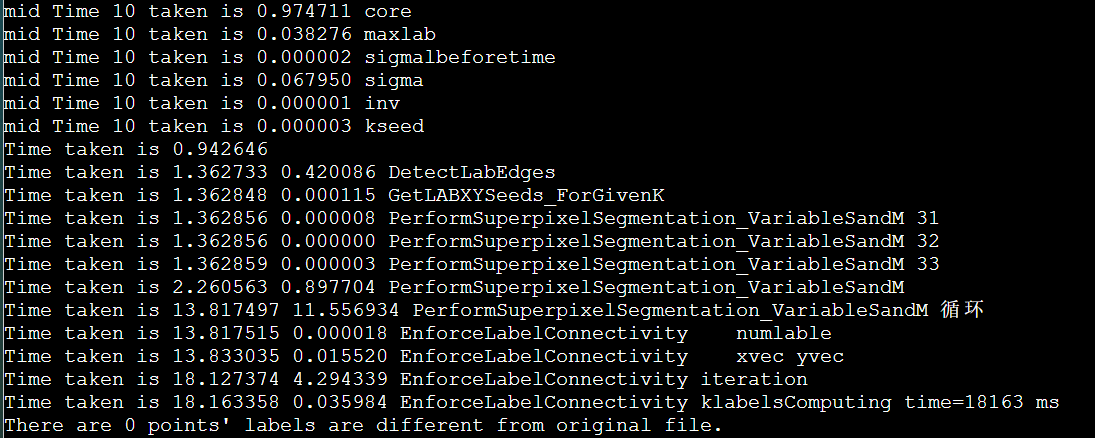
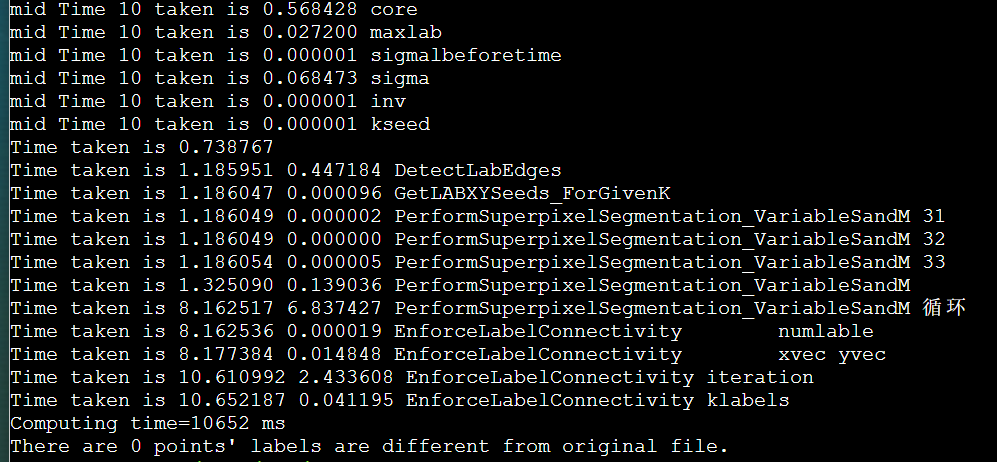
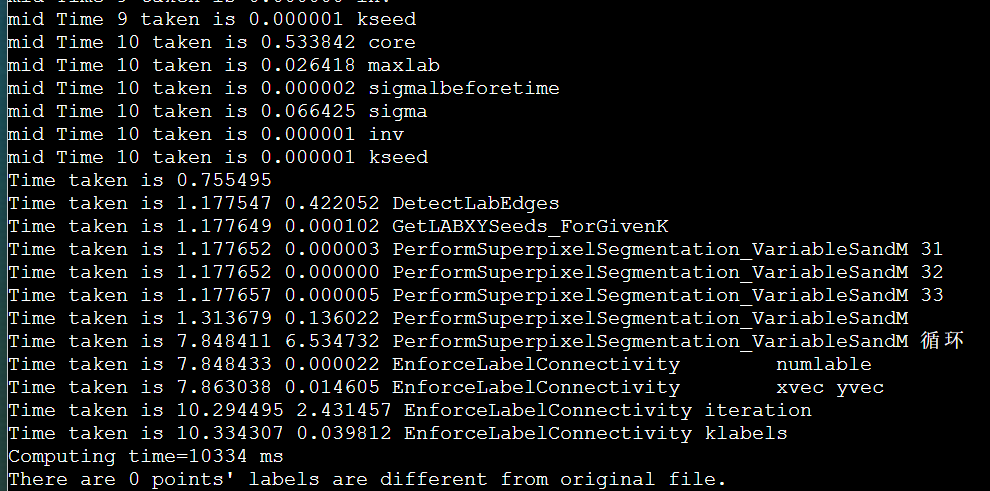
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
| Iterations: 100
Instructions: 200
Total Cycles: 70
Total uOps: 200
Dispatch Width: 4
uOps Per Cycle: 2.86
IPC: 2.86
Block RThroughput: 0.5
No resource or data dependency bottlenecks discovered.
Instruction Info:
[1]: #uOps
[2]: Latency
[3]: RThroughput
[4]: MayLoad
[5]: MayStore
[6]: HasSideEffects (U)
[7]: Encoding Size
[1] [2] [3] [4] [5] [6] [7] Encodings: Instructions:
1 1 0.33 4 20 00 80 52 mov w0, #1
1 1 0.50 U 4 c0 03 5f d6 ret
Dynamic Dispatch Stall Cycles:
RAT - Register unavailable: 0
RCU - Retire tokens unavailable: 0
SCHEDQ - Scheduler full: 0
LQ - Load queue full: 0
SQ - Store queue full: 0
GROUP - Static restrictions on the dispatch group: 0
Dispatch Logic - number of cycles where we saw N micro opcodes dispatched:
[# dispatched], [# cycles]
0, 20 (28.6%)
4, 50 (71.4%)
Schedulers - number of cycles where we saw N micro opcodes issued:
[# issued], [# cycles]
0, 3 (4.3%)
2, 1 (1.4%)
3, 66 (94.3%)
Scheduler's queue usage:
No scheduler resources used.
Retire Control Unit - number of cycles where we saw N instructions retired:
[# retired], [# cycles]
0, 3 (4.3%)
2, 1 (1.4%)
3, 66 (94.3%)
Total ROB Entries: 128
Max Used ROB Entries: 59 ( 46.1% )
Average Used ROB Entries per cy: 32 ( 25.0% )
Register File statistics:
Total number of mappings created: 100
Max number of mappings used: 29
Resources:
[0.0] - TSV110UnitAB
[0.1] - TSV110UnitAB
[1] - TSV110UnitALU
[2] - TSV110UnitFSU1
[3] - TSV110UnitFSU2
[4.0] - TSV110UnitLdSt
[4.1] - TSV110UnitLdSt
[5] - TSV110UnitMDU
Resource pressure per iteration:
[0.0] [0.1] [1] [2] [3] [4.0] [4.1] [5]
0.66 0.67 0.67 - - - - -
Resource pressure by instruction:
[0.0] [0.1] [1] [2] [3] [4.0] [4.1] [5] Instructions:
0.33 - 0.67 - - - - - mov w0, #1
0.33 0.67 - - - - - - ret
Timeline view:
Index 0123456789
[0,0] DeER . . mov w0, #1
[0,1] DeER . . ret
[1,0] DeER . . mov w0, #1
[1,1] D=eER. . ret
[2,0] .DeER. . mov w0, #1
[2,1] .DeER. . ret
[3,0] .D=eER . mov w0, #1
[3,1] .D=eER . ret
[4,0] . DeER . mov w0, #1
[4,1] . D=eER . ret
[5,0] . D=eER . mov w0, #1
[5,1] . D=eER . ret
[6,0] . D=eER . mov w0, #1
[6,1] . D=eER . ret
[7,0] . D=eER . mov w0, #1
[7,1] . D==eER. ret
[8,0] . D=eER. mov w0, #1
[8,1] . D=eER. ret
[9,0] . D==eER mov w0, #1
[9,1] . D==eER ret
Average Wait times (based on the timeline view):
[0]: Executions
[1]: Average time spent waiting in a scheduler's queue
[2]: Average time spent waiting in a scheduler's queue while ready
[3]: Average time elapsed from WB until retire stage
[0] [1] [2] [3]
0. 10 1.7 1.7 0.0 mov w0, #1
1. 10 2.0 2.0 0.0 ret
10 1.9 1.9 0.0 <total>
|