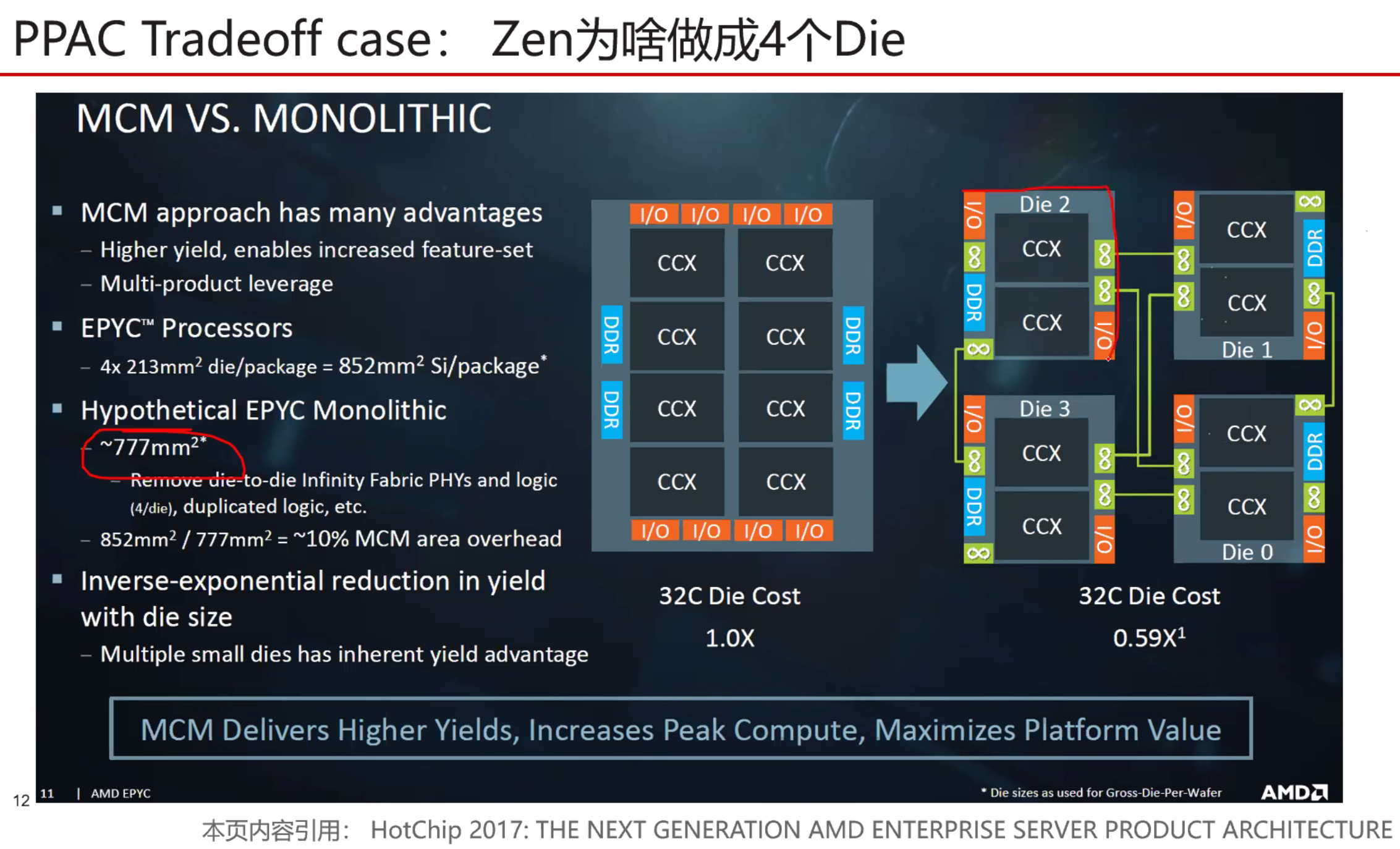
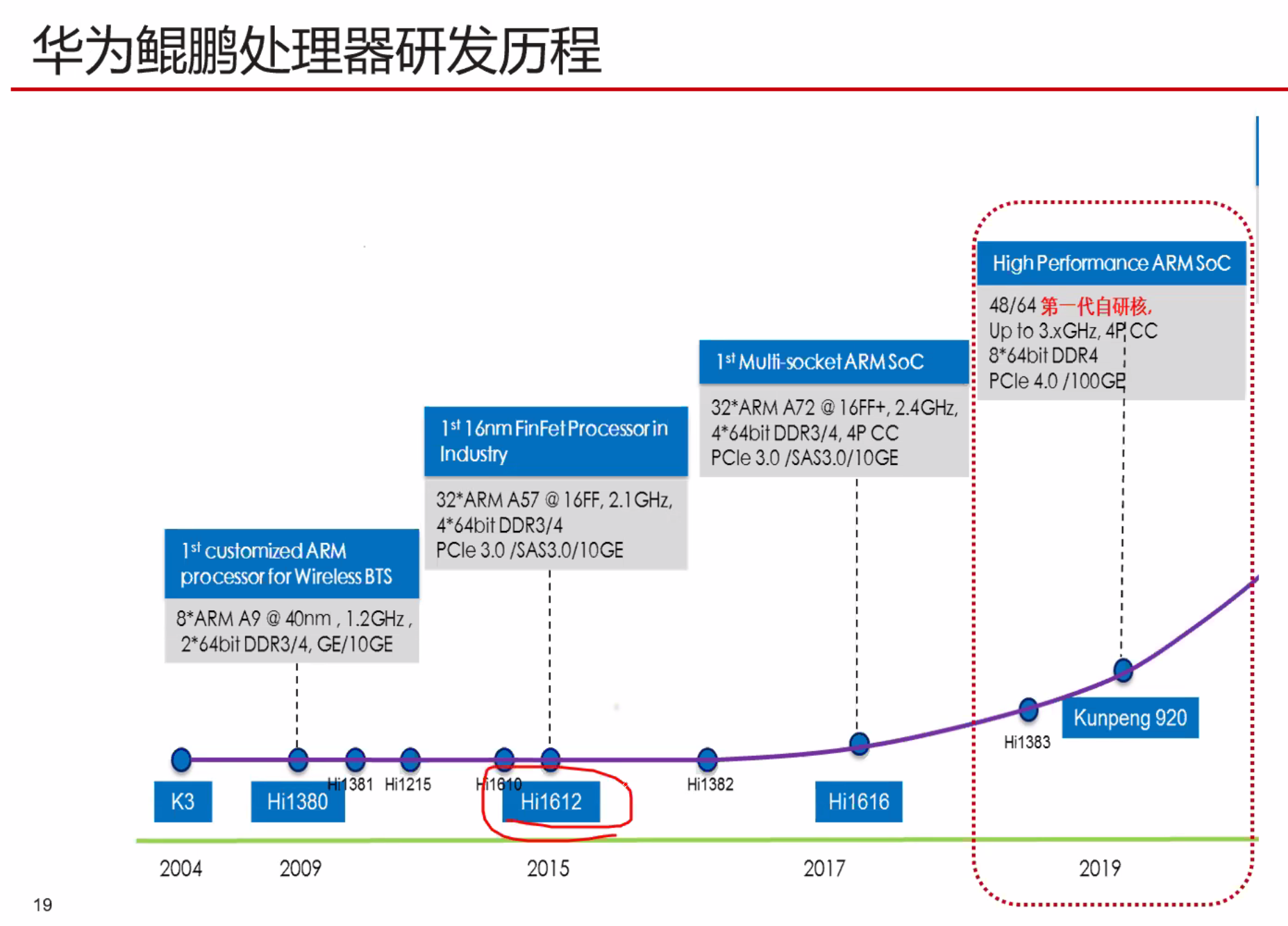
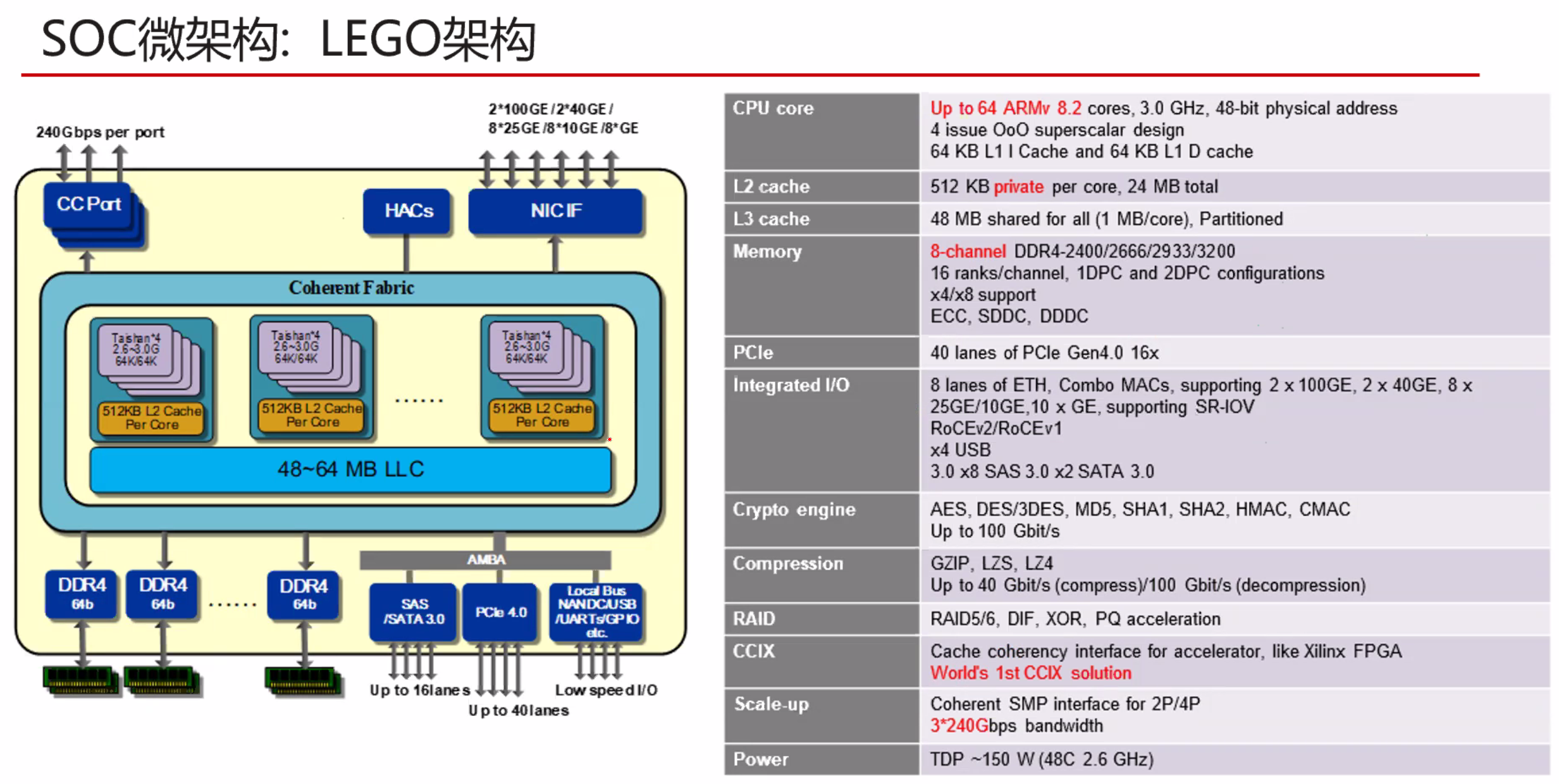
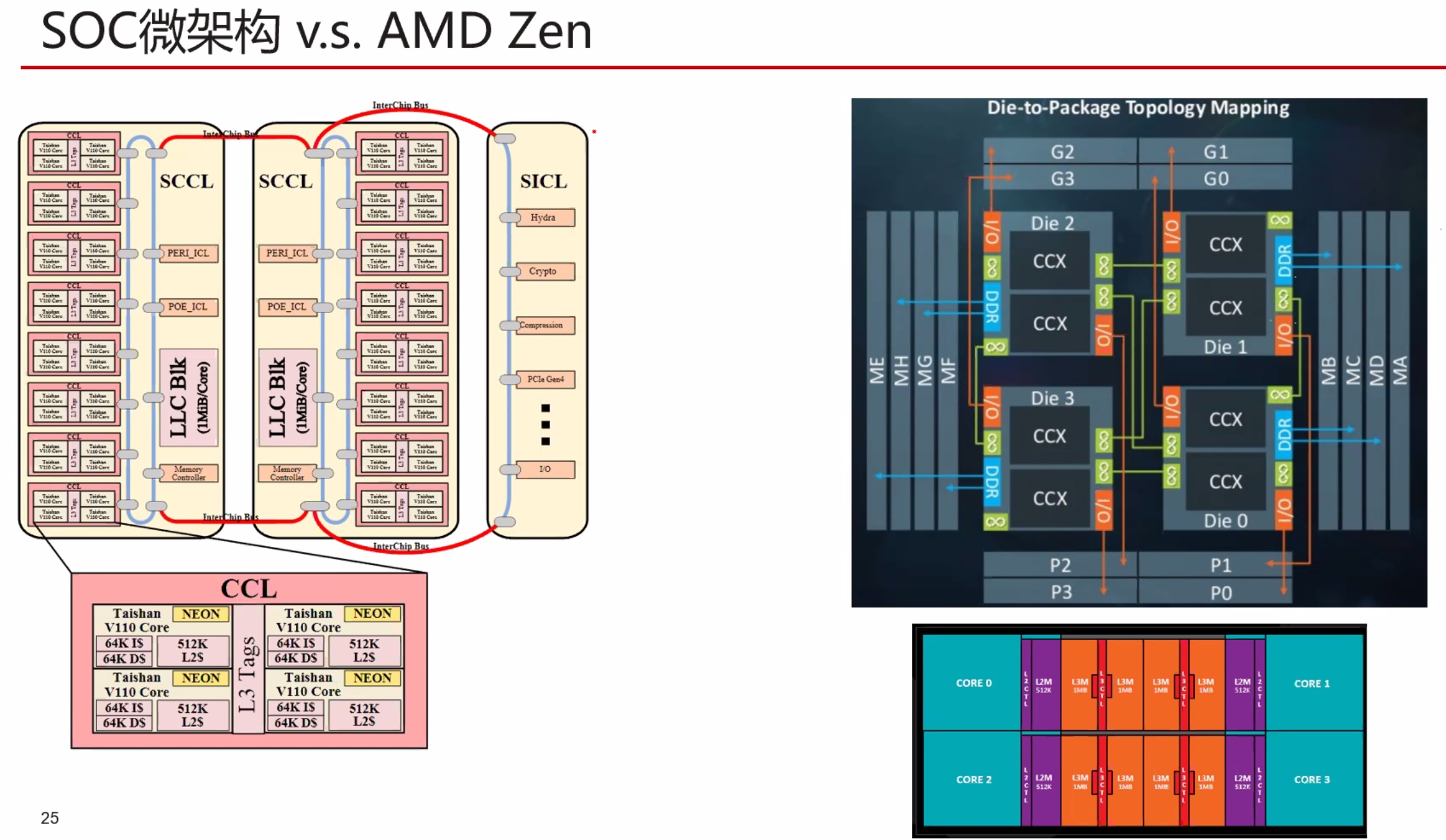
摘要
现代计算机微架构是最复杂的几个人造系统。在上面预测,解释和优化软件是困难的。我们需要其运行行为的可信模型,但是事实是稀缺的。
本文设计和实现了一种构建X86指令的延迟,吞吐量和端口使用的可信模型。并仔细探究了这三个指标的定义。尤其是latency的值在不同的操作数情况时是如何确定的。
同时其结果也是机器可读的。并且对已有的所有Intel架构都进行了测试。
官网有结果 http://www.uops.info
We also plan to release the source code of our tool as open source
1 简介
2 相关工作
Information provided by Intel
Measurement-based Approaches
3 Background
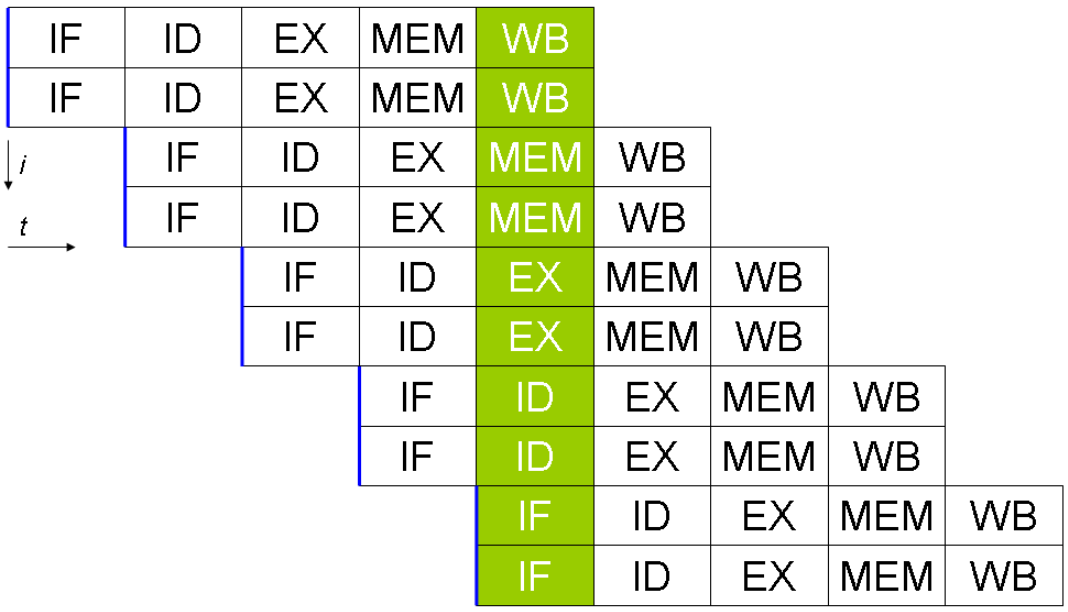
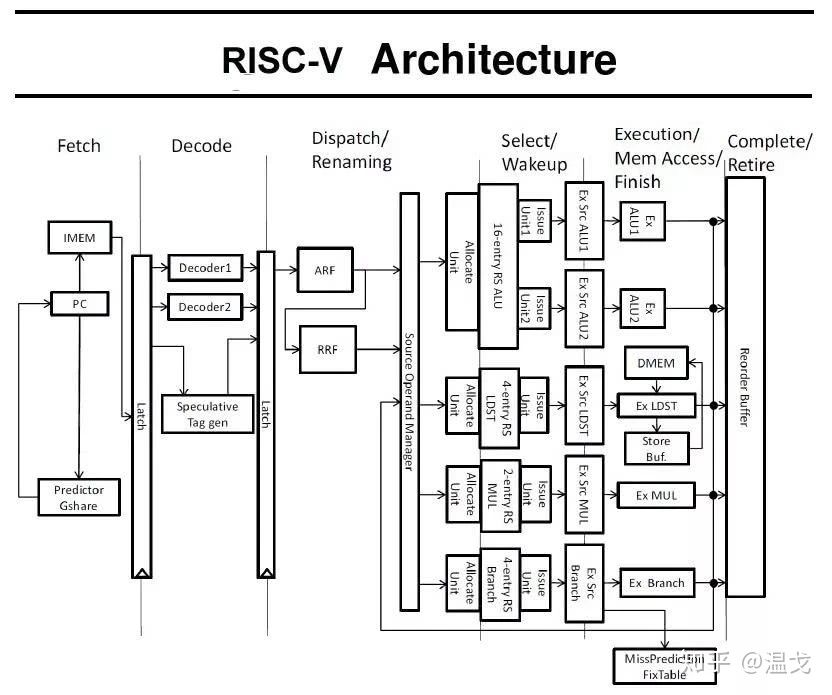
Pipeline of Intel Core CPUs
Assembler Instructions
Hardware Performance Counters
4 Definitions
Latency
Throughput
Port Usage
5 Algorithms
Port Usage
- Finding Blocking Instructions
- Port Usage Algorithm
Latency
- Register -> Register
- Both registers are general-purpose registers
- Both registers are SIMD registers
- The registers have different types
- Memory → Register
- Status Flags → Register
- Register → Memory
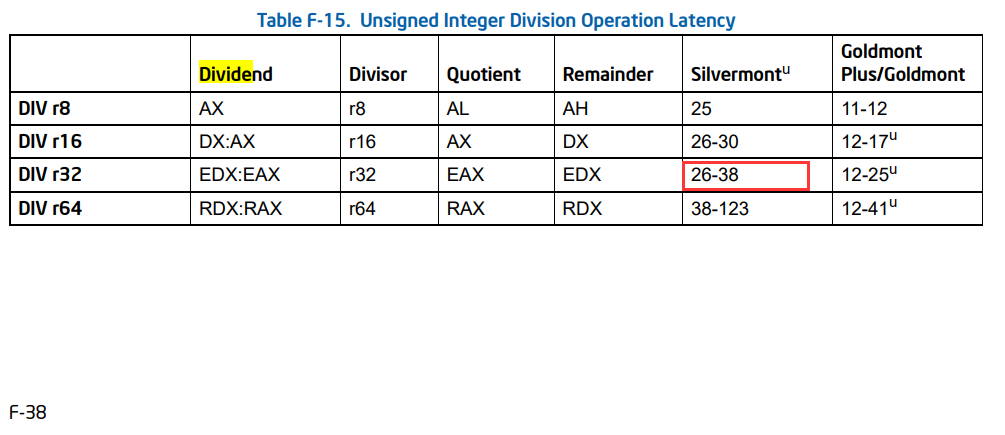
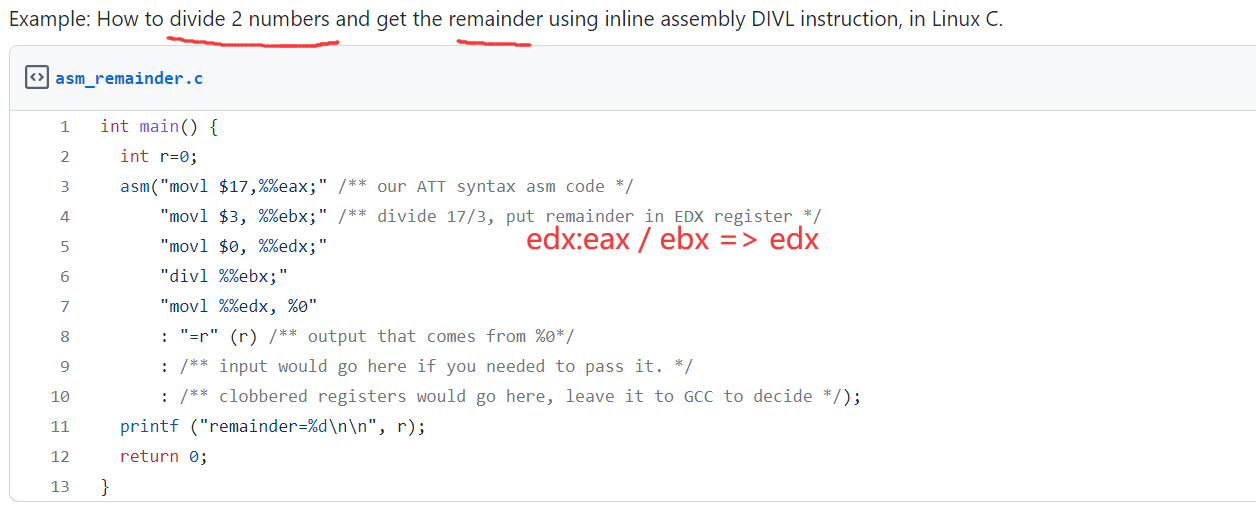
- Divisions
Throughtput
- Measuring Throughput
- Computing Throughput from Port Usage
Computing Throughput from Port Usage
Details of the x86 Instruction Set
Measurements on the Hardware
Analysis Using Intel IACA
Machine-readable Output
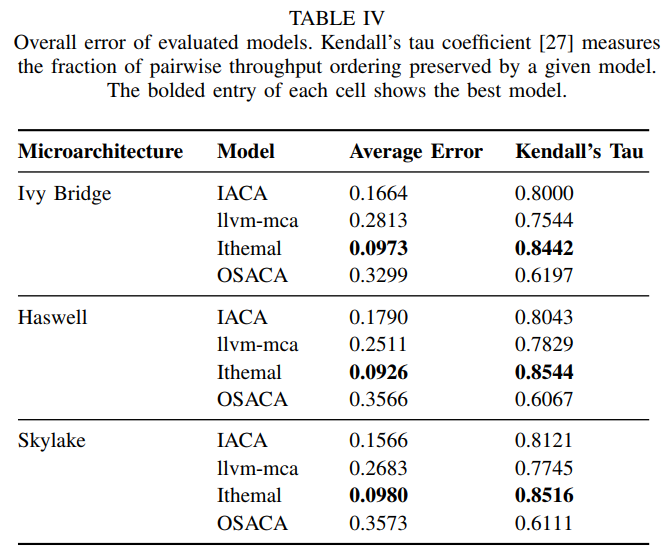
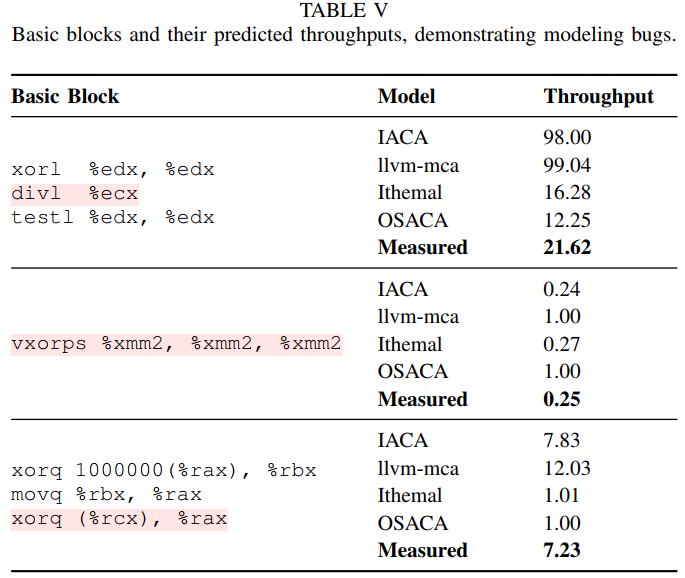
7 Evaluation
balabala~
8 Limitations
9 Conclusions and Future Work
我们的工具可以用来优化llvm-mca等软件。
Future work includes adapting our algorithms to AMD x86 CPUs. 官网已经实现了。
We would also like to extend our approach tocharacterize other undocumented performance-relevant aspects of the pipeline, e.g., regarding micro and macro-fusion, or whether instructions use the simple decoder, the complex decoder, or the Microcode-ROM.
需要进一步的研究学习
暂无
遇到的问题
暂无

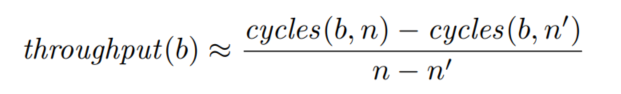







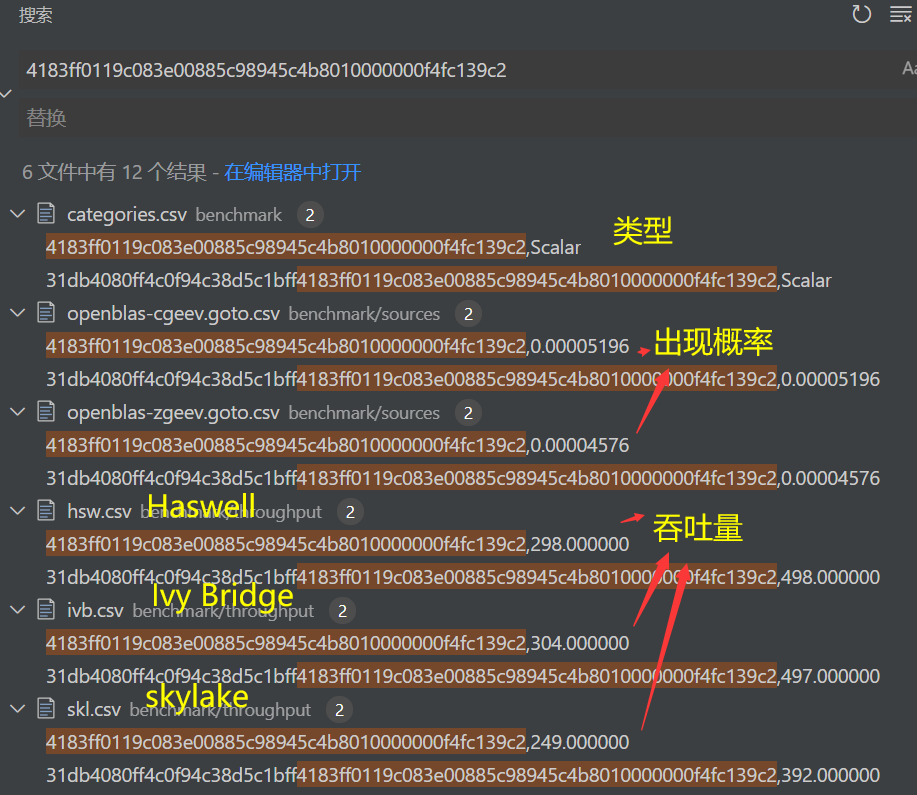
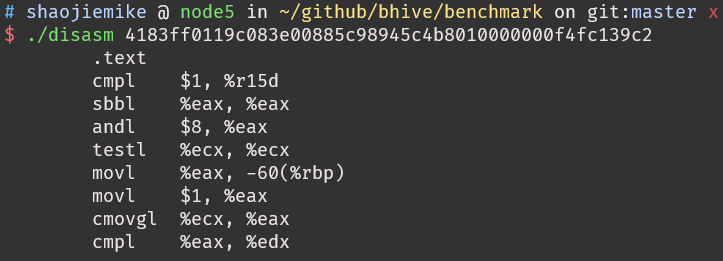
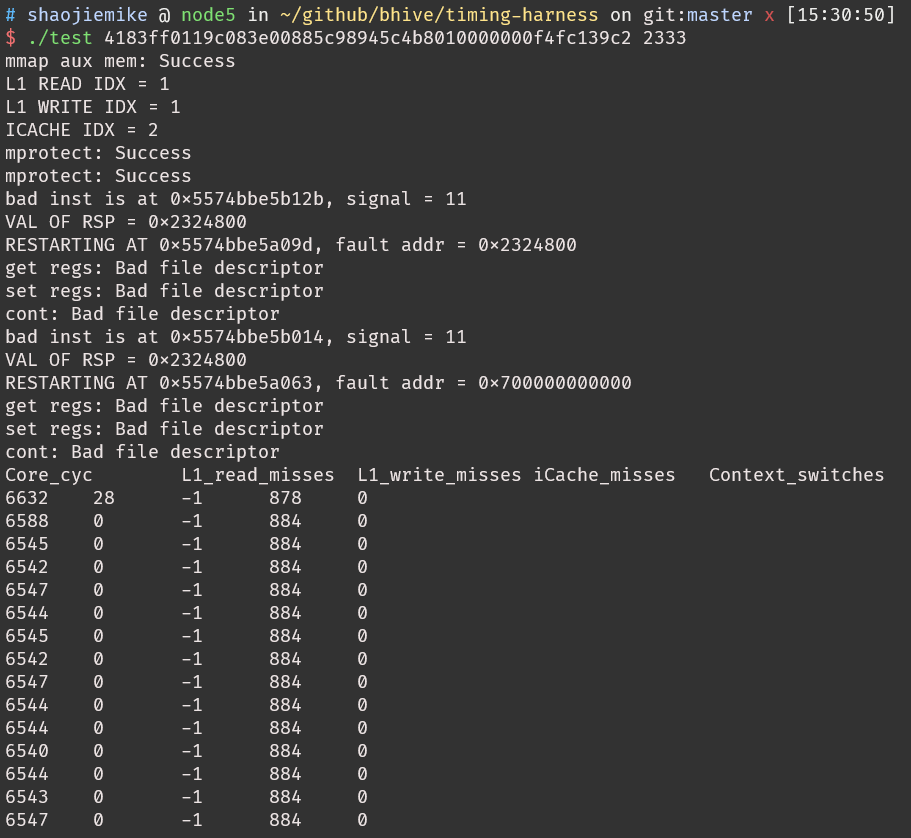
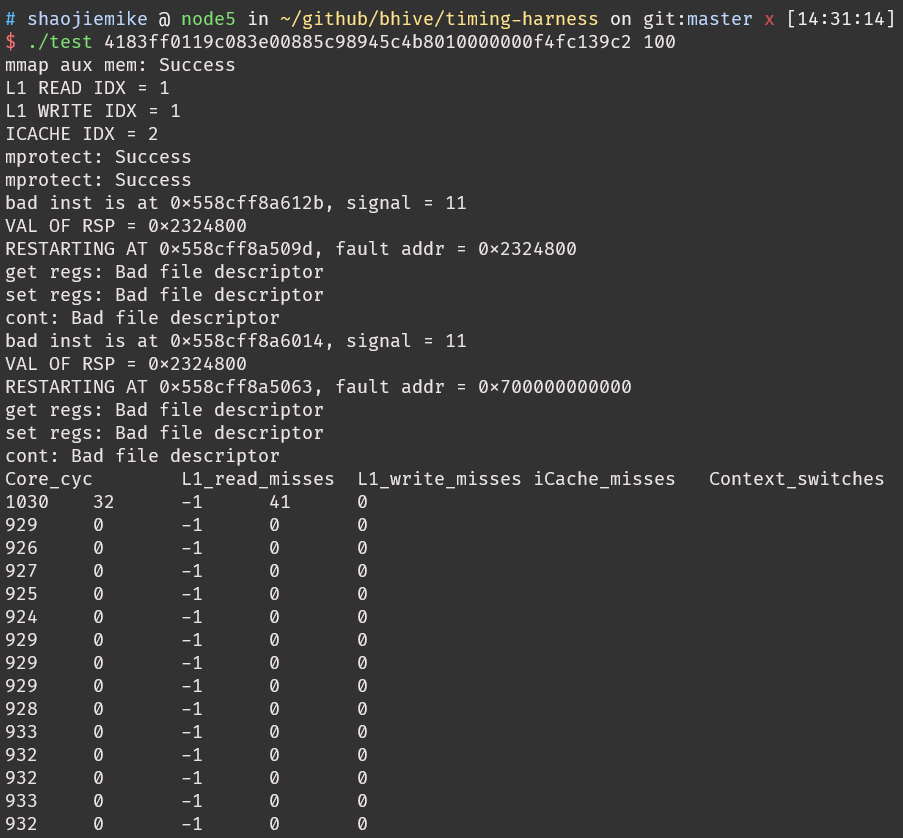



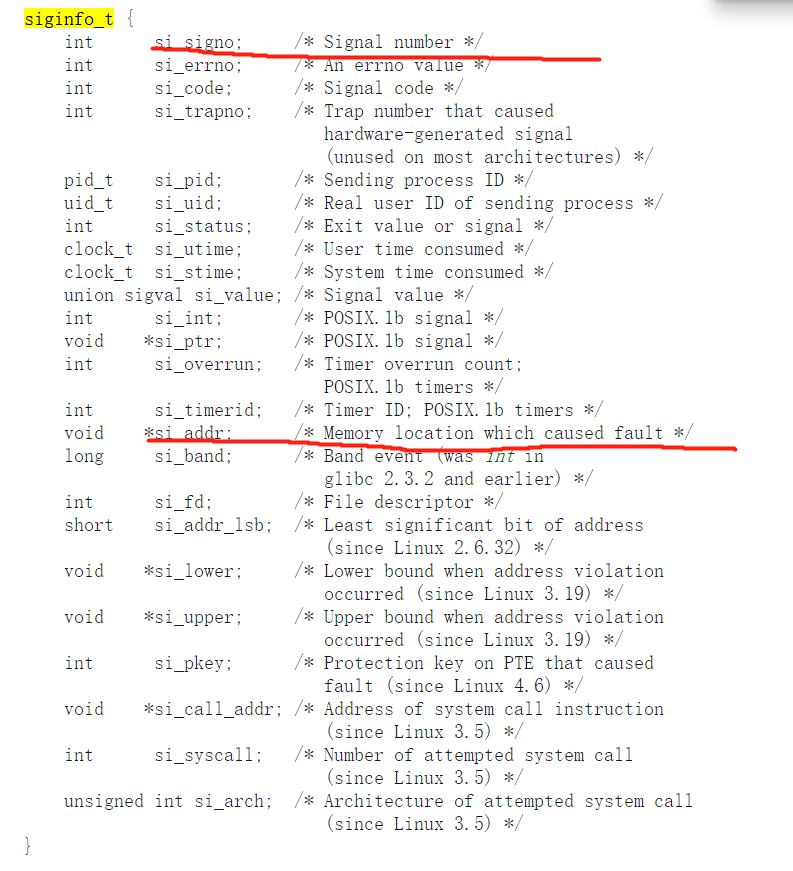
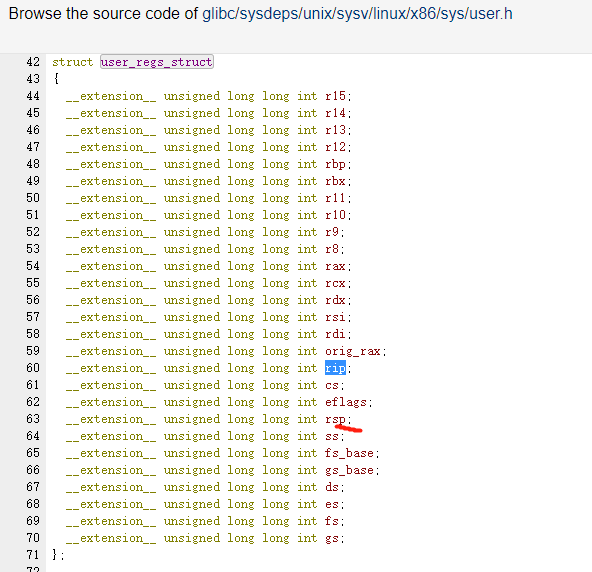
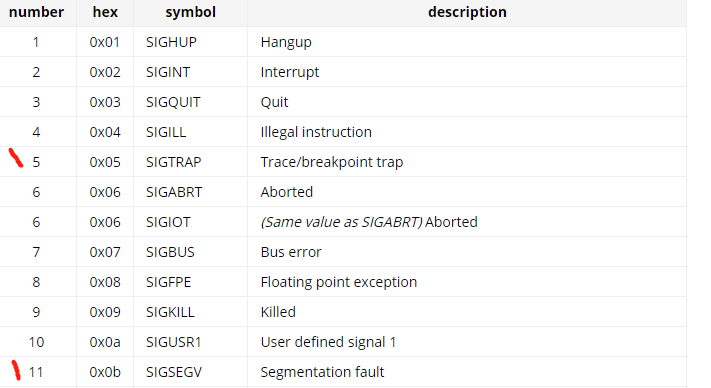
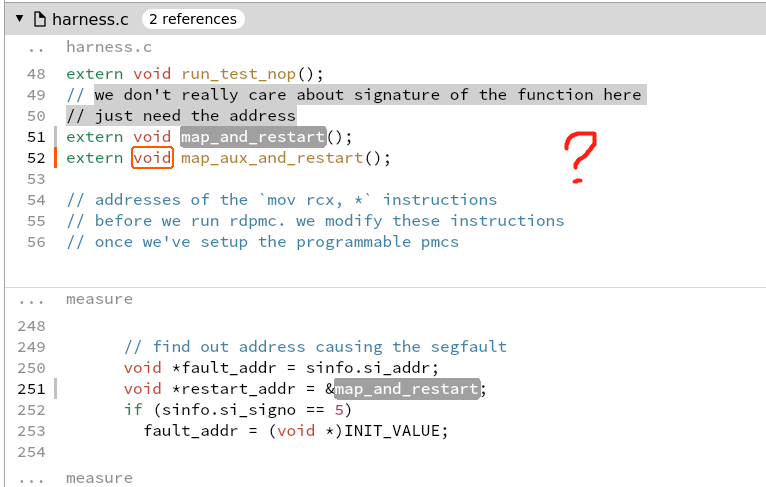

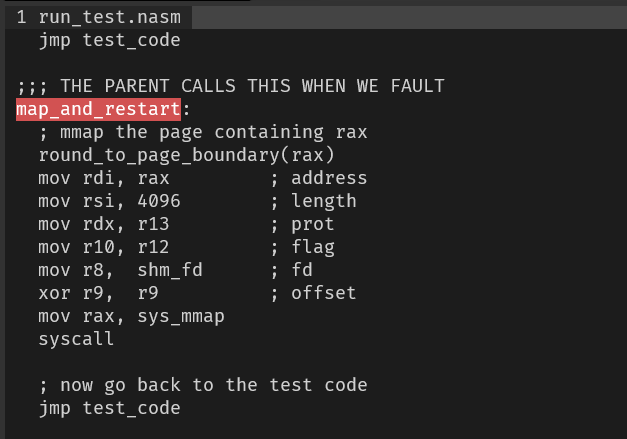
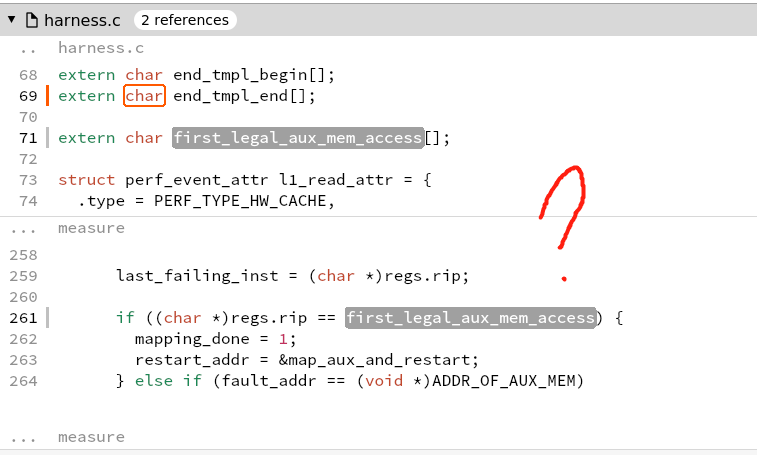
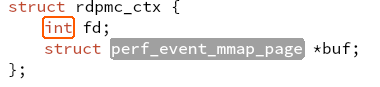
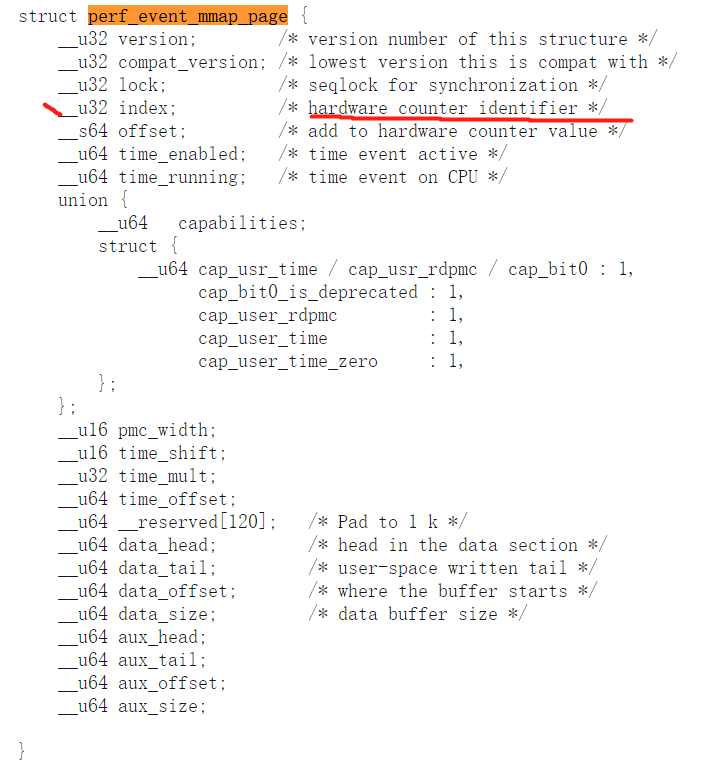
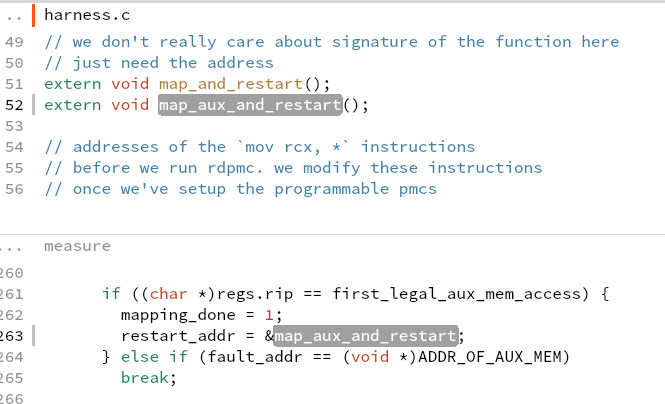 what is aux mem?
what is aux mem?