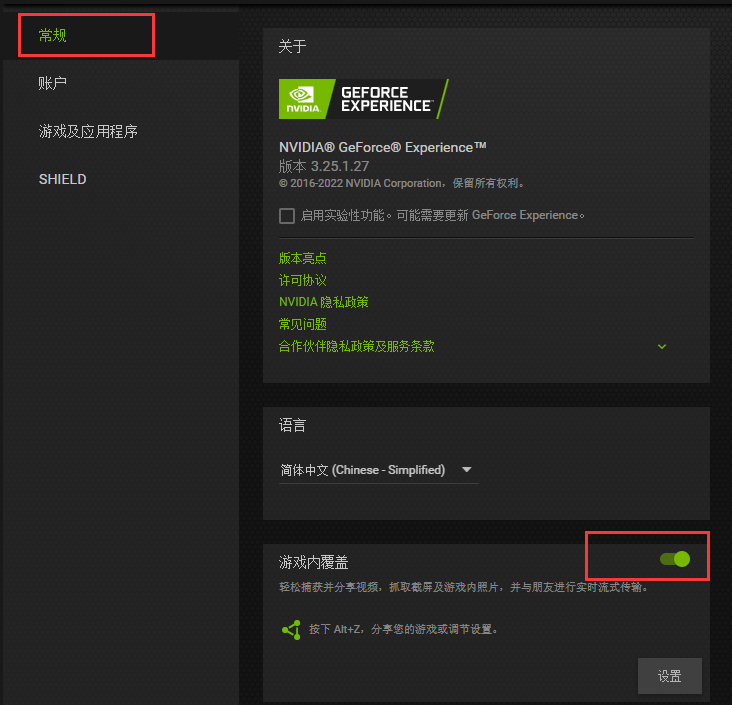
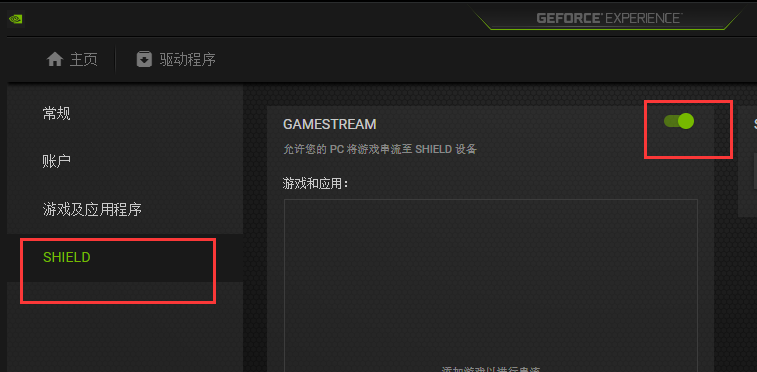
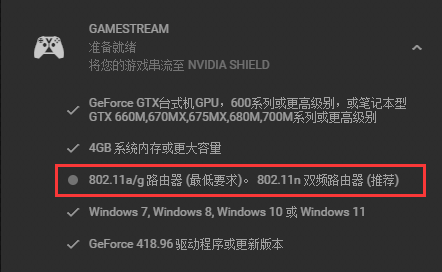
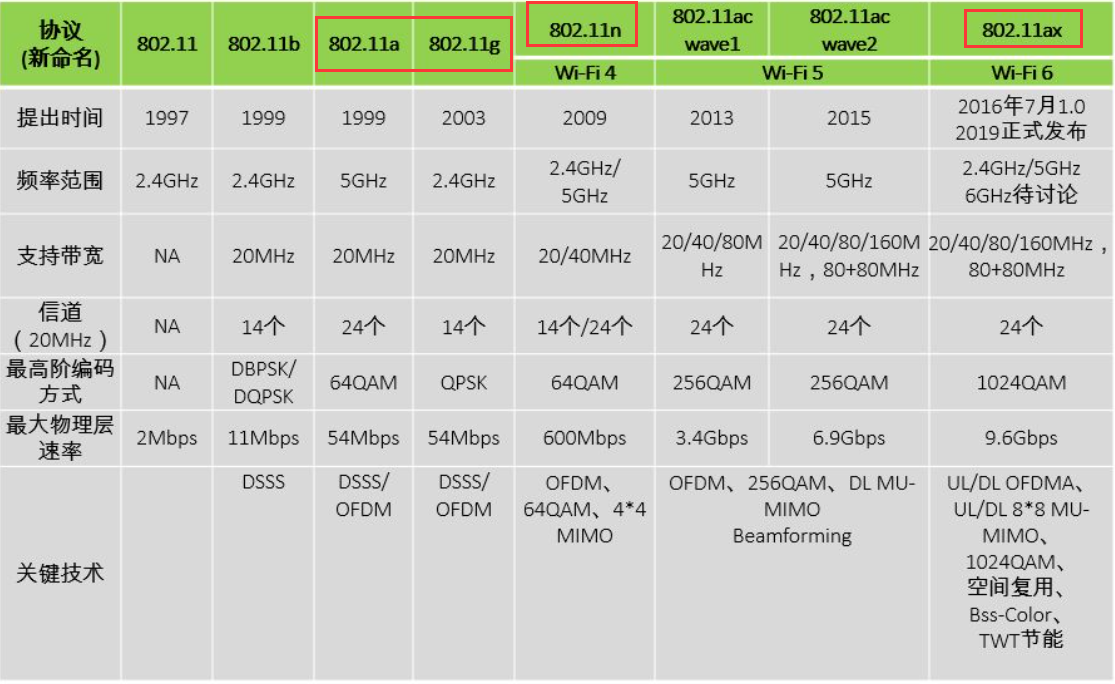
from urllib import request base_url = 'https://f.us.sinaimg.cn/001KhC86lx07laEy0PtC01040200y8vC0k010.mp4?label=mp4_hd&template=640x360.28&Expires=1528689591&ssig=qhWun5Mago&KID=unistore,video' #下载进度函数 def report(a,b,c): ''' a:已经下载的数据块 b:数据块的大小 c:远程文件的大小 ''' per = 100.0 * a * b / c if per > 100: per = 100 if per % 1 == 1: print ('%.2f%%' % per) #使用下载函数下载视频并调用进度函数输出下载进度 request.urlretrieve(url=base_url,filename='weibo/1.mp4',reporthook=report,data=None)
__global__ voiddevice_copy_vector4_kernel(int* d_in, int* d_out, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) { reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i]; }
// in only one thread, process final elements (if there are any) int remainder = N%4; if (idx==N/4 && remainder!=0) { while(remainder) { int idx = N - remainder--; d_out[idx] = d_in[idx]; } } }
voiddevice_copy_vector4(int* d_in, int* d_out, int N) { int threads = 128; int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
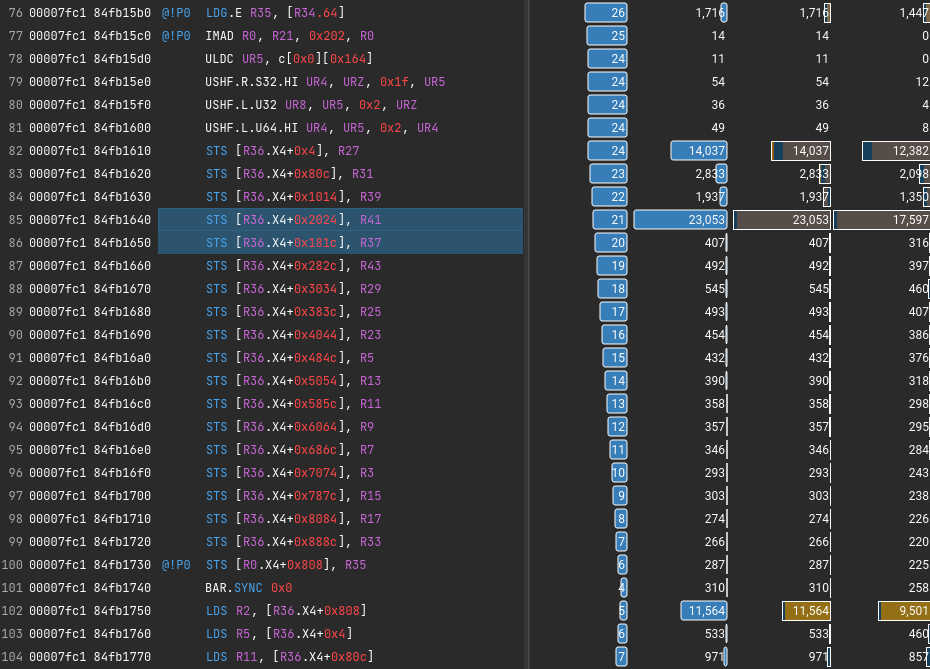
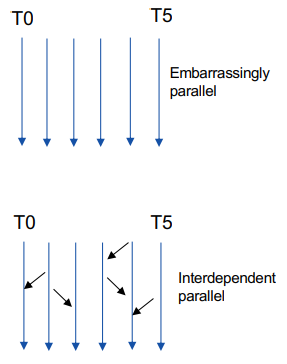
Integer multiply-add with extract: multiply R3 with R5, extract upper half, sum that upper half with constant in bank 0, offset 0x24, store in R7 with carry-in.
line3
1
/*0040*/ LD.E R2, [R6]; //load
LD.E is a load from global memory using 64-bit address in R6,R7(表面上是R6,其实是R6 与 R7 组成的地址对)
summary
1 2 3
R6 = R3*R5 + c[0x0][0x20], saving carry to CC R7 = (R3*R5 + c[0x0][0x24])>>32 + CC R2 = *(R7<<32 + R6)
寄存器是32位的原因是 SMEM的bank是4字节的。c数组将32位的基地址分开存了。
first two commands multiply two 32-bit values (R3 and R5) and add 64-bit value c[0x0][0x24]<<32+c[0x0][0x20],
int main() { const float PI = 3.1415927; const int N = 150; const float h = 2 * PI / N; float x[N] = { 0.0 }; float u[N] = { 0.0 }; float result_parallel[N] = { 0.0 }; for (int i = 0; i < N; ++i) { x[i] = 2 * PI*i / N; u[i] = sinf(x[i]); } ddParallel(result_parallel, u, N, h); }
Kernel Launching
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
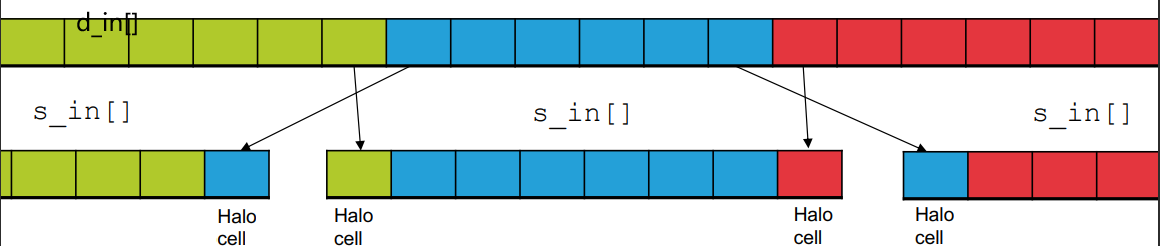
#define TPB 64 #define RAD 1 // radius of the stencil … void ddParallel(float *out, const float *in, int n, float h) { float *d_in = 0, *d_out = 0; cudaMalloc(&d_in, n * sizeof(float)); cudaMalloc(&d_out, n * sizeof(float)); cudaMemcpy(d_in, in, n * sizeof(float), cudaMemcpyHostToDevice);
// Set shared memory size in bytes const size_t smemSize = (TPB + 2 * RAD) * sizeof(float); ddKernel<<<(n + TPB - 1)/TPB, TPB, smemSize>>>(d_out, d_in, n, h); cudaMemcpy(out, d_out, n * sizeof(float), cudaMemcpyDeviceToHost); cudaFree(d_in); cudaFree(d_out); }
Kernel Definition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
__global__ void ddKernel(float *d_out, const float *d_in, int size, float h) { const int i = threadIdx.x + blockDim.x * blockIdx.x; if (i >= size) return; const int s_idx = threadIdx.x + RAD; extern __shared__ float s_in[];