RAM
RAM (random access memory), 中文名叫随机存储器, 随机是什么意思呢? 意思是, 给定一个地址, 可以立即访问到数据(访问时间和位置无关)
而不像咱们熟悉的磁带, 知道最后一首歌在最后的位置, 却没法直接一下子跳到磁带的最后部门, 所以磁带不是随机存储器, 而是顺序存储器。
SRAM vs DRAM
SRAM (Static Random Access Memory) and DRAM (Dynamic Random Access Memory)
| BASIS FOR COMPARISON | SRAM | DRAM |
|---|---|---|
| Speed | Faster | Slower |
| Size | Small | Large |
| Cost | Expensive | Cheap |
| Used in | Cache memory | Main memory |
| Density | Less dense | Highly dense |
| Construction | Complex and uses transistors and latches. | Simple and uses capacitors and very few transistors. |
| Single block of memory requires | 6 transistors | Only one transistor. |
| Charge leakage property | Not present | Present hence require power refresh circuitry |
| Power consumption | Low | High |
基本电路实现
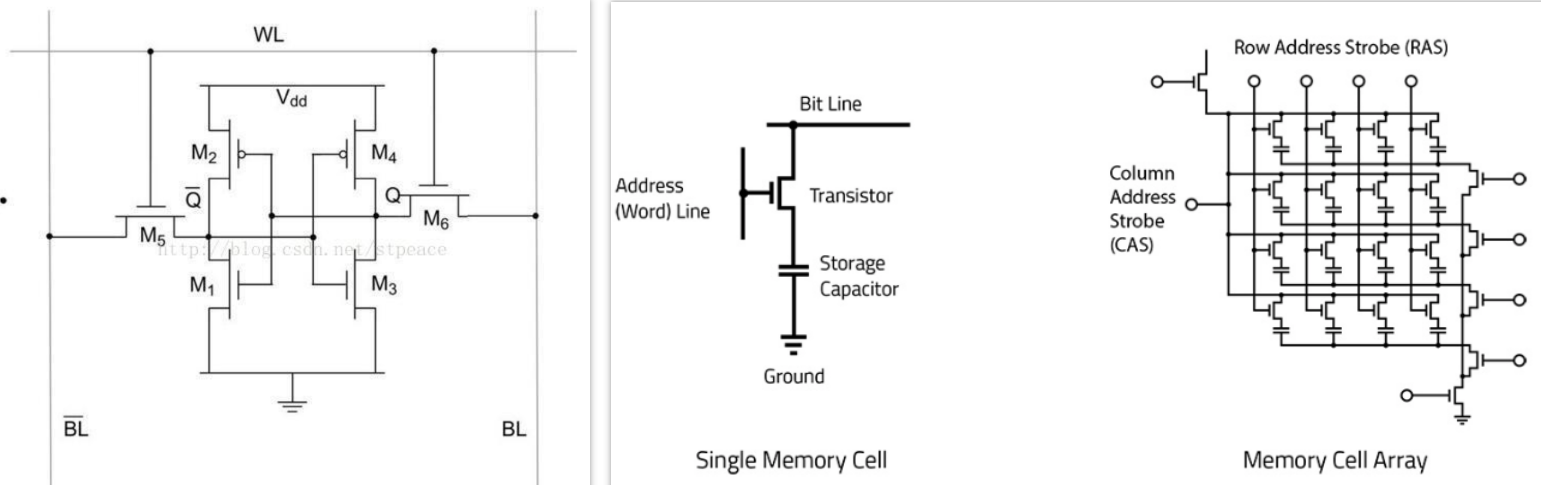
左边的是静态的,右边的是dynamic的。
SRAM,保存一个bit需要6个晶体管。
DRAM 存储一个bit的DRAM只需要一个电容和一个晶体管。 DRAM的数据实际上是存在于电容里面的, 电容会有电的泄露, 损失状态, 故需要对电容状态进行保持和刷新处理, 以维持持久状态, 而这是需要时间的, 所以就慢了。而且很耗电。
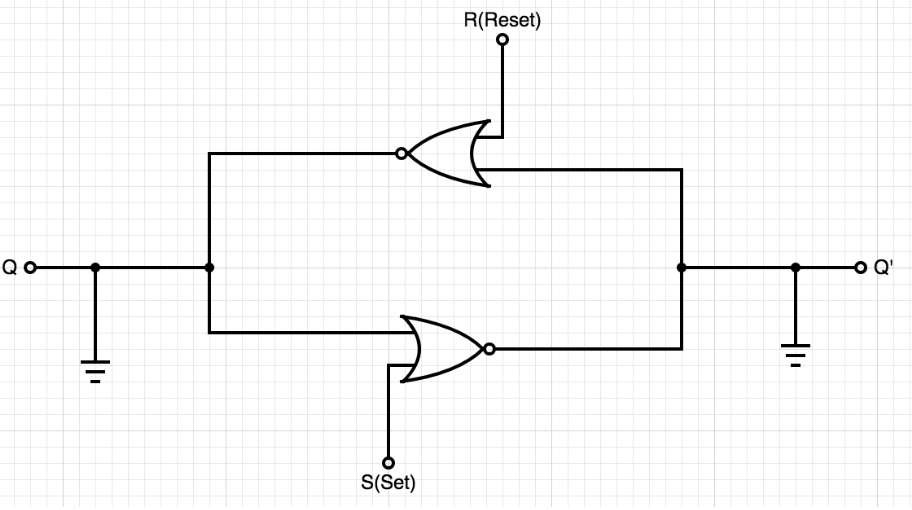
DRAM内存实现的存储是通过晶体管实现的一个电路 门控D锁存器,其更简化的形式是 SR锁存器,电路结构如下图:
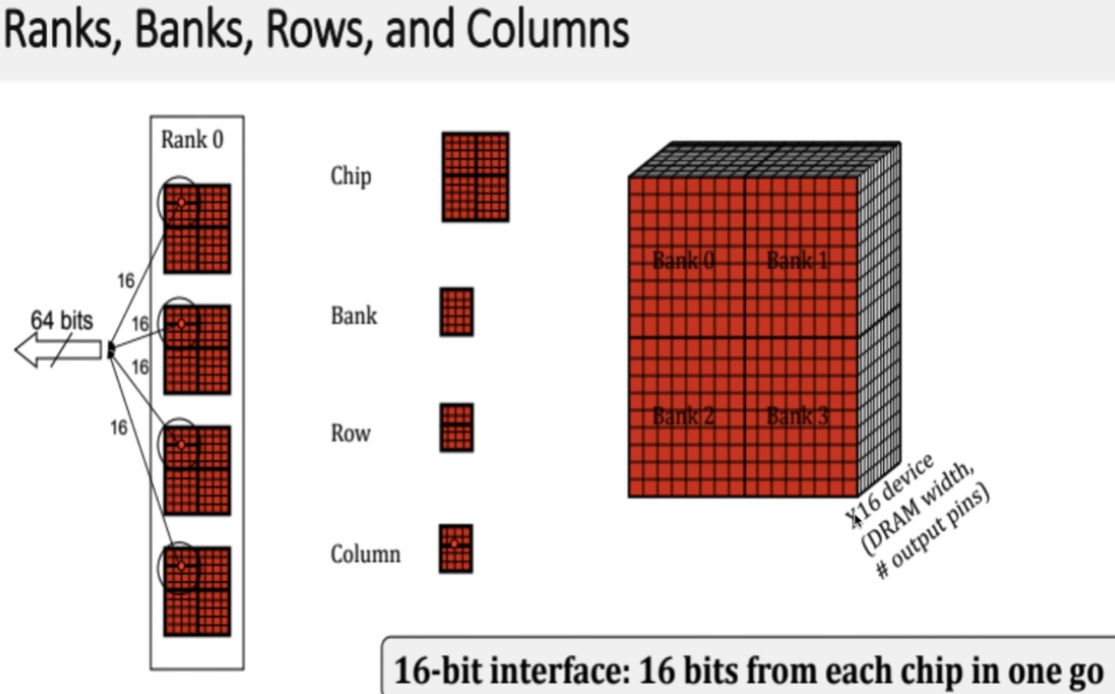
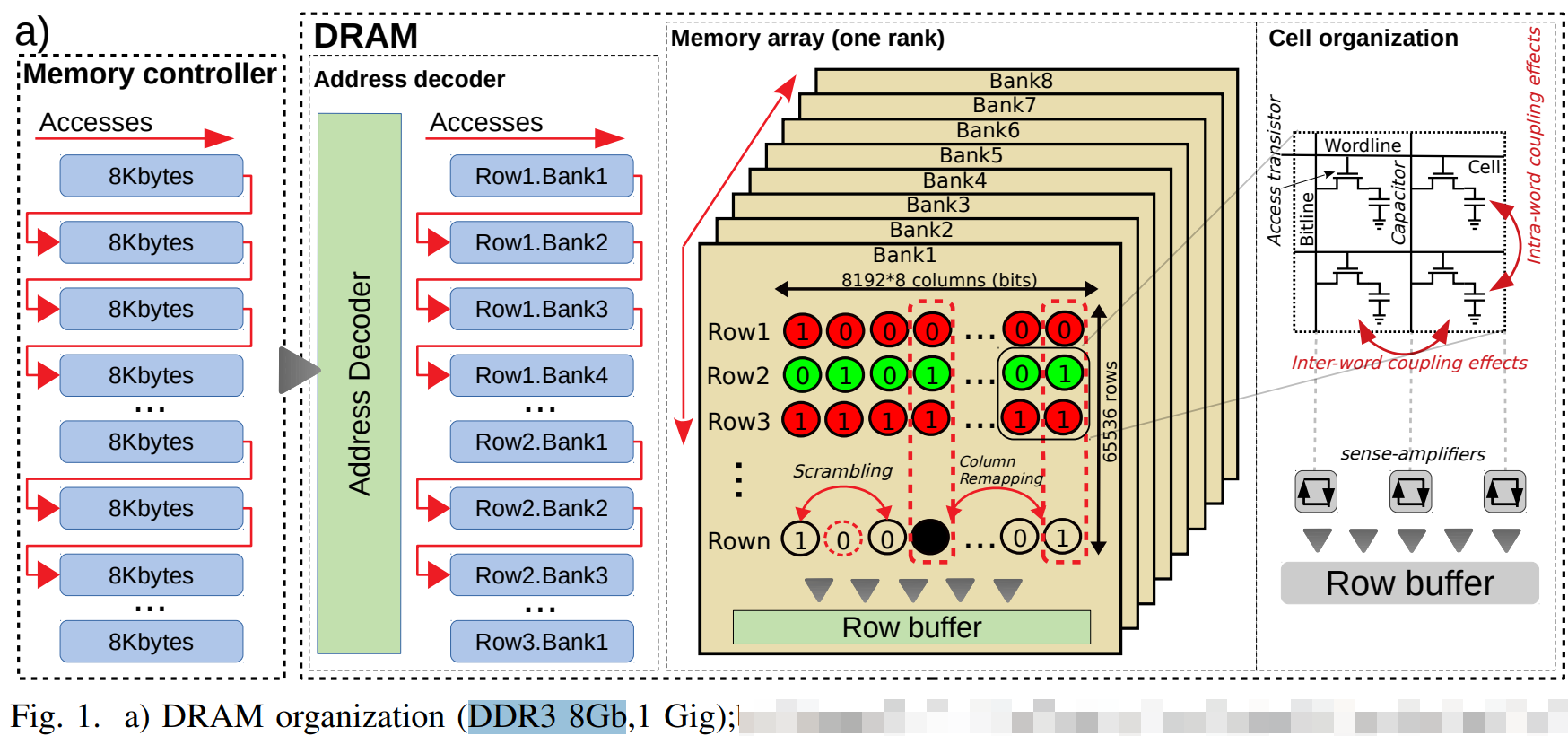
但是bank矩阵的一个点(基本存储单元, 寻址能力, 内存颗粒(Chip)的位宽)一般是8bit.
8个 门控D锁存器 组成内存的基本(最小)存储单元,他们共用一个行/列 地址线。在一次寻址中每个内存颗粒返回 8 bit的数据 8个内存可以同时寻址 最终得到的是 8 * 8(8个chip) = 64 bit 的连续数据 也就是说 内存一次寻址可以读取 8 Byte 的数据,这里也能说明在C语言中的内存不齐的原因(减少寻址次数)。
SDRAM
现在的DRAM一般都是SDRAM,即Synchronous Dynamic Random Access Memory,同步且能自由指定地址进行数据读写。其结构一般由许多个bank组成并利用以达到自由寻址。
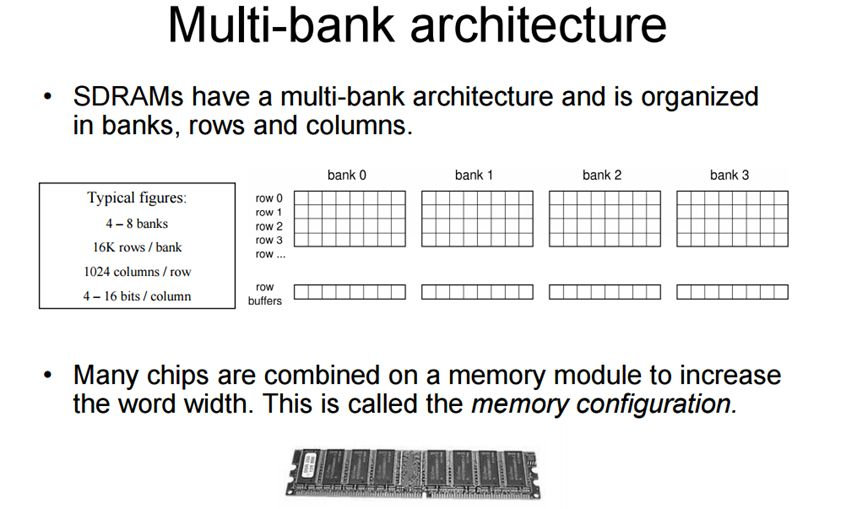
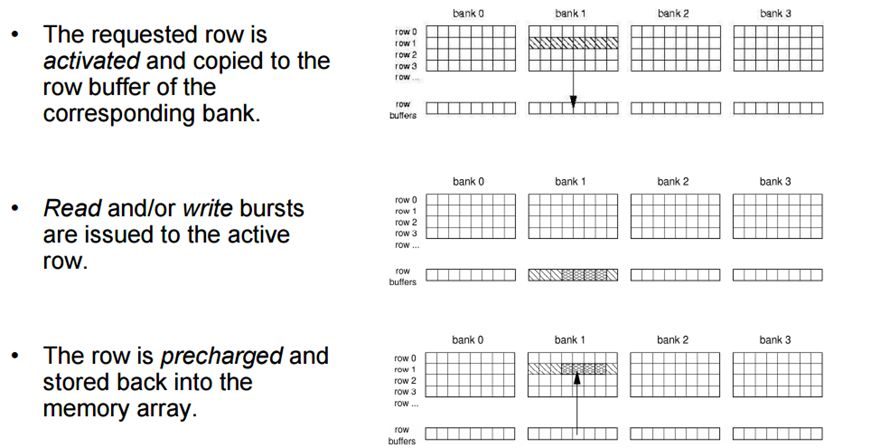
chip的多 Bank 的设计允许向每个Bank 发出不同的命令。同一时刻,不同的bank可以处理不同的行地址。当然,不可能同时读取或者写入多个 Bank,因为读写通道只有 1 个,当时可以在 1 个 Bank 读写时,向另一个 Bank 发出 Precharge 或者 Active 命令。
DRAM基本术语
| 名词 | 解释 |
|---|---|
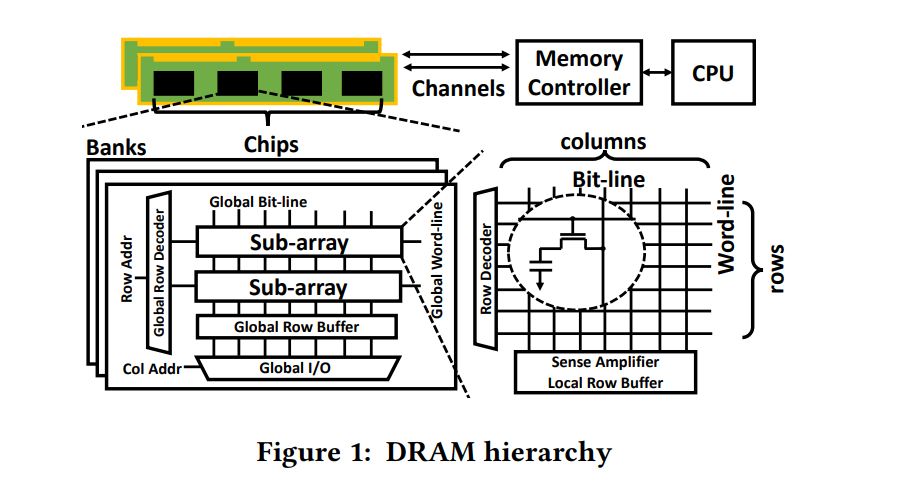
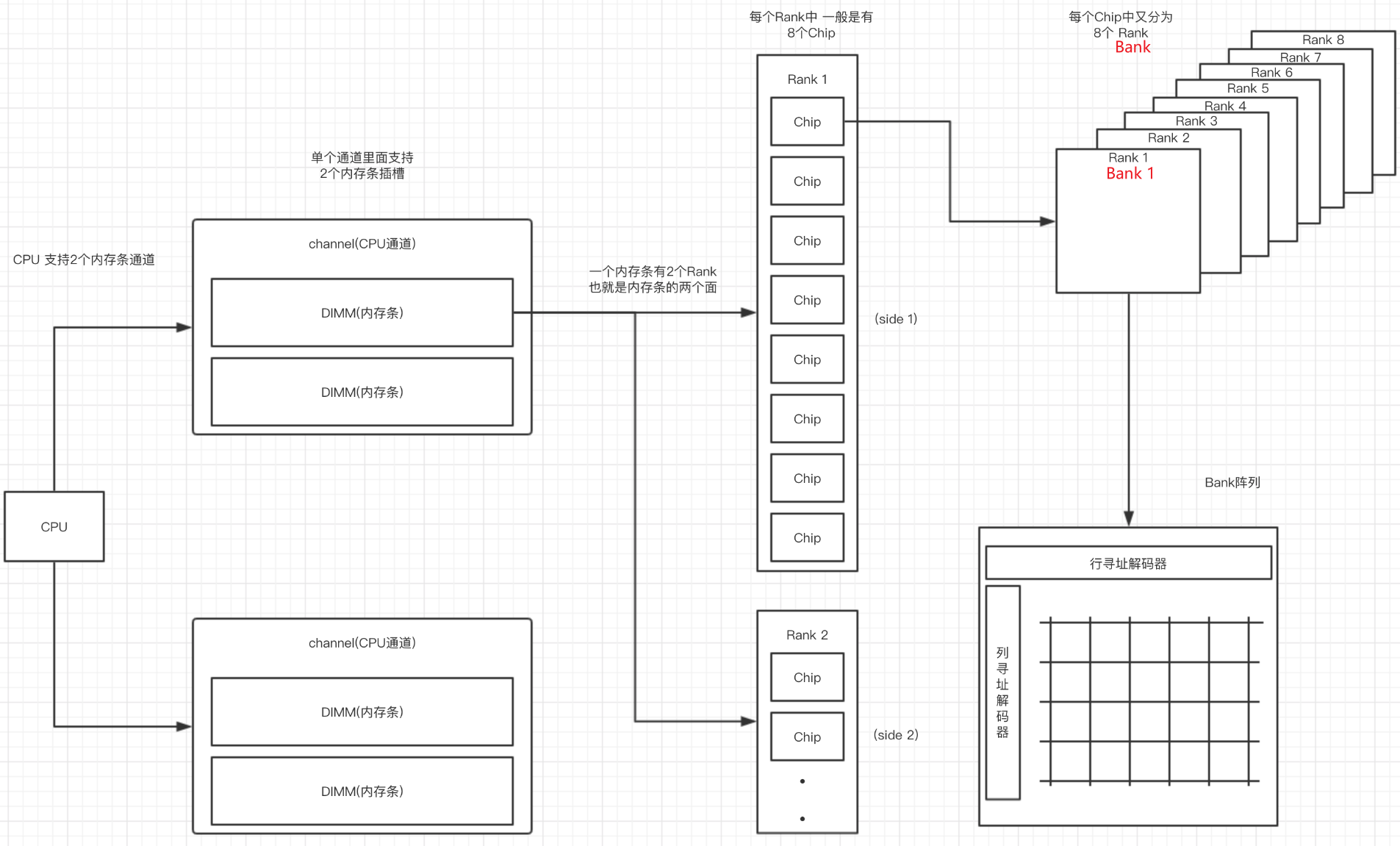
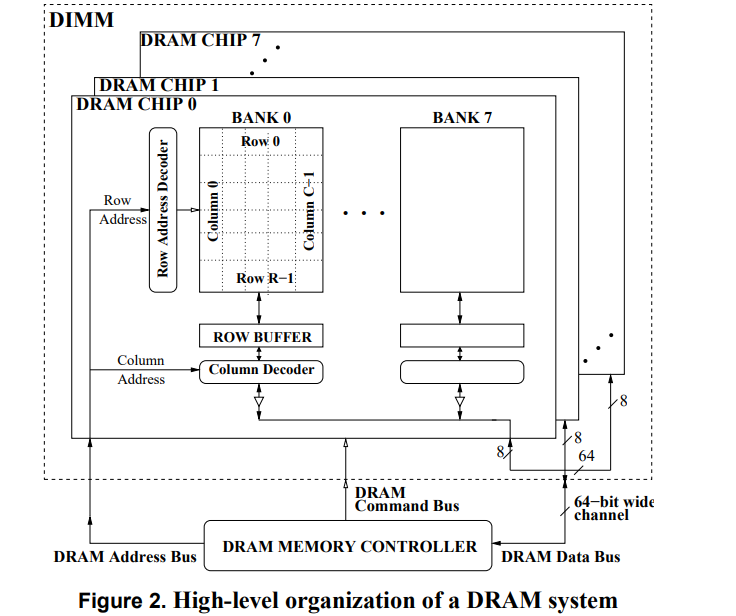
| dual inline memory modules (DIMMs). | 每个channel可以连接多个DIMM,每个DIMM与多个DRAM chip相联 |
| Cell: | 颗粒中的一个数据存储单元叫做一个Cell,由一个电容和一个N沟道MOSFET组成。 |
| chip: | 一个颗粒叫做一个chip。一根内存的内存带宽是64bit,如果是单面就是8个8bit颗粒,如果是双面,那就是16个4bit的颗粒分别在两面,不算ECC颗粒(Error Checking and Correcting错误校验芯片)。 |
| Bank | 每个chip有4~8个bank,每个bank可以看作一个行列矩阵,每个点存储4~16bit的信息。 |
| Rank: | 内存PCB的一面所有颗粒叫做一个rank,目前在Unbuffered台式机内存上,通常一面是8个颗粒,所以单面内存就是1个rank,8个chip |
| 寻址空间 | 是指内存总共可以存储多少个地址,比如一个2G DDR3内存 ,每个Rank是2/1=1G ,每个内存颗粒是1/8=128M 每个Bank是 128/8=16M 16M = 2^4 * 2^10 = 2^14 也就是地址线需要14根 正对应地址线的 A0-A13 |
Overview
 { width=80% }
{ width=80% }
CRC Error Detection
DDR4 chip 内bank & bank group设计
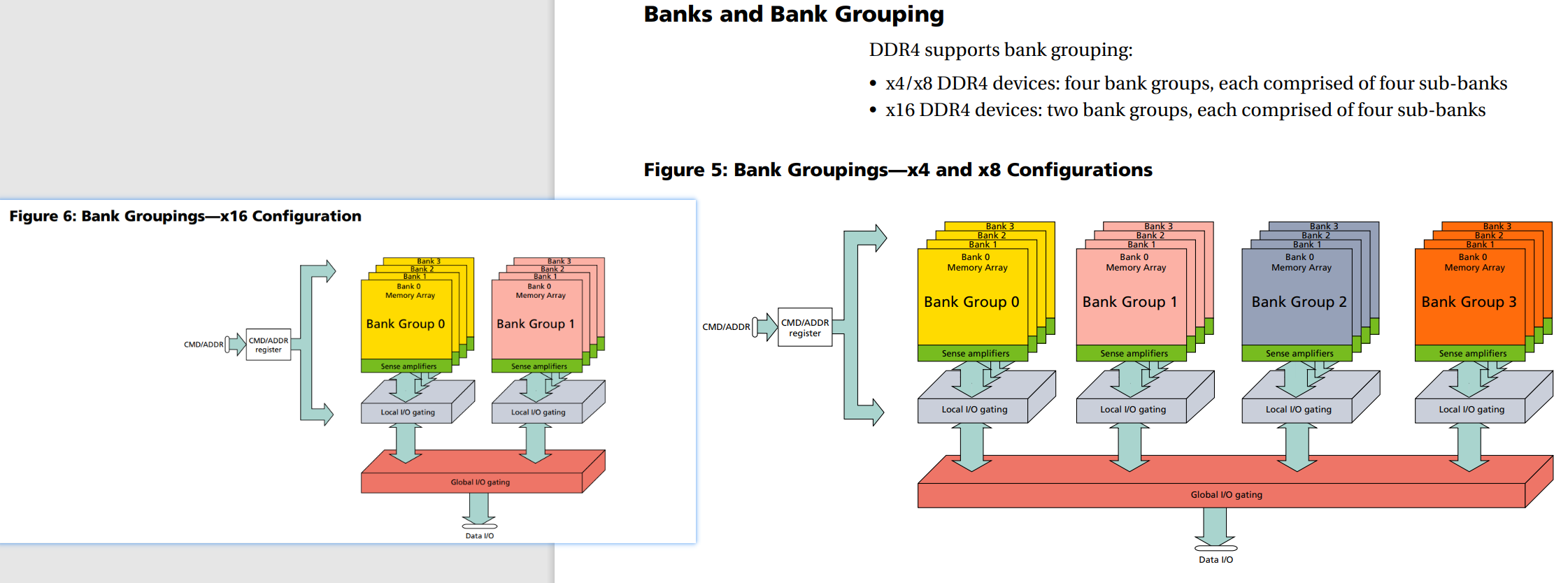
每個DRAM裏有4個bank選取位元可用來選取多達16個bank單元:兩個bank位址位元(BA0、BA1),和兩個bank群組位元(BG0、BG1)。當在同一個bank群組中存取不同的bank單元時會有另外的時間限制;在不同的bank群組中,存取一個bank比以往的更快。
另外,3個晶片層選取信號(C0、C1、C2),允許最多8個堆疊式晶片層封裝於一塊DRAM封裝上。這可以更有效地充當3個以上的bank單元選取位元,使選取總數達到7(可以定位128個bank單元)。
内存控制器(Memory Controller)

我们知道cache的存在导致访存是按照cache line(32或者64字节)来进行的,但是内存一般只会处理连续64bits数据,导致需要控制器和总线分多周期(memory burst概念)来实现cache的更新。
SNB CPU的内存控制器可以实现和处理:
- 对读写操作命令进行有效地重新分配,以使得行地址激活命中率最大化(如果重复激活一个已经处于激活状态的行地址,那就是RAS激活命令未命中)
- 比如说open page policy情况下,row hit就不用发activate命令,直接发column就可以了,
- 比如说两个地址连续mem_read命令,中间插有其他命令的时候是不是要乱序执行
 [^1]
[^1]CPU集成内存控制器技术
AMD公司提高CPU与内存性能的一项技术,将北桥的内存控制器集成到CPU,使得原来CPU-北桥-内存三方传输数据的过程简化成CPU与内存之间的单向传输技术,降低了延迟。
DRAM 寻址模式

- 列数一般是1024,主要是因为功耗的原因
以2GB DDR3为例子,编码如上,
- 确定好rank面后
- 对该rank面的所有内存颗粒(chip),使用相同的Bank层 、行地址 、列地址 这些选址信息后,各自产生8bits数据,总共64bits
- 单个 Bank 只有一个 Sense Amps,只能缓存单个行的内容。因此在激活某行后,访问同一 Bank 不同行之前,需要使用 PRECHARGE 命令关闭(de-activate)当前激活行。PRECHARGE 命令好比关上当前打开的文件柜抽屉,命令发出后当前 Sense Amps 中缓存的行会被写回原地址。
Burst
DDR中的Burst(突发长度)指的是,当收到了一个读请求和地址后,会连续取出这个地址周围几个连续地址上的数据,具体取几个就叫BL(Burst Length),是可以随地址信号配置的。(原因是:次次等待Address和Enable信号再读写有些浪费时间)
Burst的实现是通过Prefetch完成的,Prefetch就是一次从Array上取出多bit的过程,而Burst则是根据规则发送这些预取的数据的过程。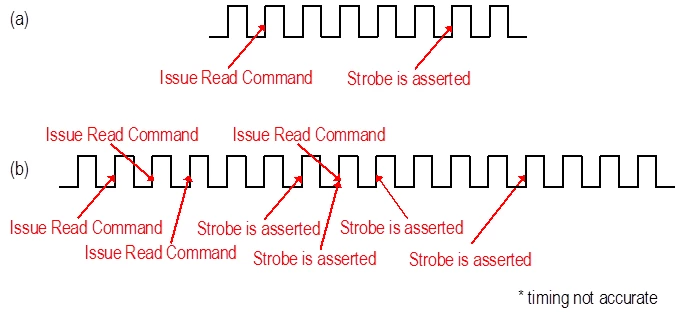
Burst Length(BL)是可以配置的,比如8Bit预取可以支持BL8的Burst或者BC4(Burst Length Chopped)的Burst。
Prefetch (Request Pipelining)
Prefetch数量也是前几代DDR的主要区别。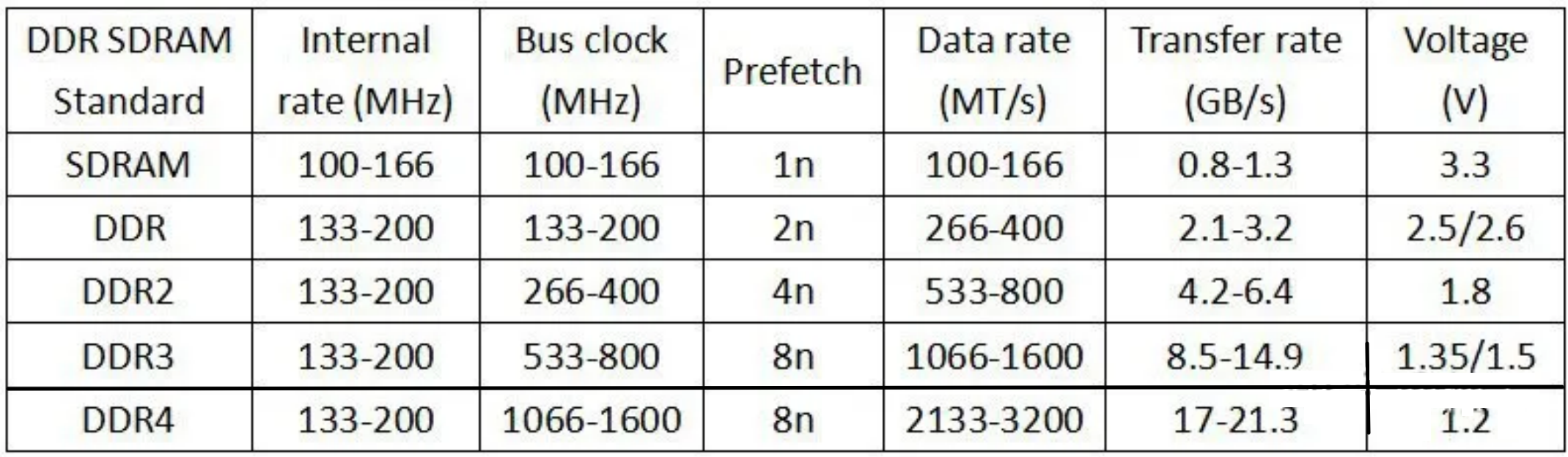
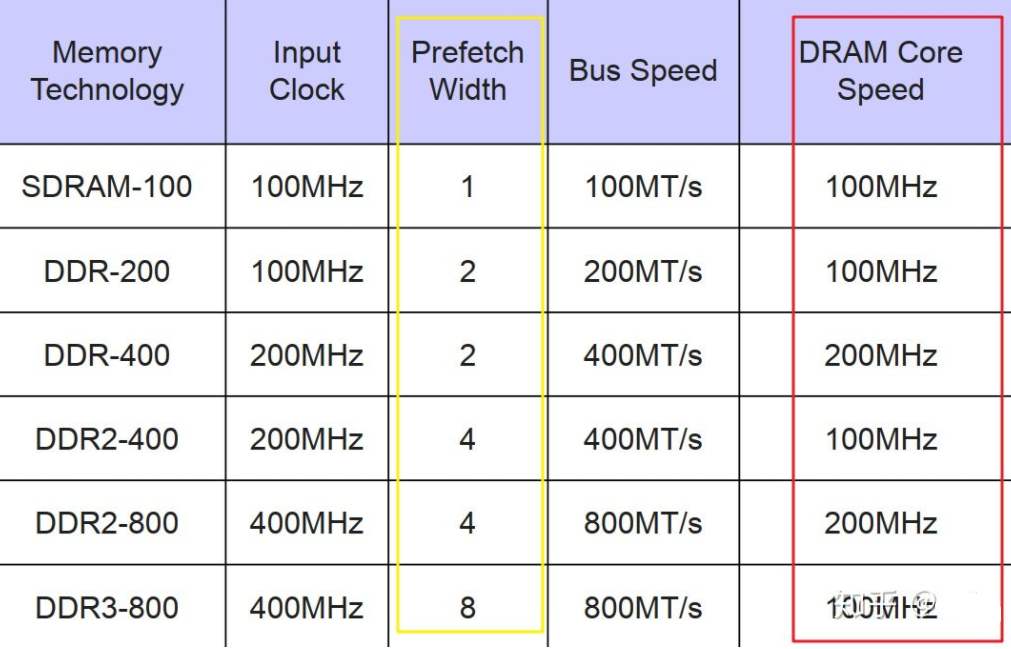
红框标出的DRAM的核心频率基本不变,传输速度的提高是通过增加prefetch的位数(黄框)来做到的。
DDR 有两项主要的技术 2n-prefetch (2 倍预取),和 DLL (延迟锁相环)。这在之后历代 DDR 协议中都是一脉相承的。所谓 2 倍预取,即在一个时钟的上升边沿读取当前地址单元的数据,并同时读取下一个地址单元的数据。
DDR3
DDRx的核心频率一直维持在100Mhz到266MHz的水平上,每代速度的提升都是靠倍增Prefetch的个数来达到的。
DDR4
DDR4和DDR3一样,只有8n的prefetch,但为了提升前端Front End的总线速度,不得不在核心频率上动起了手脚:
核心频率不在徘徊在100~266HMz,直接200起跳,到400Mhz。因为核心频率提高,8bit的prefetch不变,总线速度才得以提升。
除此之外,引入了Bank Group。DDR4 新增了4 個Bank Group 資料組的設計,各個Bank Group具備獨立啟動操作讀、寫等動作特性,Bank Group 資料組可套用多工的觀念來想像,亦可解釋為DDR4 在同一時脈工作周期內,至多可以處理4 筆資料,效率明顯好過於DDR3。
访存时序知识
CL-tRCD-tRP-tRAS-CR
| 名词 | 解释 |
|---|---|
| CL(CAS Latency) | 列信号延迟: 在读取命令发出后到数据读出到IO接口的间隔时间(时钟周期数) |
| tCAS(tCL?) | 实际延迟时间tCAS(ns)=(CAS*2000)/内存等效频率 |
| tRAS(Row Active Time) | 行地址激活的时间。从一个行地址预充电之后,从激活到寻址再到读取完成所经过的整个时间 tRCD+tCL |
| tRCD(Read-to-Column Delay) | 行地址激活(Active)命令发出之后,内存对行地址的操作所需要的时间。内存中某一行地址被激活时,我们称它为“open page” |
| tRCDR(Read-to-Column Command Delay) | 行地址激活(Active)命令发出之后,内存对行地址的读操作所需要的时间。 |
| tRCDW(Write-to-Column Command Delay) | 行地址激活(Active)命令发出之后,内存对行地址的写操作所需要的时间。 |
| nWR (Write Recovery Time) | time delay between successive write commands to the same row. |
| tRP(RAS Precharge Time) | 前一个行地址操作完成并在行地址关闭(page close)命令发出之后,准备对同一个bank中下一个行地址进行Active操作需要的时间(在对同一个bank的多个不同的行地址进行操作时影响才大) |
| CR(Command Rate) | 首命令延迟。是指从选定bank之后到可以发出行地址激活命令所经过的时间。(如果CPU所需要的数据都在内存的一个行地址上,就不需要进行重复多次的bank选择,CR的影响就很小) |
| Tccd | is the minimum amount of time between column operations |
| tRPRE | The minimum pulse width of READ preamble |
| tRPST | The minimum pulse width of READ postamble |
XMP时序都没有介绍
不同的DRAM。随着频率提升,CL周期也同步提升,但是最后算出来的CL延迟时间却差不多(5~15ns)。其实当下memory的频率宽度过剩,integrated memory controller (IMC)才是瓶颈
在列信号之前还有行信号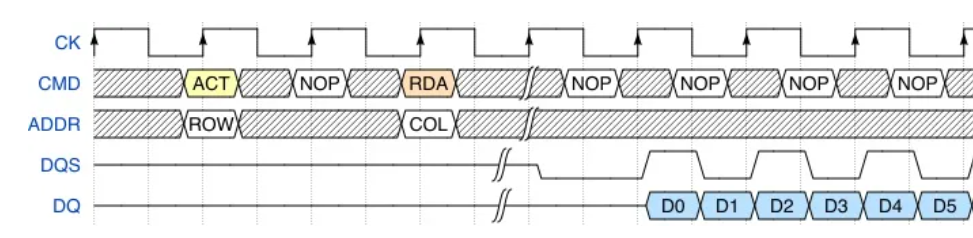
如何连续两次访问同一行的不同列,则之间不需要额外的切换行信号。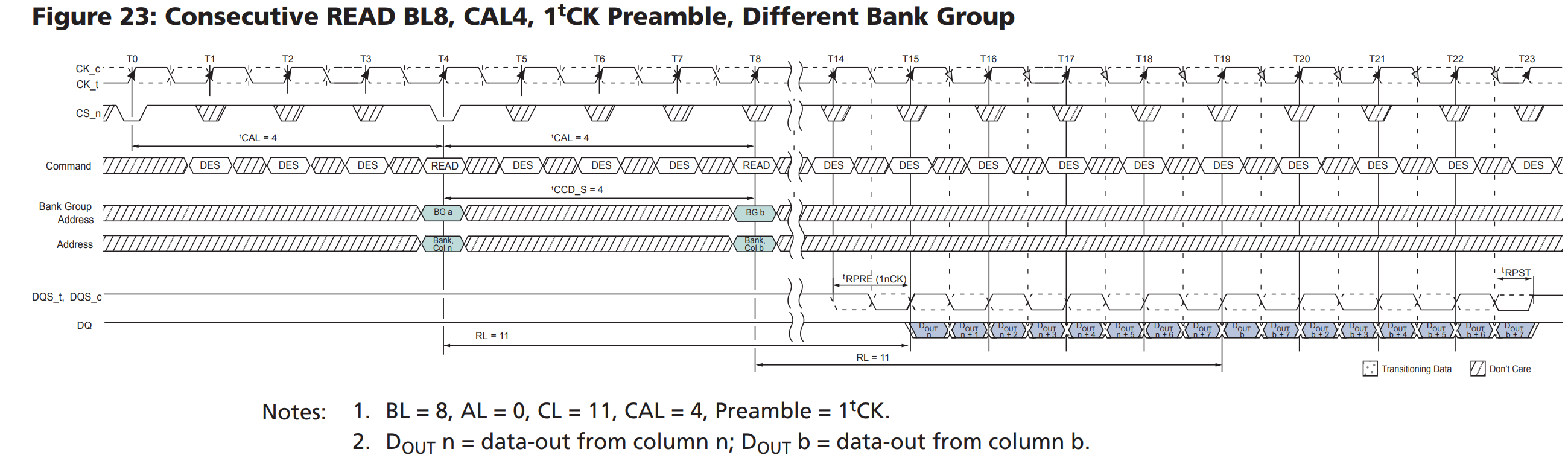
参考文献
https://zhuanlan.zhihu.com/p/52272990