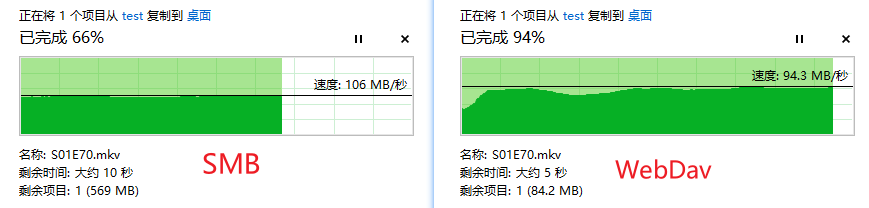
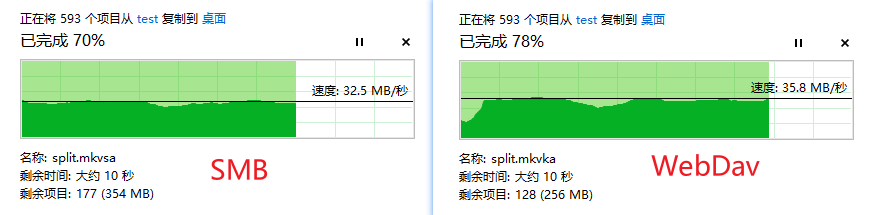
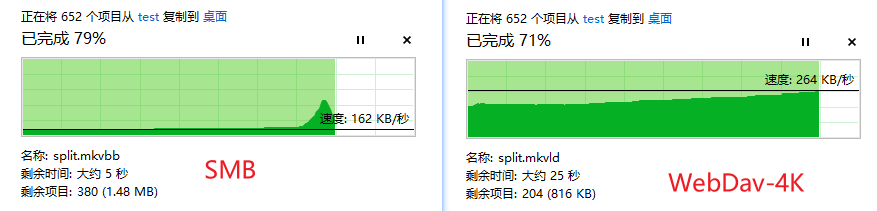
FTP简介
FTP是File Transfer Protocol(文件传输协议)的缩写,用来在两台计算机之间互相传送文件。相比于HTTP,FTP协议要复杂得多。复杂的原因,是因为FTP协议要用到两个TCP连接,一个是命令链路,用来在FTP客户端与服务器之间传递命令;另一个是数据链路,用来上传或下载数据。
主动与被动模式
FTP协议有两种工作方式:PORT方式和PASV方式,中文意思为主动式和被动式。
区别主要在于数据通道的建立方式:
- 主动模式:服务器向客户端敲门,然后客户端开门
- 在主动模式中,客户端向服务器发送一个随机端口号,服务器再用这个端口号和客户端建立数据通道。这样,服务器需要知道客户端的 IP 地址和端口号,并且能够穿透客户端的防火墙。
- 如果通过代理上网的话,就不能用主动模式,因为服务器敲的是上网代理服务器的门,而不是敲客户端的门
- 客户端也不是轻易就开门的,因为有防火墙阻挡,除非客户端开放大于1024的高端端口
- 被动模式:客户端向服务器敲门,然后服务器开门
- 在被动模式中,服务器向客户端发送一个随机端口号,客户端再用这个端口号和服务器建立数据通道。这样,客户端不需要公开自己的 IP 地址和端口号,并且只需要打开出站连接的防火墙。
ftp命令行登录
1 | ftp ip |
常用命令
- 下载文件通常用get和mget这两条命令。
- 上传文件put和mput
- 断开连接bye
ftp空间
但是这个是当前目录的文件,不包括文件夹
1字节=1B,1024B=1KB
Ubuntu ftp服务器部署
安装
1
sudo apt install vsftpd # 安装
配置文件 /etc/vsftpd/vsftpd.conf
1
2
3local_enable=YES # 是否允许本地用户访问
local_root=/home/kaikai_ftp/ftpdir # 自定义上传根目录
write_enable=YES # 允许用户修改文件权限vsftpd虚拟用户
运行
1
2
3
4
5
6
7systemctl restart vsftpd.service
重启
sudo service vsftpd start
开机启动
sudo systemctl enable vsftpd
查看运行情况
sudo service vsftpd status
vsftpd虚拟用户
虚拟用户
- 虚拟用户,只对ftp有效的用户。这些用户不可以登录Linux系统,只可以登录ftp服务器。其实就是一个本地用户映射成多个只对ftp服务器有效的虚拟用户。虚拟用户可以有自己的ftp配置文件,因此通常利用虚拟用户来对ftp系统的不同用户制定不同的权限,以达到安全控制的目的。与虚拟用户有关的设置以guest_开头。
- 匿名用户,也就是不需要输入密码就可登录ftp服务器的用户,这个用户名通常是ftp或anonymous; 与匿名用户有关的设置多以 anon_选项开头。
- 本地用户,也就是你Linux系统上可登录到系统的用户,这些用户是在系统上实实在在存在的用户。通常会有自己的home,shell等。与本地用户有关的设置多以local_开头或包含local_的选项。
●所有虚拟用户会统一映射为一个指定的系统帐号:访问共享位置,即为此系统帐号的家目录
●各虚拟用户可被赋予不同的访问权限,通过匿名用户的权限控制参数进行指定
具体命令
- 创建用户数据库文件
1 | vim /etc/vsftpd/vusers.txt |
- 文件需要被加密编码为hash格式奇数行为用户名,偶数行为密码
1 | sudo apt-get install db-util # install db_load |
- 创建用户和访问FTP目录
1 | sudo useradd -d /data/ftproot -s /sbin/nologin -r vuser |
创建pam配置文件
1
2
3vim /etc/pam.d/vsftpd.db
auth required pam_userdb.so db=/etc/vsftpd/vusers
account required pam_userdb.so db=/etc/vsftpd/vusers指定pam配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13vim /etc/vsftpd/vsftpd.conf
pam_service_name=vsftpd.db
userlist_enable=YES
guest_enable=YES #所有系统用户都映射成guest用户
guest_username=vuser #配合上面选项才生效,指定guest用户
user_config_dir=/etc/vsftpd/vusers.d/ #虚拟用户设置独立的配置文件
write_enable=YES
anonymous_enable=NO # 匿名访问是否允许,默认不要开启
local_enable=YES # 是否允许本地用户访问
local_root=/home/shaojiemike/ftpdir # 自定义上传根目录
虚拟用户设置独立的配置文件
指定各用户配置文件存放的路径
1 | vim /etc/vsftpd/vsftpd.conf |
创建各个用户的配置文件存放路径,配置文件的文件名需要与用户名一致。
没有独立配置文件的虚拟用户会遵守/etc/vsftpd/vsftpd.conf这个主配置文件的权限配置。
1 | mkdir /etc/vsftpd/vusers.d/ |
建立目录,更改目录的所有者与所属组
1 | mkdir /tmp/vutest_d |
Linux-PAM 的配置文件
PAM 的各个模块一般存放在 /lib/security/ 或 /lib64/security/ 中,以动态库文件的形式存在,文件名格式一般为 pam_*.so。
PAM 的配置文件可以是 /etc/pam.conf 这一个文件,也可以是 /etc/pam.d/ 文件夹内的多个文件。如果 /etc/pam.d/ 这个文件夹存在,Linux-PAM 将自动忽略 /etc/pam.conf。
/etc/pam.conf 类型的格式如下:
1
服务名称 工作类别 控制模式 模块路径 模块参数
/etc/pam.d/ 类型的配置文件通常以每一个使用 PAM 的程序的名称来命令。比如 /etc/pam.d/su,/etc/pam.d/login 等等。还有些配置文件比较通用,经常被别的配置文件引用,也放在这个文件夹下,比如 /etc/pam.d/system-auth。这些文件的格式都保持一致:
1
工作类别 控制模式 模块路径 模块参数
需要进一步的研究学习
Please read the vsftpd.conf.5 manual page to get a full idea of vsftpd’s capabilities.
遇到的问题
1 | 530 Login incorrect. |
尝试改shell,但首先不是这个问题
1
2
3cat /etc/shells #没有/sbin/nologin
sudo usermod -s /bin/bash vuser
cat /etc/passwd #shell改好了查看报错

我以为我是修改错文件了,但是好像没怎么简单添加
1
2guest_enable=YES # 开启虚拟用户
guest_username=vuser # FTP虚拟用户对应的系统用户,即第四步添加的用户报错

后来发现原因是,变量这一行不要加注释
guest_enable=YES# 开启虚拟用户只改pam的路径为pam.db
报错

这很明显是没有指定用户
实际问题
参考文献
https://www.jianshu.com/p/ac3e7009a764