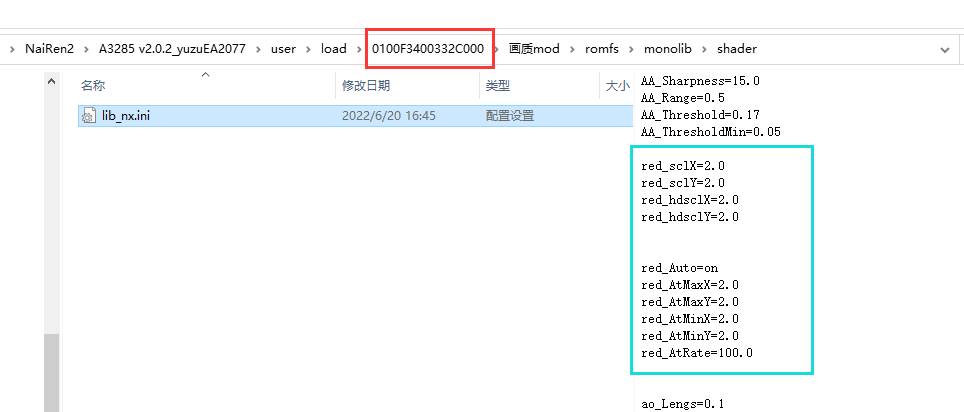
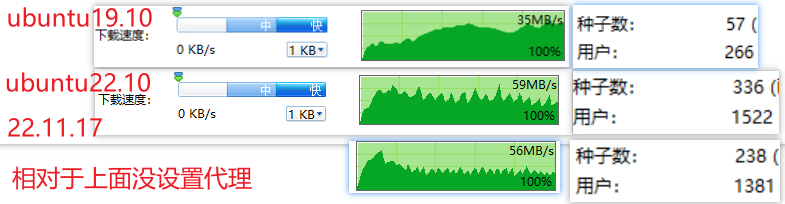
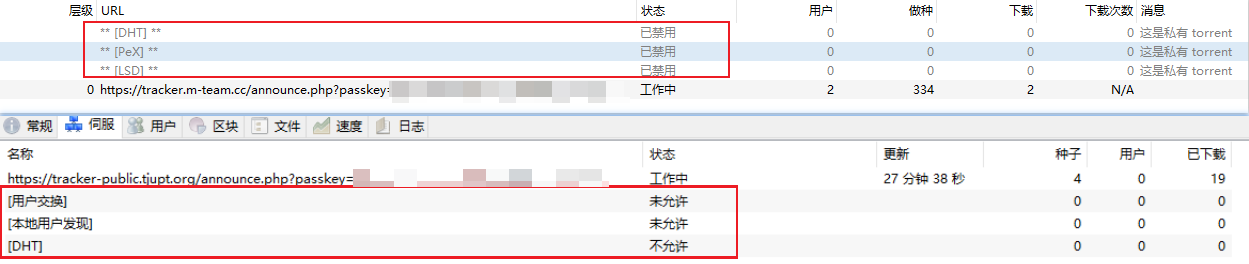
为了使得原本wg正常运行,10: from all lookup main suppress_prefixlength 1
假如warp_out是defualt规则,该项也是为了防止失联。
创建warp_out的空路由表1000: from all lookup warp_out,优先级1000
1 2 3 4 5 6 7 8
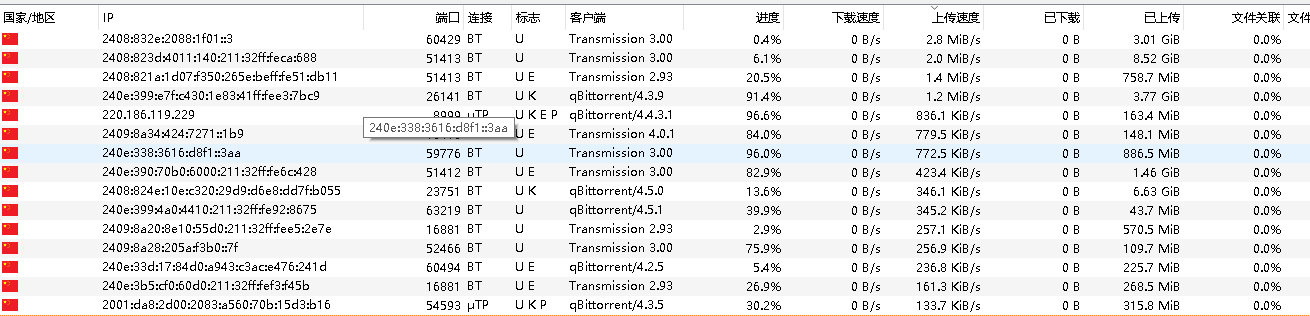
root@tsjOp:~/warp# ip rule 0: from all lookup local 3: from 114.214.233.141/22 iif eth1 lookup wan 3: from 172.16.0.2 iif warp lookup warp 10: from all lookup main suppress_prefixlength 1 1000: from all lookup warp_out 32766: from all lookup main 32767: from all lookup default
# root @ snode0 in /etc/systemd/system [17:57:48] $ journalctl -u webhook.service -- Logs begin at Mon 2022-06-06 15:54:50 CST, end at Tue 2022-06-28 17:57:50 CST. -- Jun 28 17:30:53 snode0 systemd[1]: Started Webhook receiver for GitHub.
问题
1 2 3 4 5 6 7 8 9 10
$ systemctl reload webhook.service ==== AUTHENTICATING FOR org.freedesktop.systemd1.manage-units === Authentication is required to reload 'webhook.service'. Multiple identities can be used for authentication: 1. Jun Shi (shijun) 2. Shaojie Tan (shaojiemike) Choose identity to authenticate as (1-2): 2 Password: ==== AUTHENTICATION COMPLETE === Failed to reload webhook.service: Job type reload is not applicable for unit webhook.service.
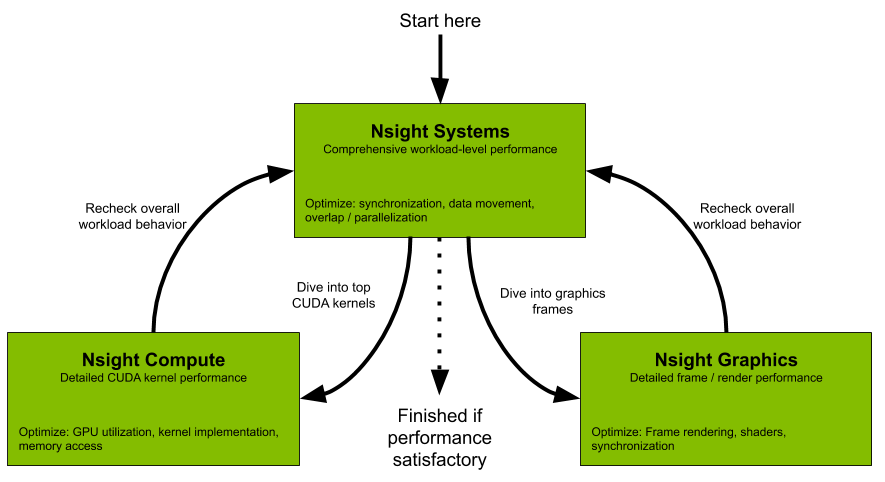
All developers should start with Nsight Systems to identify the largest optimization opportunities. Nsight Systems provides developers a system-wide visualization of an applications performance. Developers can optimize bottlenecks to scale efficiently across any number or size of CPUs and GPUs; from large servers to our smallest SoC. For further optimizations to compute kernels developers should use Nsight Compute or to further optimize a graphics workloads, use Nsight Graphics.
Nsight Compute
Nsight Compute is an interactive kernel profiler for CUDA applications. It provides detailed performance metrics and API debugging via a user interface and command line tool. Nsight Compute also provides customizable and data-driven user interface and metric collection that can be extended with analysis scripts for post-processing results.
Nsight Graphics
Nsight Graphics is a standalone application for the debugging, profiling, and analysis of graphics applications on Microsoft Windows and Linux. It allows you to optimize the performance of your Direct3D 11, Direct3D 12, DirectX Raytracing 1.1, OpenGL, Vulkan, and KHR Vulkan Ray Tracing Extension based applications.
Install Nsight local
check the perf config To collect thread scheduling data and IP (instruction pointer) samples
cat /proc/sys/kernel/perf_event_paranoid
如果大于2,临时改变 sudo sh -c 'echo 2 >/proc/sys/kernel/perf_event_paranoid'重启会重置
永久修改 sudo sh -c 'echo kernel.perf_event_paranoid=2 > /etc/sysctl.d/local.conf'
GPU Metrics [0]: The user running Nsight Systems does not have permission to access NVIDIA GPU Performance Counters on the target device. For more details, please visit https://developer.nvidia.com/ERR_NVGPUCTRPERM - API function: NVPW_GPU_PeriodicSampler_GetCounterAvailability(¶ms) - Error code: 17 - Source function: static std::vector<unsigned char> QuadDDaemon::EventSource::GpuMetricsBackend::Impl::CounterConfig::GetCounterAvailabilityImage(uint32_t) - Source location: /dvs/p4/build/sw/devtools/Agora/Rel/DTC_F/QuadD/Target/quadd_d/quadd_d/jni/EventSource/GpuMetricsBackend.cpp:609
Profile 速度
大致2到3倍时间:默认采样率,单独运行52s, Nsight-sys模拟需要135s。
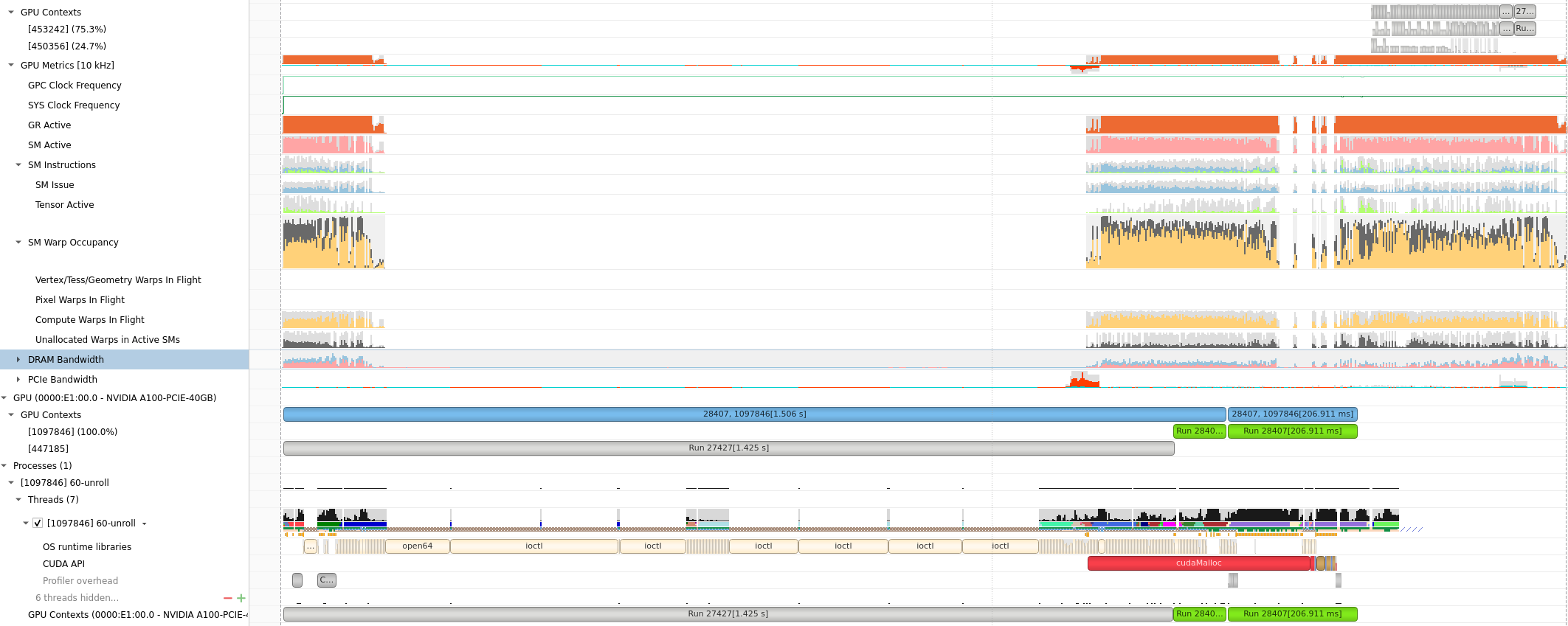
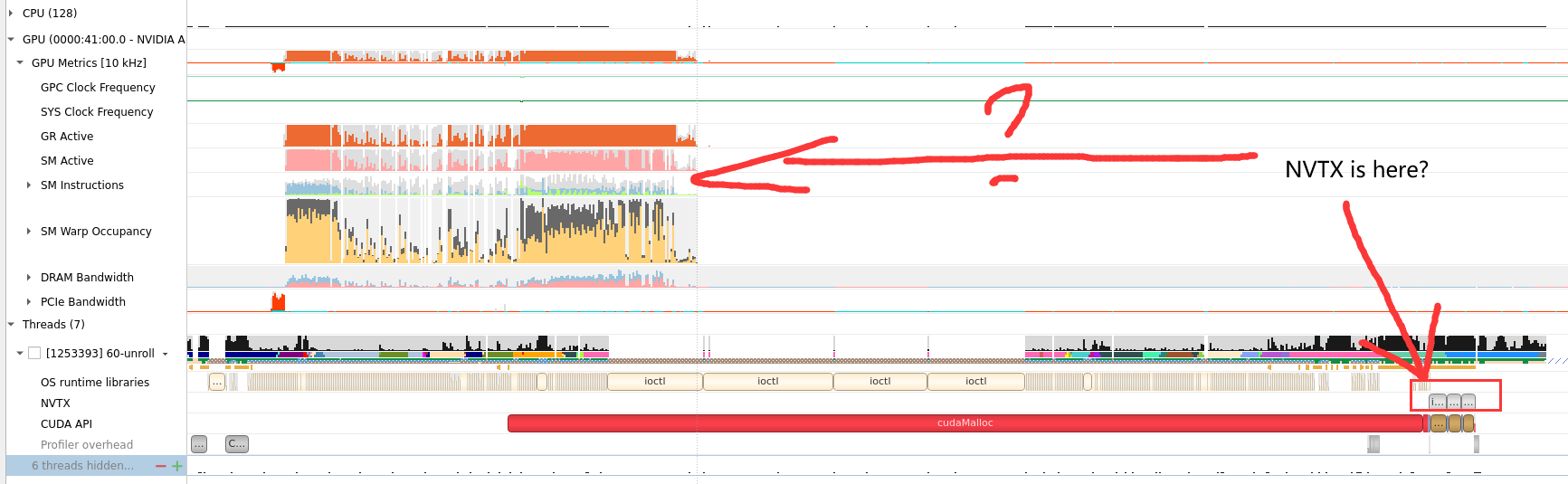
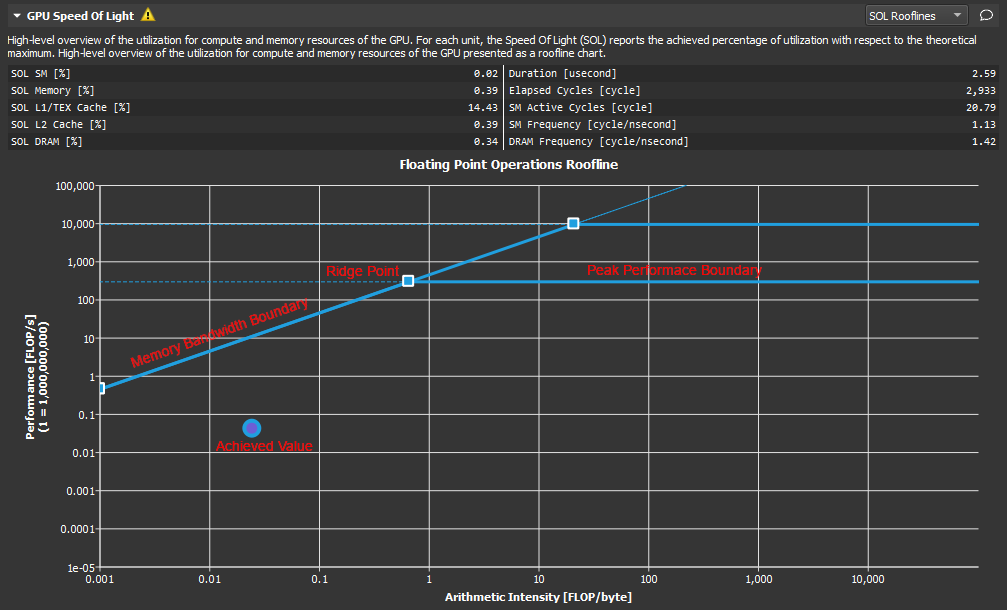
HPC APP : PCIE, GPU DRAM Bandwidth, Warp
GPU Metrics选项能看出 PCIE, GPU DRAM Bandwidth, Warp的使用情况。
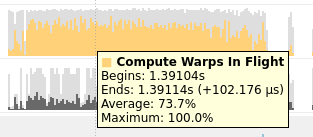
Compute Warps in Flight
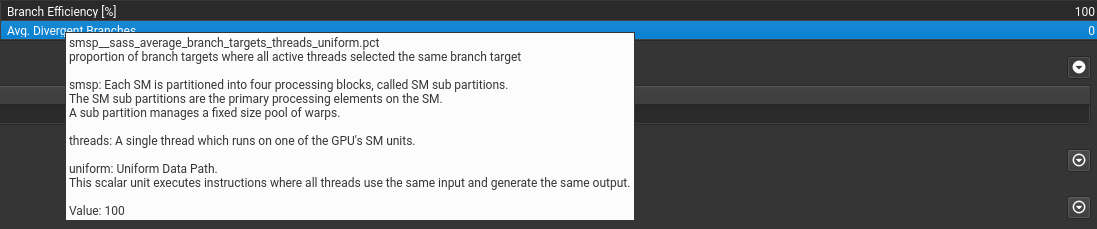
将鼠标放在上面会有具体的数值或者名称的解释,(正在使用的Warps)
Unallocated Warps in Active SMs
Definition: This metric represents the number of warps that are not actively executing but are assigned to an active Streaming Multiprocessor (SM).
Interpretation: In CUDA, SMs are the fundamental processing units on the GPU. Each SM can execute multiple warps concurrently. “Unallocated Warps in Active SMs” indicates the number of warps that are ready to be scheduled on an SM but are currently waiting due to resource contention or other factors. A high number may suggest that there is room for additional work but available resources are not fully utilized.
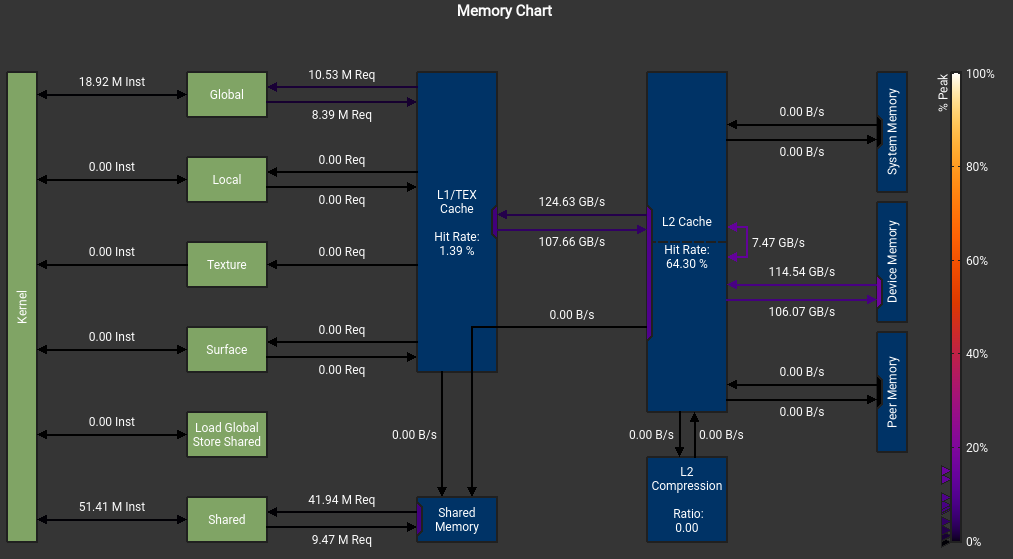
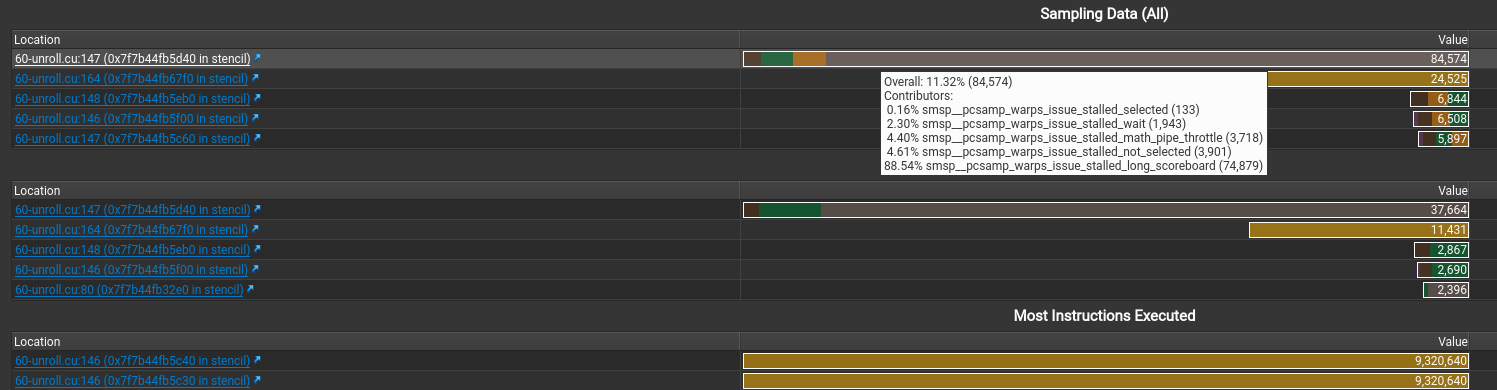
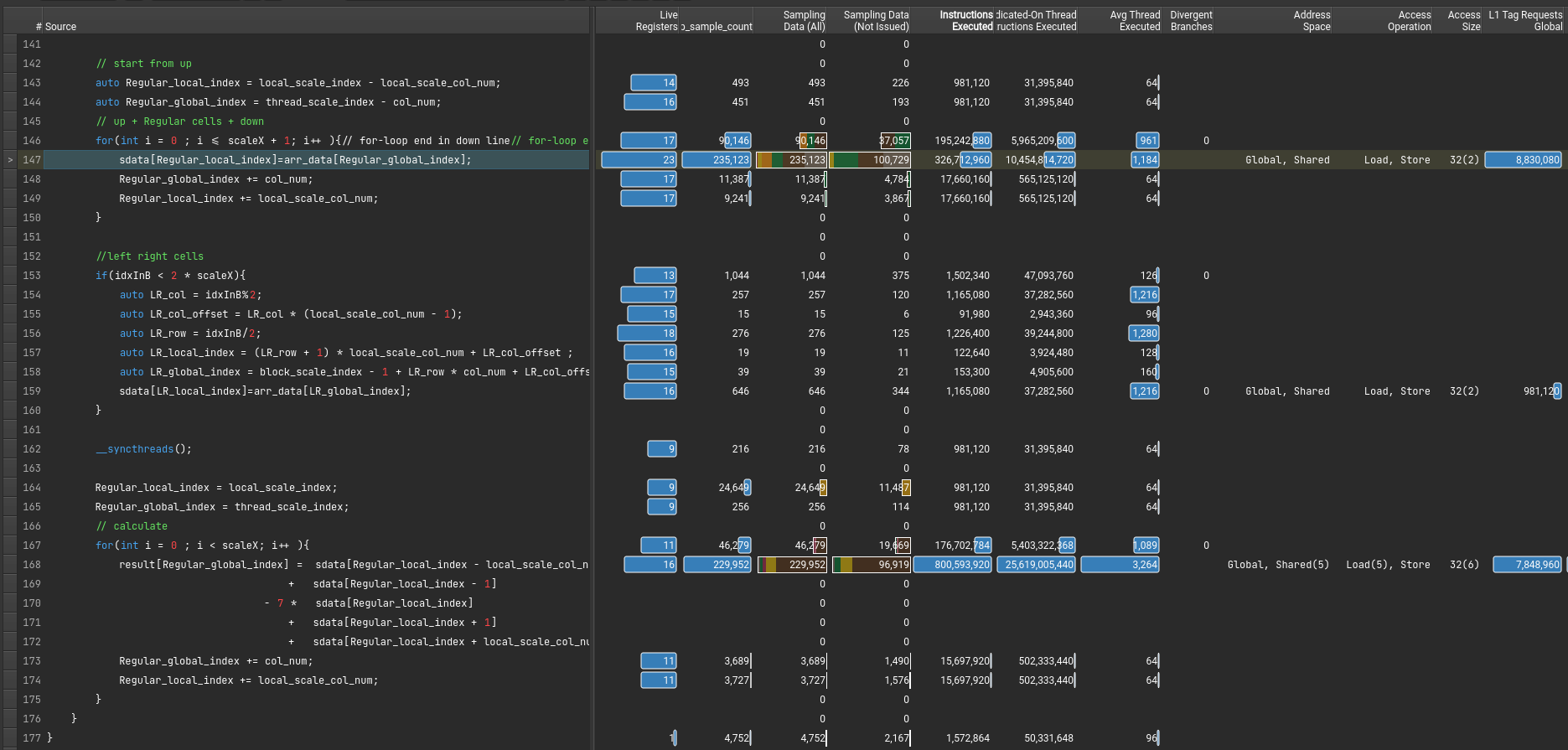
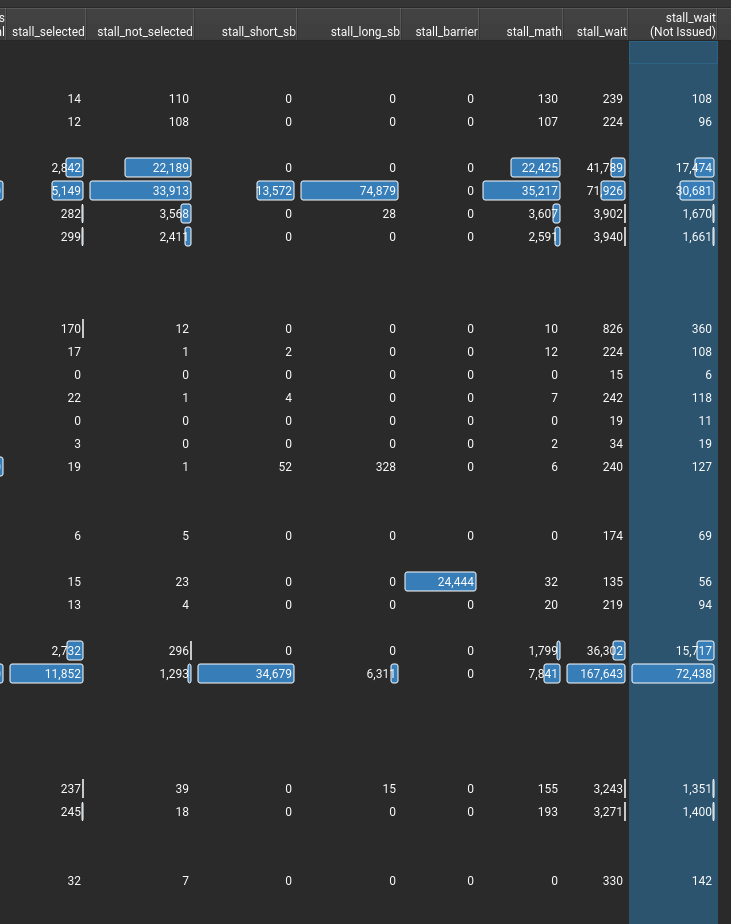
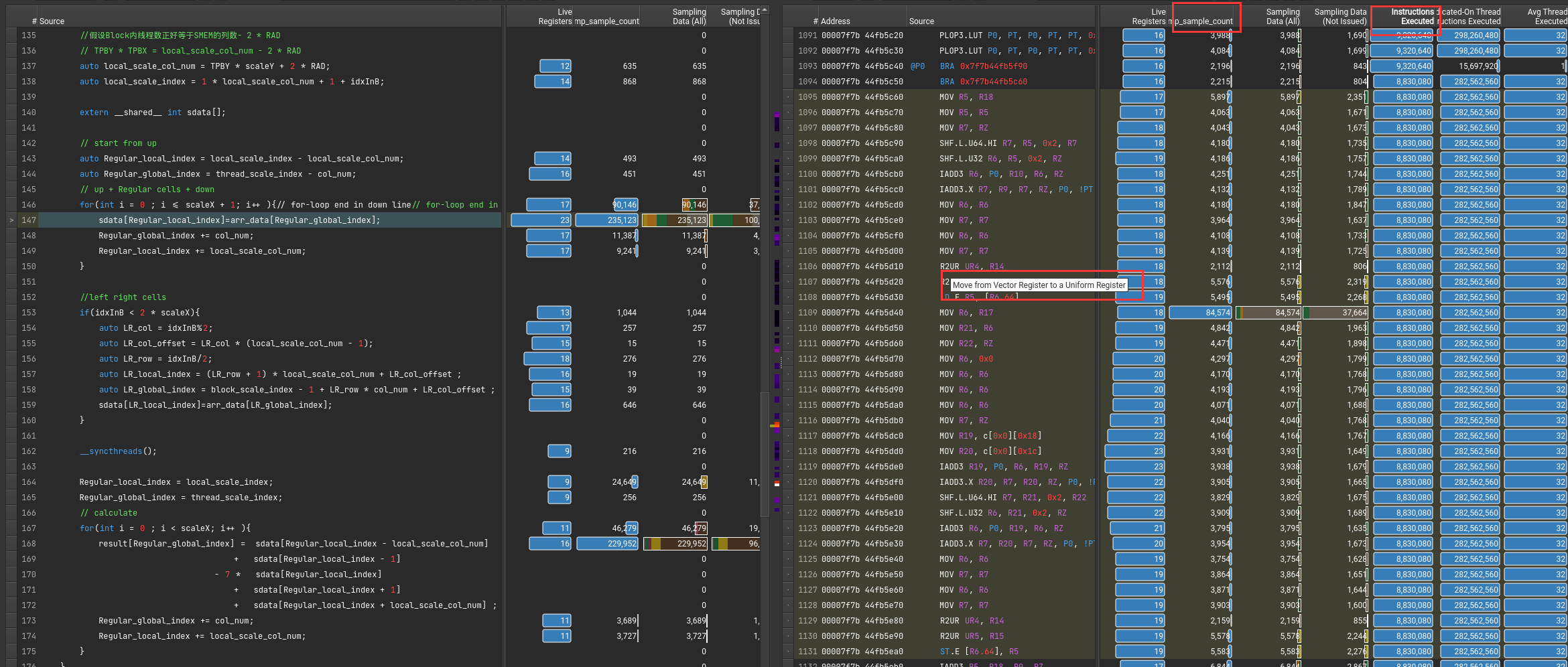
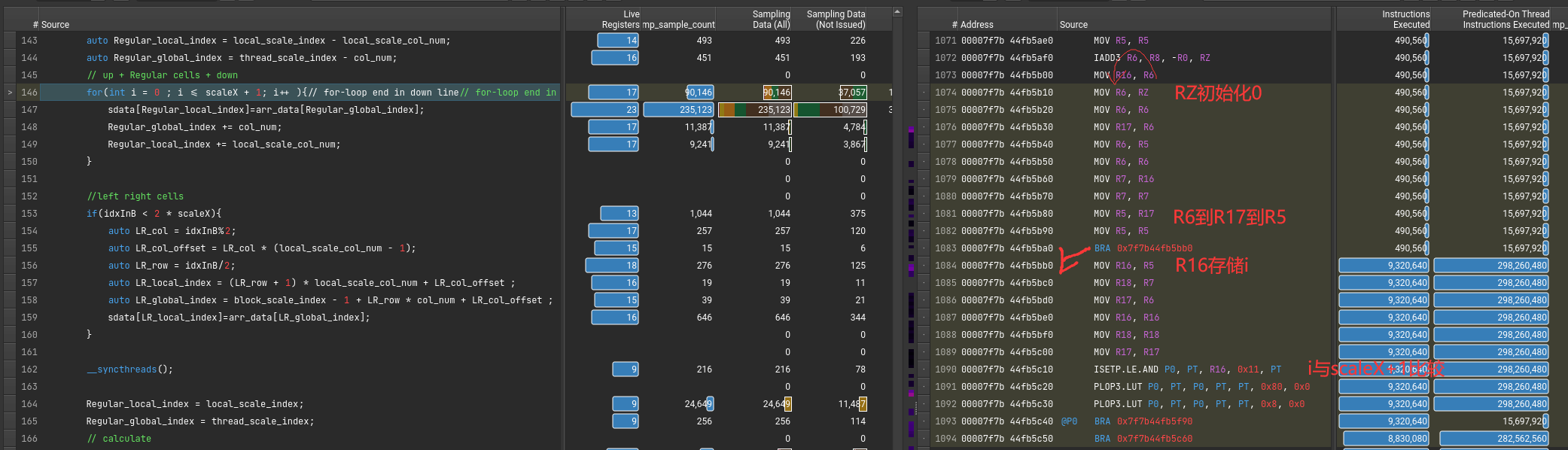
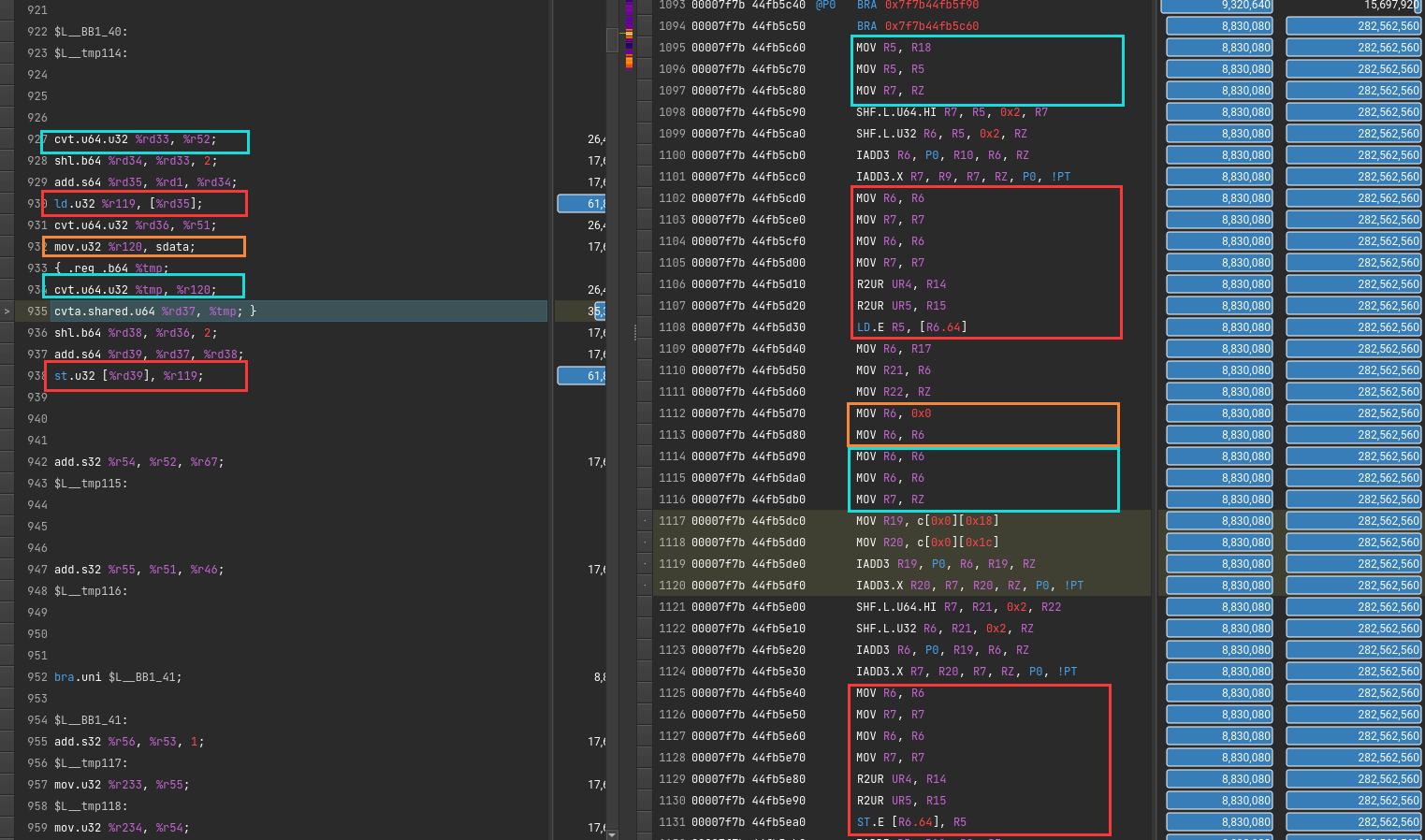
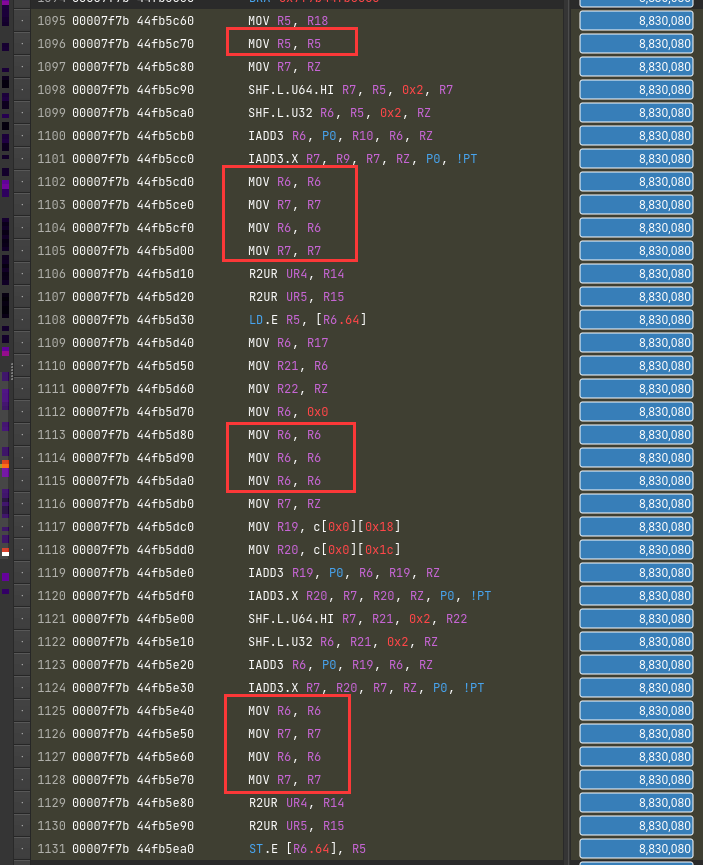
这个错误也是令人迷惑 The memory access pattern for loads from L1TEX to L2 is not optimal. The granularity of an L1TEX request to L2 is a 128 byte cache line. That is 4 consecutive 32-byte sectors per L2 request. However, this kernel only accesses an average of 3.7 sectors out of the possible 4 sectors per cache line. Check the Source Counters section for uncoalesced loads and try to minimize how many cache lines need to be accessed per memory request.
Warning: Failed to get OpenGL version. OpenGL version 2.0 or higher is required. OpenGL version is too low (0). Falling back to Mesa software rendering. qt.qpa.plugin: Could not load the Qt platform plugin "xcb"in"" even though it was found. This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: offscreen, wayland-egl, wayland, wayland-xcomposite-egl, wayland-xcomposite-glx, xcb.
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "" even though it was found. This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: xcb.
Application could not be initialized! This is likely due to missing Qt platform dependencies. For a list of dependencies, please refer to https://doc.qt.io/qt-5/linux-requirements.html To view missing libraries, set QT_DEBUG_PLUGINS=1 and re-run the application.
按照说明 export QT_DEBUG_PLUGINS=1再次运行, 显示具体问题
1
Cannot load library /staff/shaojiemike/Install/cuda_11.7.0_515.43.04_linux/nsight-compute-2022.2.0/host/linux-desktop-glibc_2_11_3-x64/Plugins/platforms/libqxcb.so: (libxcb-xinput.so.0: cannot open shared object file: No such file or directory)
解决 sudo apt-get install libxcb-xinput0
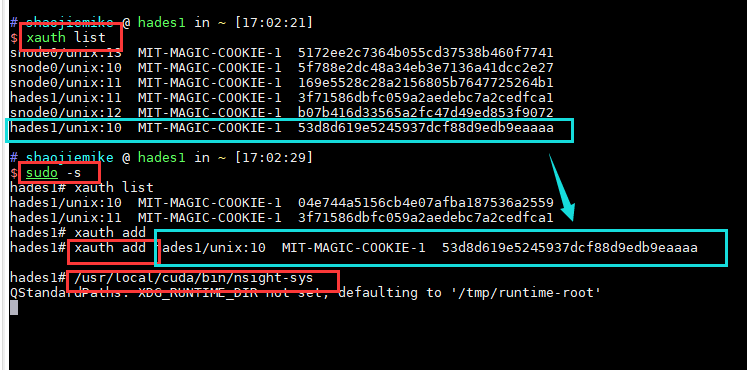
kernel没权限profile
ERR_NVGPUCTRPERM - The user does not have permission to profile on the target device
要用sudo,或者最新的NV
could not connect to display localhost:10.0 under sudo
1 2 3 4 5 6
$ sudo ncu-ui MobaXterm X11 proxy: Authorisation not recognised qt.qpa.xcb: could not connect to display localhost:10.0