上下文切换
- 根据geekculture的博客的说法
- 上下文主要指的是CPU的寄存器状态,状态越多(上下文越多),切换时开销就越大。
- 包括程序计数器(program counters,PC),栈指针SP,通用寄存器等。还有virtual memory mappings, file descriptor bindings, and credentials.虚拟内存映射、文件描述符绑定和凭据?
- 类型可以分成三类
- to do
上下文切换的开销
According to 2007 paper
- direct costs
- The processor registers need to be saved and restored,
- the OS kernel code (scheduler) must execute,
- the TLB entries need to be reloaded,
- and processor pipeline must be flushed
- cache interference cost or indirect cost of context switch.
- context switch leads to cache sharing between multiple processes, which may result in performance degradation.
何时上下文切换
进程或线程的上下文切换可以在多种情况下发生,下面列举了一些常见的情况:
- 抢占调度:当操作系统采用抢占式调度算法时,更高优先级的进程或线程可能会抢占当前运行的进程或线程的CPU时间片,从而导致上下文切换。
- 时间片耗尽:操作系统通常使用时间片轮转算法来分配CPU时间。当进程或线程的时间片用尽时,操作系统会进行上下文切换,将CPU分配给其他进程或线程。
- 阻塞和等待:当一个进程或线程发起阻塞的系统调用(如I/O操作)或等待某个事件发生时,操作系统会将其从运行状态切换到阻塞状态,并切换到另一个可运行的进程或线程。
- 中断处理:当发生硬件中断(如时钟中断、设备中断)或软件中断(如异常、信号),操作系统会中断当前进程或线程的执行,保存其上下文,并转而处理中断服务例程。完成中断处理后,操作系统会恢复中断前的进程或线程的上下文,继续其执行。
- 多核处理器间的迁移:在多核处理器系统中,进程或线程可能会从一个核心切换到另一个核心,以实现负载均衡或遵循其他调度策略。
需要注意的是,上下文切换是操作系统内核的责任,它根据调度策略和内核的算法来管理进程和线程的切换。上下文切换的具体发生时机和行为取决于操作系统的设计和实现。
进程上下文切换 context switch
保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
基本原理
- 由于操作系统的抽象: 进程间需要隔离(地址空间,使用的文件描述符,访问权限等) 和执行状态。
- 所以进程间的切换和通讯会触发内核调度器。
- 正如线程Threads将执行单元与进程分离一样,如果将内存隔离、执行状态和特权分离与进程解耦也有好处。
主要的开销
- 进程的状态越多(上下文越多),切换时开销就越大
- virtual memory mappings, file descriptor bindings, and credentials.虚拟内存映射、文件描述符绑定和凭据?
- 线程就是共享了大部分
- 硬件实现的isolation and privilege separation开销是很小的
- 如果TLB中的页表条目带有地址空间标识符,那么切换上下文只需要一个系统调用和加载一个CPU寄存器就可以完成。
- 也就是说,硬件实现的内存和特权隔离所需要的实际开销是很小的,主要只是: 1. 一个系统调用,通知OS进行上下文切换 2. 加载一个CPU寄存器,该寄存器包含新的地址空间ID 3. TLB中的对应页表条目标记为无效
- 随后的指令访问会自动加载新的地址转换信息到TLB。
进程上下文切换的开销
包括以下几个方面:
- 寄存器保存和恢复:在上下文切换过程中,当前进程的寄存器状态需要保存到内存中,包括程序计数器、堆栈指针、通用寄存器等。而切换到新进程时,之前保存的寄存器状态需要重新加载到寄存器中。
- 缓存的数据一致性:需要确保数据的一致性,通常会通过缓冲区刷新、写回操作或者使用写时复制等技术来保证数据的完整性。
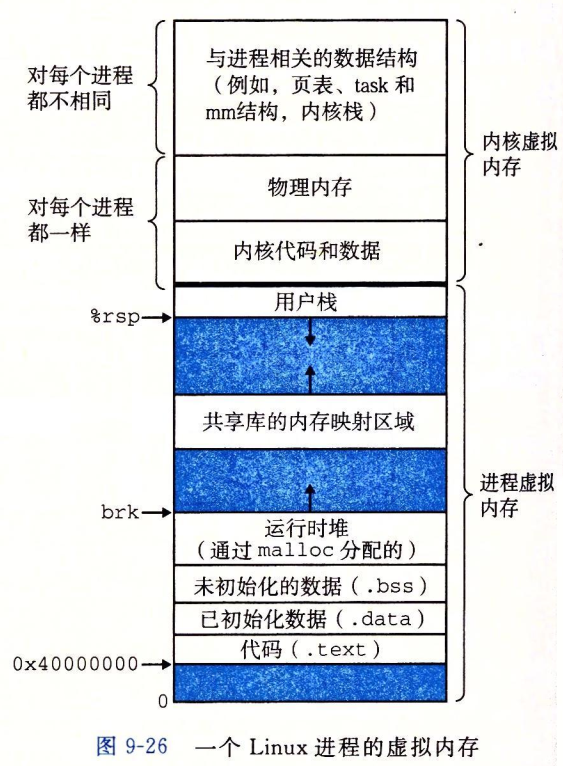
- 内存映射切换:每个进程都有自己的内存空间,包括代码、数据和堆栈。在上下文切换时,需要切换内存映射,将当前进程的内存空间从物理内存中解除映射,同时将新进程的内存空间映射到物理内存中。
- 虚拟内存切换:如果系统使用虚拟内存管理,上下文切换还需要涉及虚拟内存的切换,包括页表的更新和TLB(转换后备缓冲器)的刷新。
- 当虚拟内存更新后,TLB 也需要刷新,内存的访问也会随之变慢。特别是在多处理器系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
- I/O状态切换:当前进程可能涉及到正在进行的I/O操作,如读取或写入文件、网络通信等。在上下文切换时,需要保存和恢复与I/O相关的状态,以确保之后能够正确地继续进行这些I/O操作。
- 调度和管理开销:上下文切换过程本身需要一定的调度和管理开销,包括选择下一个要执行的进程、更新进程控制块、维护就绪队列等。
进程切换到不同核时保持数据一致
- CL-DM:核的私有缓存之间,通过缓存一致性协议 MESI协议
- REG-DM:寄存器的数据:在进程上下文切换的过程中,系统会保存当前进程的状态,包括进程的程序计数器、寄存器、CPU标志寄存器和堆栈指针等等。
线程切换
线程与进程上下文切换开销的不同
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
- 另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
相对于进程上下文切换,线程上下文切换通常更快,这是因为线程共享相同的地址空间和其他资源,因此上下文切换只需要切换线程的执行状态和部分寄存器,省去了一些额外的开销。
以下是线程上下文切换相对于进程上下文切换的一些优势和省去的时间开销:
- 虚拟内存和页表切换:在进程切换时,由于每个进程都有自己独立的虚拟地址空间和页表,切换进程需要切换虚拟内存映射和页表,这会涉及到TLB的刷新和地址空间切换。而线程切换时,线程共享相同的地址空间和页表,因此无需切换虚拟内存和页表,节省了这部分开销。
- 上下文切换时间:进程切换通常需要保存和恢复更多的上下文信息,包括寄存器、堆栈指针、文件描述符表等。而线程切换只需要切换线程的执行状态和部分寄存器,上下文切换时间相对较短。
- 内核数据结构切换:进程切换时,可能涉及到一些内核数据结构的切换和更新,例如进程描述符、文件表等。而线程切换通常只需要更新线程控制块(Thread Control Block,TCB),而无需更新其他内核数据结构,减少了额外的开销。
尽管线程上下文切换相对较快,但仍然需要一些时间和开销,包括以下方面:
- 寄存器切换:线程上下文切换仍然需要保存和恢复部分寄存器的状态,尤其是通用寄存器和程序计数器。
- 栈切换:线程切换时,可能需要切换线程的栈空间,包括用户态栈和内核态栈。这涉及到栈指针的调整和栈的切换。
- 调度开销:线程切换通常是由操作系统的调度器进行调度和管理的,因此线程上下文切换可能涉及到调度算法的执行和调度队列的操作。
需要注意的是,线程上下文切换的快速性是相对于进程上下文切换而言的,具体的开销和时间取决于系统的设计、硬件的性能和操作系统的实现。不同的操作系统和硬件平台可能会有不同的上下文切换开销。
流程与原理
如果要能清晰的回答这一点,需要对OS的页表管理和上下午切换的流程十分了解。
基本概念
Page Table Isolation
Page Table Isolation(页面表隔离)是一种为了解决Meltdown等CPU安全漏洞而提出的硬件优化机制。
其主要思想是将操作系统内核和用户空间的页面表隔离开来,实现内核地址空间与用户地址空间的隔离。
具体来说,Page Table Isolation 主要包括以下措施:
- 为内核空间维护单独的页面表,不与任何用户程序共享。
- 在切换到用户模式时,切换到用户程序自己的页面表。
- 这样内核和用户程序的地址翻译是完全隔离的。
- 当用户程序请求切换到内核模式时,切换回内核专用的页面表。
- 硬件禁止用户模式程序访问内核空间的虚拟地址。
这种机制可以阻止用户程序直接读取内核内存,防止Meltdown类攻击获得内核敏感信息。
当前主流的x86处理器通过在TLB中添加PTI(Page Table Isolation)位实现了此机制,来隔离内核地址空间。这成为了重要的安全优化之一。
页表管理 under PTI
由于PTI的存在,内核维护了两套 页表。
用户态切换的额外开销包括:
- 改变页面表基地址。改变CR3寄存器需要100cycle
- TLBmisses 可能增多,因为用户态和内核态不再共享TLB项,可能导致缓存本地化的下降。
PCID
进程上下文标识符(PCID) 是一项 CPU 功能,它允许我们在切换页表时通过在 CR3 中设置一个特殊位来跳过刷新整个 TLB。这使得切换页表(在上下文切换或内核进入/退出时)更便宜。但是,在支持 PCID 的系统上,上下文切换代码必须将用户和内核条目都从 TLB 中清除。用户 PCID TLB 刷新将推迟到退出到用户空间,从而最大限度地降低成本。有关PCID / INVPCID详细信息,请参阅 intel.com/sdm。
在没有 PCID 支持的系统上,每个 CR3 写入都会刷新整个 TLB。这意味着每个系统调用、中断或异常都会刷新 TLB
不同核上同一个进程的不同线程的Intel PCID 是相同的吗
对于同一个进程的不同线程,当它们运行在不同的物理核心上时,其Intel PCID (进程上下文ID)是相同的。
主要原因如下:
PCID是用于区分不同进程地址空间的标识符。同一进程的线程共享相同的地址空间。
所以操作系统会为同一进程的所有线程分配相同的PCID,无论它们运行在哪个物理核心上。
当线程在物理核心之间迁移时,不需要改变PCID,因为地址空间没有改变。
线程迁移后,新的核心会重新使用原有的PCID加载地址翻译表,而不是分配新的PCID。
这确保了同进程不同线程使用统一的地址映射,TLB内容可以直接重用,无需刷新。
相反,不同进程之间必须使用不同的PCID,才能隔离地址映射,避免TLB冲突。
所以操作系统只会在进程切换时改变PCID,而线程切换保持PCID不变。
综上,对于同一进程的不同线程,无论运行在哪个物理核心,其PCID都是相同的。这使线程可以重用TLB项,是多线程架构的重要优化手段。同进程线程使用统一PCID,不同进程必须使用独立PCID。
PCID vs ASID
PCID(Process Context Identifier)和 ASID(Address Space Identifier)都是用于优化页表切换的技术
- PCID使用一个全局的PCID寄存器,用于标识页表项。而ASID则是在每个页表项中直接包含ASID字段。
- 作用范围:PCID主要用于标识整个页表缓存(TLB)中的页表项。ASID则是用于标识每个页表项。
量化
测量的理论基础
Quantifying the cost of context switch
- 设计实验:对照实验,来剔除时间段内 system call 和 cache degradation的影响。
sched setaffinity()andsched setscheduler()SCHED FIFOand give them the maximum priority.
- repeat to avg/erase the error
1 | # shaojiemike @ hades0 in ~/github/contextSwitch2007 on git:master x [15:59:39] C:10 |
- 阅读代码后时间单位是
us microseconds, 论文里是3.8 us,我们的机器是0.85 us。 - 小问题:这个跨核了吗?
实践测试
Tsuna的2010年的博客
code in https://github.com/tsuna/contextswitch 机器配置在实验结果后。
- syscalls 使用
gettid() - 进程上下文切换使用
futex来切换。包含futex system calls.开销sched_yield让出CPU使用权,强制发生进程切换.
- 线程切换还是使用的
futex.只不过线程通过pthread_create创建来执行函数, 而不是fork - 线程切换只使用
shed_yield().并且设置SCHED_FIFO和sched_prioritysched_yield()函数的作用是使当前进程放弃CPU使用权,将其重新排入就绪队列尾部。但是如果就绪队列中只有这一个进程,那么该进程会立即再次获得CPU时间片而继续执行。必须有其他等待进程且满足调度条件才会真正发生切换。- 如果使用了taskset绑定1个核组,应该就能测量上下文切换。
1 | # snode6 |
如上,snode6应该是550ns
| machine | system calls | process context switches | thread context switches | thread context switches 2 |
|---|---|---|---|---|
| snode6 | 428.6 | 2520.3 | 2606.3(1738.9) | 277.8 |
| snode6 | 427.7 | 2419.8 | 2249.0(2167.9) | 401.1 |
| snode6 | 436.0 | 2327.1 | 2358.8(1727.8) | 329.3 |
| hades | 65.8 | 1806.4 | 1806.4 | 64.6 |
| hades | 65.5 | 1416.4 | 1311.6 | 282.7 |
| hades | 80.8 | 2153.1 | 1903.4 | 64.3 |
| icarus | 74.1 | 1562.3 | 1622.3 | 51.0* |
| icarus | 74.1 | 1464.6 | 1274.1 | 232.6* |
| icarus | 73.9 | 1671.8 | 1302.1 | 38.0* |
| vlab | 703.4 | 5126.3 | 4897.7 | 826.1* |
| vlab | x | x | x | x |
| vlab | 697.1 | 10651.4 | 4476.0 | 843.9* |
| docker |||| | ||||
| docker |||| | ||||
| docker |||| |
说明:
- 同名机器从上到下为:
No CPU affinity和With CPU affinity和With CPU affinity to CPU 0 ()内为。额外添加设置SCHED_FIFO和sched_priority的结果。*意味着没有sudo权限。报错sched_setscheduler(): Operation not permittedx报错taskset: 设置 pid 30727 的亲和力失败: 无效的参数- system calls 理解成 用户态和内核态转换的开销
- 根据博客的数据,虚拟化会使得开销增大2~3倍。
问题:
- 两个thread context的区别是什么?
只使用shed_yield().并且设置SCHED_FIFO和sched_priority - taskset 限制了能运行的核。
- 这个实验测量了 在两个核间的线程切换吗?没绑定应该是多核
- 为什么taskset绑定在同一个核反而变慢了呢。snode6
- timetctxsw2 340 -> 550
- timetctxsw 括号内数据 1712 -> 2225
- 同一个核有资源竞争吗?
- 为什么taskset绑定在同一个核反而变慢了呢。snode6
运行strace -ff -tt -v taskset -a 1 ./timetctxsw2. 应该是不需要strace的,为什么需要记录syscall的信息呢?
1 | # snode6 |
尝试解释不同机器的差异
猜想:
- Intel新产品的硬件确实有特殊设计
1 | shaojiemike @ snode6 in ~/github/contextswitch on git:master o [19:46:27] |
- 软件的不同
| machine | OS | linux kernel | compile | glibc |
|---|---|---|---|---|
| snode6 | Ubuntu 20.04.6 LTS | 5.4.0-148-generic | gcc 9.4.0 | GLIBC 2.31 |
| hades | Ubuntu 22.04.2 LTS | 5.15.0-76-generic | gcc 11.3.0 | GLIBC 2.35-0ubuntu3.1 |
| icarus | Ubuntu 22.04.2 LTS | 5.15.0-75-generic | gcc 11.3.0 | GLIBC 2.35-0ubuntu3.1 |
| vlab | Ubuntu 22.04.2 LTS | 5.15.81-1-pve | gcc 11.3.0 | GLIBC 2.35-0ubuntu3.1 |
glic 版本使用ldd --version获得。OS影响调度算法,内核影响切换机制,编译器影响代码优化,GLIBC影响系统调用开销。
代码分析
sched_setscheduler()是一个用于设置进程调度策略的函数。它允许您更改进程的调度策略以及与之相关的参数。具体来说,sched_setscheduler()函数用于将当前进程(通过getpid()获取进程ID)的调度策略设置为实时调度策略(SCHED_FIFO)。实时调度策略是一种优先级调度策略,它将进程分配给一个固定的时间片,并且仅当进程主动释放 CPU 或者其他高优先级的实时进程出现时,才会进行上下文切换。/sys/bus/node/devices/node0/cpumap存储了与特定 NUMA 节点(NUMA node)关联的 CPU 核心映射信息。cpumap文件中的内容表示与node0相关的 CPU 核心的映射。每个位置上的值表示相应 CPU 核心的状态,常见的取值有:- 0:表示该 CPU 核心不属于
node0。 - 1:表示该 CPU 核心属于
node0。
这种映射信息可以帮助系统管理员和开发人员了解系统的 NUMA 结构,以及每个 NUMA 节点上的 CPU 核心分布情况。通过查看这些信息,可以更好地优化任务和进程的分配,以提高系统的性能和效率。
- 0:表示该 CPU 核心不属于
1 | # shaojiemike @ snode6 in ~/github/contextswitch on git:master x [22:37:41] C:1 |
基于lmbench
根据1996的论文,需要考虑几个方面的内容:
- 传统的测量取最小值当作是两进程只进行上下文切换的开销。作者认为真实应用有更大的working set (cache footprint)影响。
- 在调用context switches时,传统的会包含syscall。比如 write read。这部分pipe overhead varies between 30%
and 300% of the context switch time - to do
http://lmbench.sourceforge.net/cgi-bin/man?keyword=lmbench§ion=8
别人实验结果
- 进程切换实验设计:基于
#include <unistd.h> /pipe()的父子进程的write和readsystem calls- 被1996年文章批判了,syscall开销过大。
- 线程切换实验设计:使用pthread代替fork 其余一样。
论文数据
实验环境:
- 处理器:Intel Xeon X5650 2.66 GHz 6 core CPUs
- 操作系统:FreeBSD 11.0 (amd64)
- 基于信号量semaphore实现会比基于互斥锁mutex快
根据Light-weight Contexts的数据:
- 进程切换:4.25 微秒 (0.86),4250*2.66=11305 cycles
- kernel线程切换:4.12 (0.98)
- user线程切换 - 基于系统调用:1.71 (0.06) ~ 4548 cycles
- 内核态用户态切换开销: ~ 1.5 微秒 ~ 4000 cycles
- user线程切换 - 基于glibc的用户汇编:0.2472 ~ 657 cycles
注意,括号内为十次执行的标准差
解释与组成
- 0.25 微秒 寄存器信息传递
- 2 微秒 虚拟地址映射(TLB flush all?)
- 2 微秒 同步与调度(进程切换)
- 原因是同一进程或不同进程中的两个内核线程之间切换时执行的内核代码基本上是相同的。
需要进一步的研究学习
- 在测量上下文开销的时候,进程和线程的上下午切换开销往往差不多,这是为什么,是因为TLBflush的占比小没有拉开差距吗
在测量上下文切换开销时,进程和线程的切换开销可能会相对接近,这可能是由于以下几个原因:
TLB(Translation Lookaside Buffer)的刷新:TLB是用于高速缓存虚拟地址到物理地址映射的硬件结构。当发生进程或线程切换时,TLB中的缓存项可能需要刷新,以确保新的地址映射有效。虽然线程切换只涉及部分的TLB刷新,但刷新的开销相对较小,因此在总的上下文切换开销中可能没有明显拉开差距。
寄存器和上下文切换:无论是进程切换还是线程切换,都需要保存和恢复一部分寄存器的状态和执行上下文。这部分的开销在进程和线程切换中是相似的。
内核操作和调度开销:无论是进程还是线程切换,都需要涉及内核的操作和调度。这包括切换内核栈、更新调度信息、切换上下文等操作,这些开销在进程和线程切换中也是相似的。
需要注意的是,实际上下文切换的开销是受到多个因素的影响,如处理器架构、操作系统的实现、硬件性能等。具体的开销和差距会因系统的不同而有所差异。在某些情况下,线程切换的开销可能会稍微小一些,但在其他情况下,可能会存在较大的差距。因此,一般情况下,不能简单地将进程和线程的上下文切换开销归为相同或明显不同,具体的测量和评估需要结合实际系统和应用场景进行。
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
PIM 最优调度遇到的问题
- 理解上下文切换的具体过程,linux内核的角度
- 理解相关概念的使用 ASID PCID
- 用户态,内核态的概念,切换的细节以及开销
- 内核态的代码是共享的吗?内核态的操作有什么?
- 各部分的时间占比
- 学会测量时间
参考文献
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
Quantifying The Cost of Context Switch 2007,ExpCS
lmbench: Portable tools for performance analysis,1996 USENIX ATC
Light-weight Contexts: An OS Abstraction for Safety and Performance
参考 kernel 文档