echart
快速上手
- 在github仓库dist目录下拷贝echart.js 和 echart.min.js到index.html目录下。
Vue-ECharts
参考中文文档
1 | sudo apt-get install npm |
实践
简单柱状图
1 | option = { |
需要进一步的研究学习
暂无
遇到的问题
暂无
参考中文文档
1 | sudo apt-get install npm |
1 | option = { |
暂无
暂无
1 | Disassembly of section .plt: |
.plt节主要实现了使用过程链接表(Procedure Linkage Table)实现延迟绑定的功能。
问题:objdump 程序 有许多 类似 <.omp_outlined..16>: 的函数,但是main函数里并没有调用。实际openmp是怎么执行这些代码的呢?
在使用了OpenMP指令的C/C++程序编译后,编译器会自动生成一些名为.omp_outlined.的函数。这些函数是OpenMP所需要的运行时支持函数,不是直接在main函数中调用的,其执行方式主要有以下几种:
.omp_outlined.函数创建线程并发布工作。.omp_outlined.函数,在循环分配工作时调用。所以.omp_outlined.函数的执行是隐式通过运行时库触发和调度的,不需要用户代码直接调用。它们是OpenMP实现所必须的,由编译器和运行时库协调完成。用户只需要编写OpenMP指令,不必关心具体的调用细节。
总体来说,这是一种让并行执行透明化的实现机制,减少了用户的工作量。
不同平台不同,有GOMP_parallel_start开头的。也有如下x86平台的
1 | 405854: 48 c7 84 24 a0 00 00 movq $0x4293b9,0xa0(%rsp) |
这段汇编代码实现了OpenMP中的并行构造,主要执行了以下几个步骤:
__kmpc_fork_call函数,这是OpenMP的runtime库函数,用来并行执行一个函数kmpc fork multiple parallel call?所以这段代码实现了调用OpenMP runtime并行执行一个函数的操作,准备参数,调用runtime API,获取返回值的一个流程。
利用runtime库的支持函数可以实现汇编级别的OpenMP并行性。
各section位置以及含义,参考文档
1 | $ readelf -S bfs.inj |
[ 5] .dynsym 有关One section type, SHT_NOBITS described below, occupies no
space in the file, and its sh_offset member locates the conceptual placement in the
file.
so the number “2d258” remains unchanged.
1 | [25] .data PROGBITS 000000000042e258 0002d258 |
global offset table
This section holds the procedure linkage table. See ‘‘Special Sections’’ in Part 1 and ‘‘Procedure Linkage Table’’ in Part 2 for more information.
Function symbols (those with type STT_FUNC) in shared object files have special significance. When
another object file references a function from a shared object, the link editor automatically creates a procedure linkage table entry for the referenced symbol.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
Linux Executable file: Structure & Running
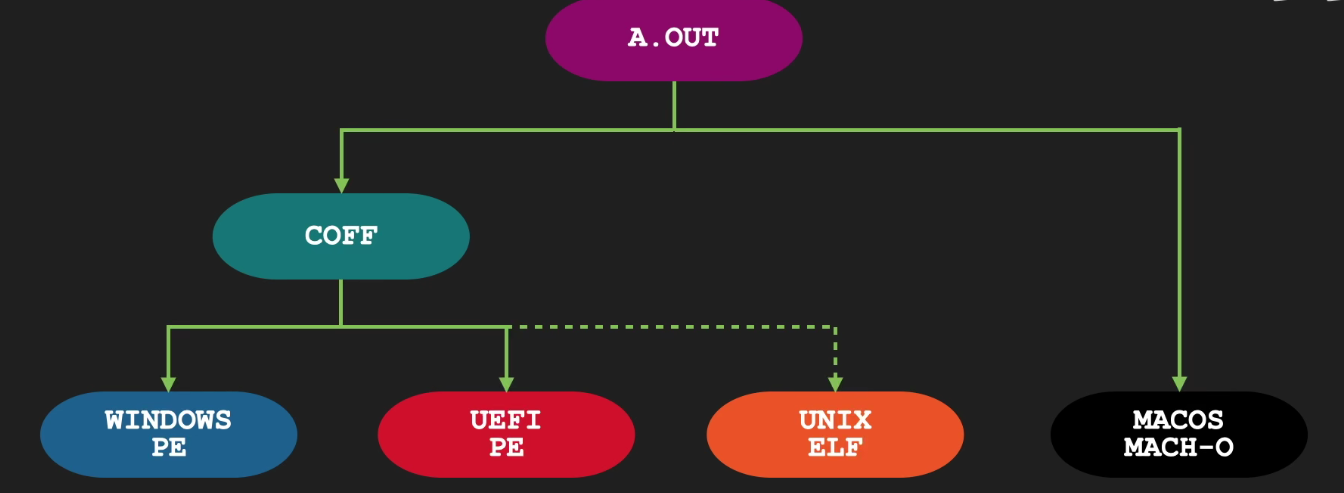

可执行目标文件的格式类似于可重定位目标文件的格式。
.text、.rodata 和 .data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。.init 节定义了一个小函数,叫做 _init,程序的初始化代码会调用它。.rel 节。7.4 可重定位目标文件一节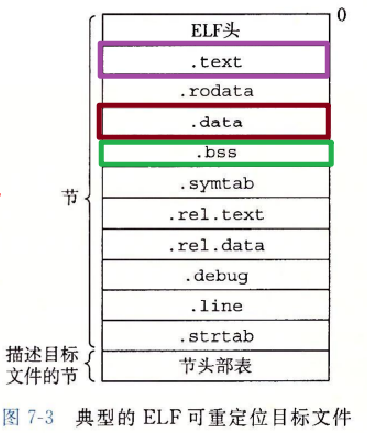
夹在 ELF 头和节头部表之间的都是节。一个典型的 ELF 可重定位目标文件包含下面几个节:
.data 节中,也不岀现在 .bss 节中。.bss 来表示未初始化的数据是很普遍的。它起始于 IBM 704 汇编语言(大约在 1957 年)中“块存储开始(Block Storage Start)”指令的首字母缩写,并沿用至今。.data 和 .bss 节的简单方法是把 “bss” 看成是“更好地节省空间(Better Save Space)” 的缩写。.symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。.symtab 符号表不包含局部变量的条目。-g 选项调用编译器驱动程序时,才会得到这张表。.text 节中机器指令之间的映射。-g 选项调用编译器驱动程序时,才会得到这张表。.symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。每个可重定位目标模块 m 都有一个符号表**.symtab**,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
(出)由模块 m 定义并能被其他模块引用的全局符号。
(入)由其他模块定义并被模块 m 引用的全局符号。
只被模块 m 定义和引用的局部符号。
本地链接器符号和本地程序变量的不同是很重要的。
.symtab 中的符号表不包含对应于本地非静态程序变量的任何符号。有趣的是,定义为带有 C static 属性的本地过程变量是不在栈中管理的。
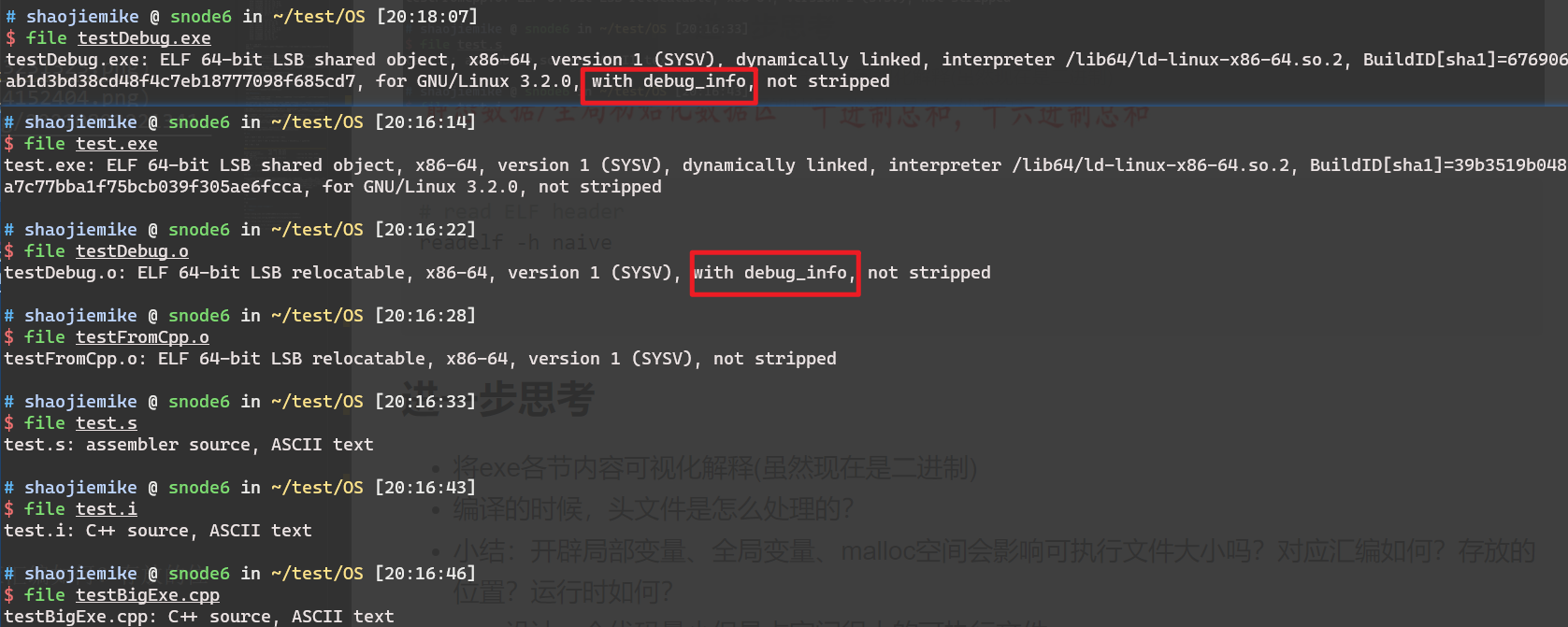
使用命令readelf -s simple.o 可以读取符号表的内容。
示例程序的可重定位目标文件 main.o 的符号表中的最后三个条目。

开始的 8 个条目没有显示出来,它们是链接器内部使用的局部符号。
全局符号 main 定义的条目,
其后跟随着的是全局符号 array 的定义
外部符号 sum 的引用。
type 通常要么是数据,要么是函数。
binding 字段表示符号是本地的还是全局的。
Ndx=1 表示 .text 节

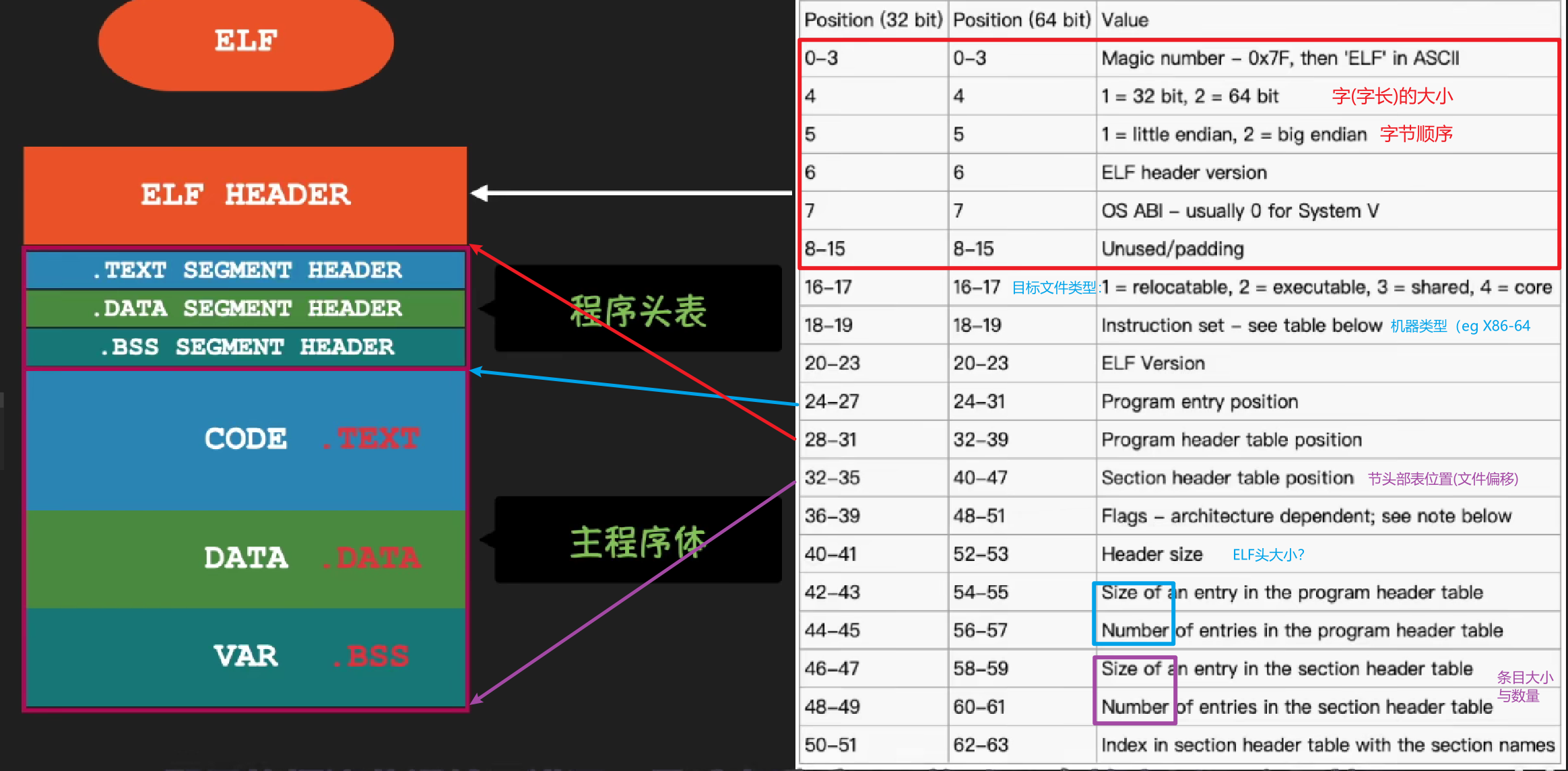
1 | # read ELF header |
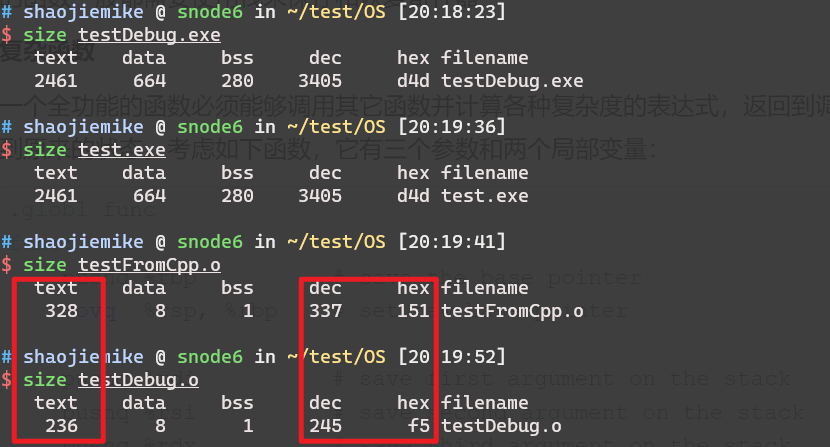
小结:开辟局部变量、全局变量、malloc空间会影响可执行文件大小吗?对应汇编如何?存放的位置?运行时如何?
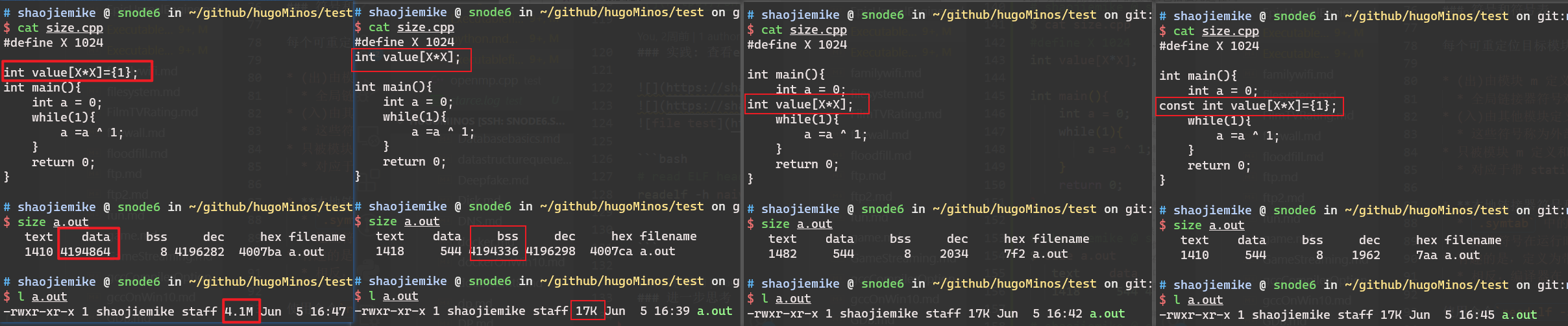
将exe各节内容可视化解释(虽然现在是二进制)
编译的时候,头文件是怎么处理的?
data 与 bbs在存储时怎么区分全局与静态变量
请给出 .rel.text .rel.data的实例分析
线程和进程都可以用多核,但是线程共享进程内存(比如,openmp)
超线程注意也是为了提高核心的利用率,当有些轻量级的任务时(读写任务)核心占用很少,可以利用超线程把一个物理核心当作多个逻辑核心,一般是两个,来使用更多线程。AMD曾经尝试过4个。

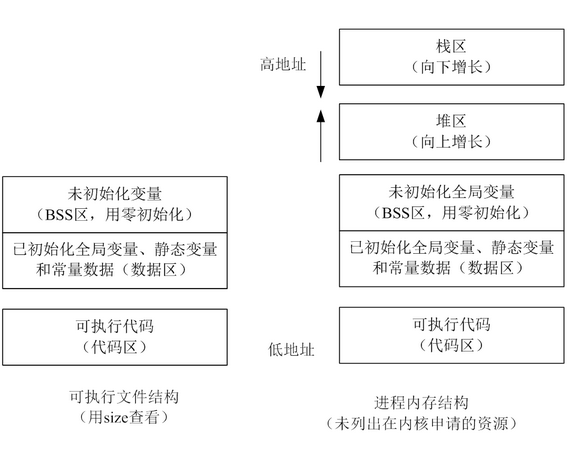
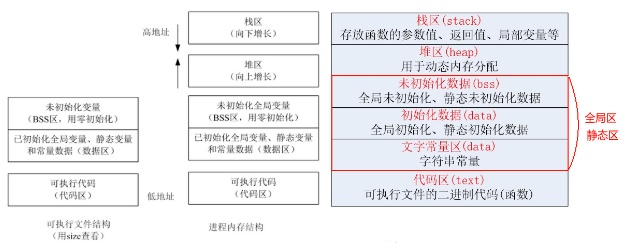
正在运行的程序,叫进程。每个进程都有完全属于自己的,独立的,不被干扰的内存空间。此空间,被分成几个段(Segment),分别是Text, Data, BSS, Heap, Stack。
push pop %ebp 涉及到编译器调用函数的处理方式 application binary interface (ABI).EAX 寄存器中返回,浮点值在 ST0 x87 寄存器中返回。寄存器 EAX、ECX 和 EDX 由调用方保存,其余寄存器由被叫方保存。x87 浮点寄存器 调用新函数时,ST0 到 ST7 必须为空(弹出或释放),退出函数时ST1 到 ST7 必须为空。ST0 在未用于返回值时也必须为空。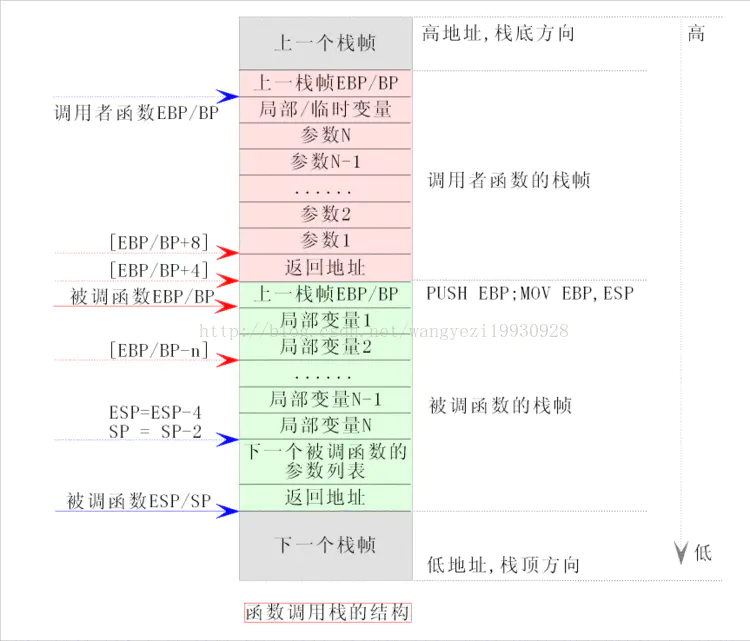
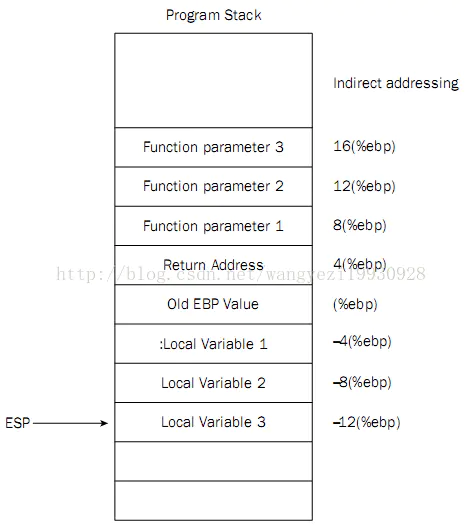
1 | 0000822c <func>: |
arm PC = x86 EIP
ARM 为什么这么设计,就是为了返回地址不存栈,而是存在寄存器里。但是面对嵌套的时候,还是需要压栈。
由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
WIndow系统一般是2MB。Linux可以查看ulimit -s ,通常是8M
栈空间最好保持在cache里,太大会存入内存。持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。
函数参数传递一般通过寄存器,太多了就存入栈内。
栈区(stack segment):由编译器自动分配释放,存放函数的参数的值,局部变量的值等。
局部变量空间是很小的,我们开一个a[1000000]就会导致栈溢出;而全局变量空间在Win 32bit 下可以达到4GB,因此不会溢出。
或者malloc使用堆的区域,但是记得free。
用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
用户堆,每个进程有一个,进程中的每个线程都从这个堆申请内存,这个堆在用户空间。所谓内训耗光,一般就是这个用户堆申请不到内存了,申请不到分两种情况,一种是你 malloc 的比剩余的总数还大,这个是肯定不会给你了。第二种是剩余的还有,但是都不连续,最大的一块都没有你 malloc 的大,也不会给你。解决办法,直接申请一块儿大内存,自己管理。
除非特殊设计,一般你申请的内存首地址都是偶地址,也就是说你向堆申请一个字节,堆也会给你至少4个字节或者8个字节。
堆有一个堆指针(break brk),也是按照栈的方式运行的。内存映射段是存在在break brk指针与esp指针之间的一段空间。
在Linux中当动态分配内存大于128K时,会调用mmap函数在esp到break brk之间找一块相应大小的区域作为内存映射段返回给用户。
当小于128K时,才会调用brk或者sbrk函数,将break brk向上增长(break brk指针向高地址移动)相应大小,增长出来的区域便作为内存返回给用户。
两者的区别是
内存映射段销毁时,会释放其映射到的物理内存,
而break brk指向的数据被销毁时,不释放其物理内存,只是简单将break brk回撤,其虚拟地址到物理地址的映射依旧存在,这样使的当再需要分配小额内存时,只需要增加break brk的值,由于这段虚拟地址与物理地址的映射还存在,于是不会触发缺页中断。只有在break brk减少足够多,占据物理内存的空闲虚拟内存足够多时,才会真正释放它们。
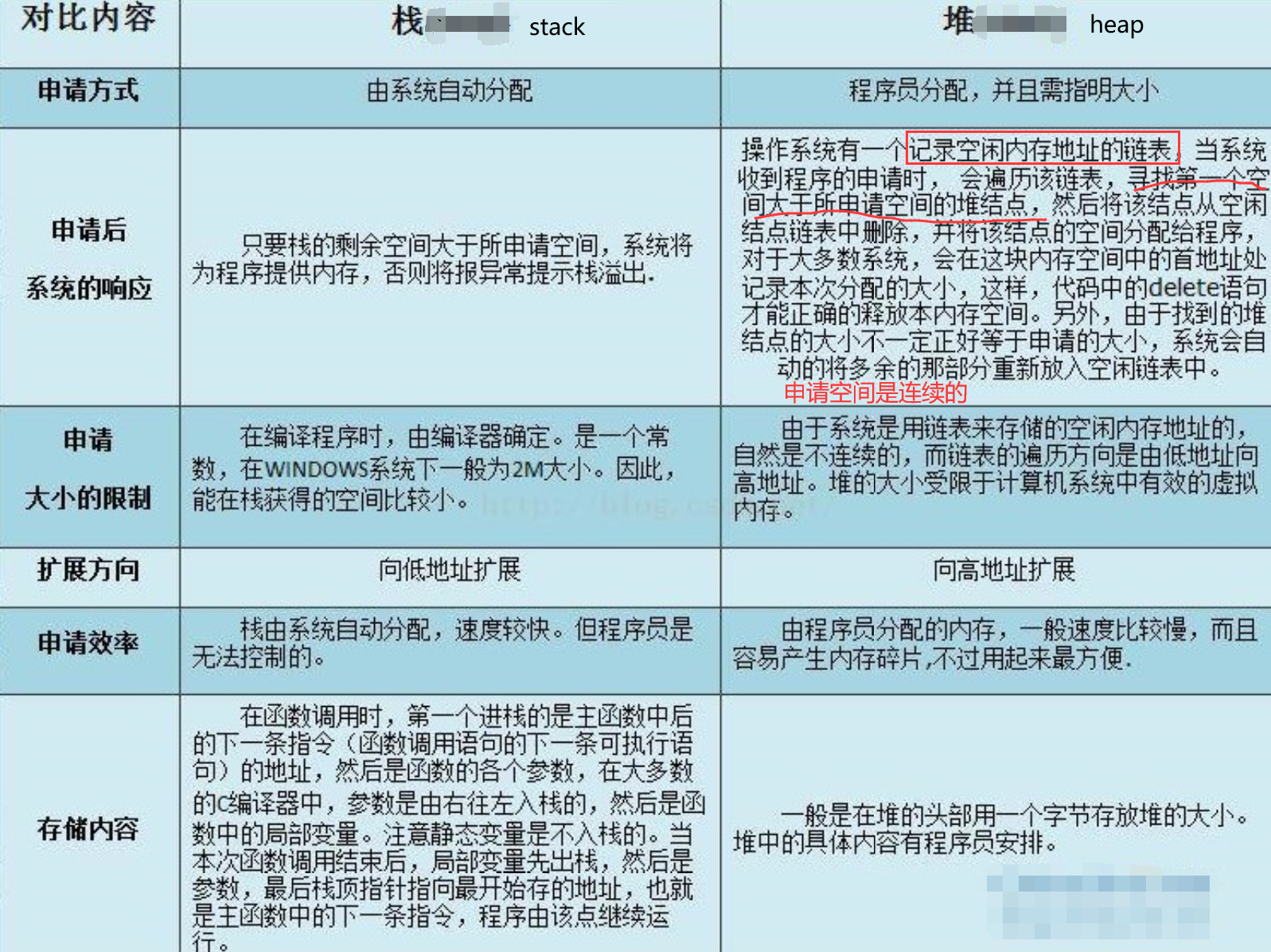
对栈而言,则不存在碎片问题,因为栈是先进后出的队列,永远不可能有一个内存块从栈中间弹出。
用户进程内存空间,也是系统内核分配给该进程的VM(虚拟内存),但并不表示这个进程占用了这么多的RAM(物理内存)。这个空间有多大?命令top输出的VIRT值告诉了我们各个进程内存空间的大小(进程内存空间随着程序的执行会增大或者缩小)。
虚拟地址空间在32位模式下它是一个4GB的内存地址块。在Linux系统中, 内核进程和用户进程所占的虚拟内存比例是1:3,如下图。而Windows系统为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。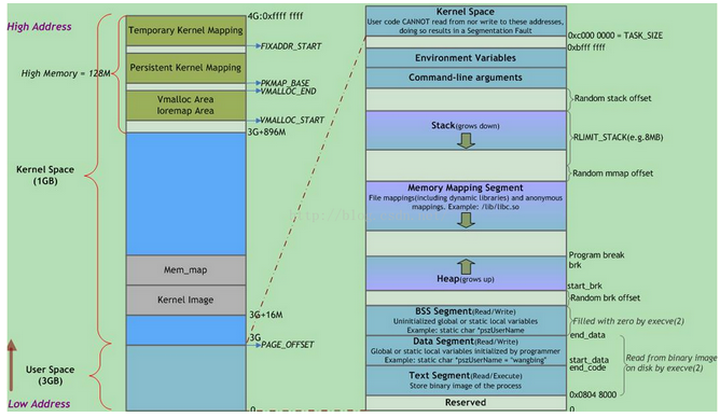
值得注意的是,每个进程的内核虚拟地址空间都是映射到相同的真实物理地址上,因为都是共享同一份物理内存上的内核代码。除此之外还要注意内核虚拟地址空间总是存放在虚拟内存的地址最高处。
其中,用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,灰白区域表示未映射的部分。这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
上图中Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。
execve(2)负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外,execve(2)还会将BSS段清零。
VIRT = SWAP + RES # 总虚拟内存=动态 + 静态
RES >= CODE + DATA + SHR. # 静态内存 = 代码段 + 静态数据段 + 共享内存
MEM = RES / RAM
1 | DATA CODE RES VIRT |
top 里按f 可以选择要显示的内容。
暂无
暂无
Light-weight Contexts: An OS Abstraction for Safety and Performance
https://blog.csdn.net/zy986718042/article/details/73556012
https://blog.csdn.net/qq_38769551/article/details/103099014
https://blog.csdn.net/ywcpig/article/details/52303745
https://zhuanlan.zhihu.com/p/23643064
https://www.bilibili.com/video/BV1N3411y7Mr?spm_id_from=444.41.0.0
1 | ^ 匹配字符串的开头 |
1 | re* 匹配0个或多个的表达式。 |
1 | # find should use \ to represent the (6|12|3) |
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
从字符串的起始位置匹配
1 | re.match(pattern, string, flags=0) |
多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M被设置成 I 和 M 标志:
1 | re.I 使匹配对大小写不敏感 |
1 | matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) |
打印部分内容
1 | matchObj.group() : Cats are smarter than dogs |
返回元组,可以指定开始,与结束位置。
1 | result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10') |
1 |
|
暂无
暂无
https://blog.csdn.net/weixin_39594191/article/details/111611346
GLIBC(GNU C Library)是Linux系统中的标准C库,它提供了许多与程序执行和系统交互相关的功能。GLIBC是应用程序与操作系统之间的接口,提供了许多系统调用的包装函数和其他基础功能,使应用程序能够访问操作系统提供的服务和资源。
GLIBC的主要功能包括:
上下文切换与GLIBC之间没有直接关系。上下文切换是操作系统的概念,是在进程或线程之间切换执行权的过程。GLIBC作为C库,封装了一些系统调用和基础功能,但并不直接参与上下文切换的过程。
然而,GLIBC的性能和效率可以影响上下文切换的开销。GLIBC的实现方式、性能优化以及与操作系统内核的协作方式,可能会对上下文切换的效率产生影响。例如,GLIBC的线程库(如pthread)的设计和性能特性,以及对锁、条件变量等同步原语的实现方式,都可能会影响多线程上下文切换的开销。
因此,尽管GLIBC本身不直接执行上下文切换,但它的设计和实现对于多线程编程和系统性能仍然具有重要的影响。
在PPA。改系统的glibc十分的危险,ssh连接,ls命令等,都需要用到。会导致ssh连接中断等问题。
不推荐,可能会遇到库依赖。比如缺少bison和gawk。详细依赖见
1 | mkdir $HOME/glibc/ && cd $HOME/glibc |
您可以使用以下方法来查找libstdc++库的位置:
g++或gcc命令查找:如果您的系统上安装了g++或gcc编译器,您可以使用以下命令来查找libstdc++库的位置:1 | g++ -print-file-name=libstdc++.so |
或者
1 | gcc -print-file-name=libstdc++.so |
ldconfig命令查找:ldconfig是Linux系统中用于配置动态链接器的命令。您可以运行以下命令来查找libstdc++库的路径:1 | ldconfig -p | grep libstdc++.so |
/usr/lib或/usr/lib64。您可以在这些目录中查找libstdc++的库文件。如果您找到了libstdc++库的路径,您可以将其添加到CMakeLists.txt中的CMAKE_CXX_FLAGS变量中,如之前的回答中所示。
请注意,如果您正在使用的是Clang编译器(clang++),则默认情况下它将使用libc++作为C++标准库,而不是libstdc++。如果您确实希望使用libstdc++,需要显式指定使用-stdlib=libstdc++标志。例如:
1 | set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -stdlib=libstdc++") |
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
LLVM项目开始于一种比Java字节码更低层级的IR,因此,初始的首字母缩略词是Low Level Virtual Machine。它的想法是发掘低层优化的机会,采用链接时优化。
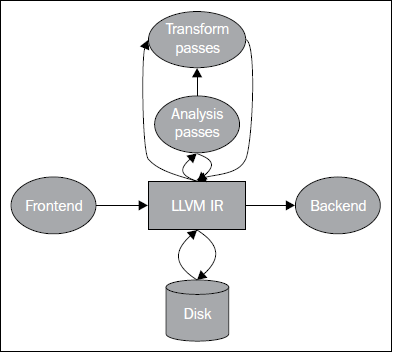
学过编译原理的人都知道,编译过程主要可以划分为前端与后端:
经典的编译器如gcc:在设计上前端到后端编写是强耦合的,你不需要知道,无法知道,也没有API来操作它的IR。
好处是:因为不需要暴露中间过程的接口,编译器可以在内部做任何想做的平台相关的优化。
坏处是,每当一个新的平台出现,这些编译器都要各自为政实现一个从自己的IR到新平台的后端。
LLVM的核心设计了一个叫 LLVM IR 的通用中间表示, 并以库(Library) 的方式提供一系列接口, 为你提供诸如操作IR、生成目标平台代码等等后端的功能。
在使用通用IR的情况下,如果有M种语言、N种目标平台,那么最优情况下我们只要实现 M+N 个前后端。
LVM IR实际上有三种表示:
各种格式是如何生成并相互转换:
| 格式 | 转换命令 |
|---|---|
| .c -> .ll | clang -emit-llvm -S a.c -o a.ll |
| .c -> .bc | clang -emit-llvm -c a.c -o a.bc |
| .ll -> .bc | llvm-as a.ll -o a.bc |
| .bc -> .ll | llvm-dis a.bc -o a.ll |
| .bc -> .s | llc a.bc -o a.s |
对于LLVM IR来说,.ll文件就相当于汇编,.bc文件就相当于机器码。 这也是llvm-as和llvm-dis指令为什么叫as和dis的缘故。

clang实现的前端包括
见 llvm Backend 一文
Clang 是 LLVM 项目中的一个 C/C++/Objective-C 编译器,它使用 LLVM 的前端和后端进行代码生成和优化。它可以将 C/C++/Objective-C 代码编译为 LLVM 的中间表示(LLVM IR),然后进一步将其转换为目标平台的机器码。Clang 拥有很好的错误信息展示和提示,支持多平台使用,是许多开发者的首选编译器之一。同时,Clang 也作为 LLVM 项目的一个前端,为 LLVM 的生态系统提供了广泛的支持和应用。
Clang 的开发起源于苹果公司的一个项目,即 LLVM/Clang 项目。在 2005 年,苹果公司希望能够使用一种更加灵活、可扩展、优化的编译器来替代 GCC 作为其操作系统 macOS (Mac OS X) 开发环境的默认编译器。由于当时的 GCC 开发被其维护者们认为变得缓慢和难以维护,苹果公司决定开发一款新的编译器,这就是 Clang 诞生的原因。Clang 的开发团队由该项目的创立者 Chris Lattner 领导,他带领团队将 Clang 发展为一款可扩展、模块化、高效的编译器,并成功地将其嵌入到苹果公司的开发工具链 Xcode 中,成为了 macOS 开发环境中默认的编译器之一。
Clang 是一个开源项目,在苹果公司的支持下,Clang 的开发得到了全球各地的开发者们的广泛参与和贡献。现在,Clang 成为了 LLVM 生态中的一个重要组成部分,被广泛地应用于多平台的编译器开发中。
Clang and Clang++ “borrow” the header files from GCC & G++. It looks for the directories these usually live in and picks the latest one. If you’ve installed a later GCC without the corresponding G++, Clang++ gets confused and can’t find header files. In your instance, for example, if you’ve installed gcc 11 or 12.
You can use clang-10 -v -E or clang++-10 -v -E to get details on what versions of header files it’s trying to use.
安装g++-12解决
github/tools目录下有许多实用工具
llvm-as:把LLVM IR从人类能看懂的文本格式汇编成二进制格式。注意:此处得到的不是目标平台的机器码。llvm-dis:llvm-as的逆过程,即反汇编。 不过这里的反汇编的对象是LLVM IR的二进制格式,而不是机器码。opt:优化LLVM IR。输出新的LLVM IR。llc:把LLVM IR编译成汇编码。需要用as进一步得到机器码。lli:解释执行LLVM IR。暂无
暂无
文章部分内容来自ChatGPT-3.5,暂时没有校验其可靠性(看上去貌似说得通)。
将一件事情分成若干阶段,然后通过阶段之间的转移达到目标。由于转移的方向通常是多个,因此这个时候就需要决策选择具体哪一个转移方向。
动态规划所要解决的事情通常是完成一个具体的目标,而这个目标往往是最优解。并且:
每个阶段抽象为状态(用圆圈来表示),状态之间可能会发生转化(用箭头表示)。可以画出类似如下的图:
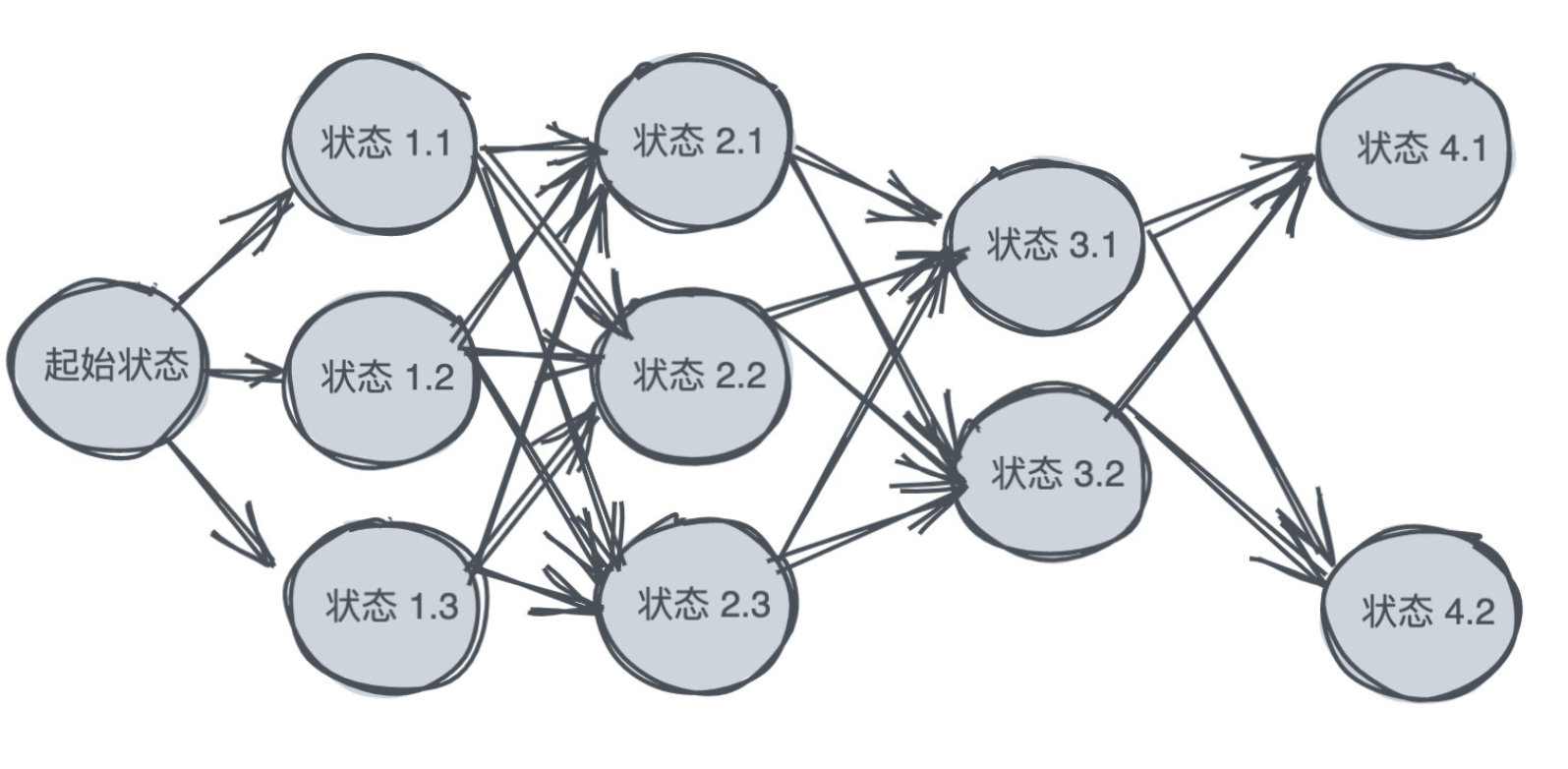
性质:
对于一个能用动态规划解决的问题,一般采用如下思路解决:
如何找到转移关系:
背包DP
f[i,0]=1f[i,0]=1n[i] 为 13,就将这种物品分成系数分别为 1, 2, 4, 6 的 4 件物品。1 | int num[maxn][2], dp[maxn]; |
区间DP
DAG 上的DP
树形 DP 往往需要递归DFS
爬楼梯问题的暴力普通递归DFS代码
1 | function climbStairs(n) { |
添加与DFS参数相关的记忆化数组,将这个 dfs 改成「无需外部变量」的 dfs。
1 | memo = {} |
状压+动态规划(DP, Dynamic Programming)
使用的数有限(共 10 个),并且使用到的数最多出现一次,容易想到使用「状压 DP」来求解:我们使用一个二进制数来表示具体的子集具体方案。
定义 f[state] 为当前子集选择数的状态为 state 时的方案数,state 为一个长度 10 的二进制数,若 state 中的第 k 位二进制表示为 1,代表数值 p[k] 在好子集中出现过;若第 k 位二进制表示为 0 代表 p[k] 在好子集中没出现过。
状态压缩有关,比如用 4 个字节存储状态
动态规划 与 np完全的关系
暂无
视频: https://www.bilibili.com/video/BV1Xj411K7oF/?vd_source=5bbdecb1838c6f684e0b823d0d4f6db3
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
实例化:创建一个类的实例,类的具体对象。
方法:类中定义的函数。
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
在Python中,类变量和实例变量是两个不同的概念:
例如:
1 | class Person: |
综上,类变量用于定义类的通用属性,实例变量用于定义实例的独特属性。区分二者是理解Python面向对象的关键。
1 | class Employee: |
必须有一个额外的第一个参数名称, 按照惯例它的名称是 self,self 不是 python 关键字,换成其他词语也行。
1 | emp1 = Employee("Zara", 2000) |
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法 class 派生类名(基类名)
调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数
,这点在代码上的区别如下:
1 | class Base: |
在Derived类中:
调用Base基类的方法base_method(),需要写成Base.base_method(self)
调用普通函数print(),直接写函数名即可
区别在于:
而对于普通函数,只需要直接调用即可,不需要self参数。
这与Python的名称空间和面向对象实现有关,是理解Python类继承的关键点。
1 | __init__ : 构造函数,在生成对象时调用 |
在Python中可以通过特殊方法__iadd__来对+=符号进行重载。
__iadd__需要定义在类中,用于指定+=操作时的具体行为。例如:
1 | class Vector: |
这里我们定义了__iadd__方法,用于实现两个Vector对象使用+=时的相加操作。
__iadd__方法的参数是另一个要相加的对象,在方法内部我们实现了两个向量的分量相加,并返回self作为结果。这样就实现了+=的运算符重载。
此外,Python还提供了__add__特殊方法用于重载+符号,但是__iadd__和__add__有以下区别:
所以对可变对象进行+=操作时,通常需要实现__iadd__方法。