摘要
ABI被人熟知,就是编译时,接口不匹配导致运行时的动态库undefined symbol报错。
Pin 是一个动态二进制插桩工具:
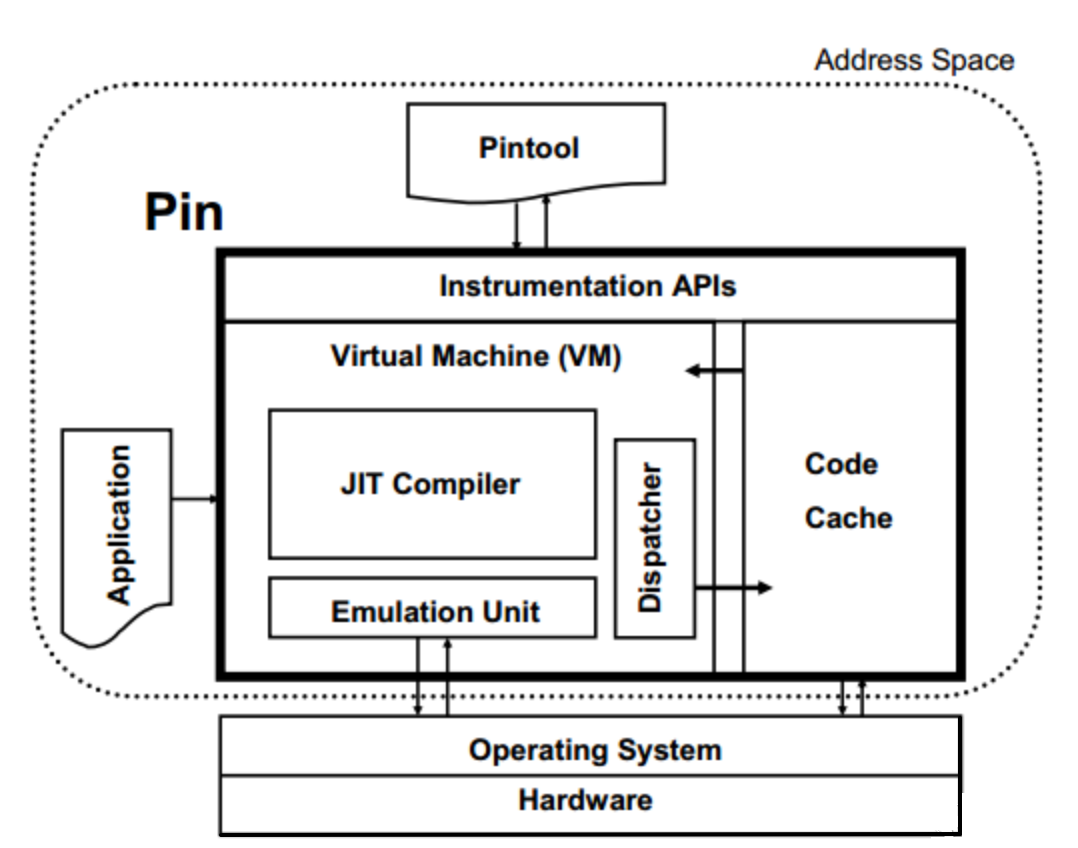
Pin机制类似Just-In-Time (JIT) 编译器,Trace插桩的基本流程(以动态基本块BBLs为分析单位):
通过一个例子来说明动态基本块BBLs与 汇编代码的BB的区别
1 | switch(i) |
上述代码会编译成下面的汇编, 对于实际执行时跳转从.L7进入的情况,BBLs包括四条指令,但是BB只会包括一条。
1 | .L7: |
Pin会将cpuid, popf and REP prefixed 指令在执行break 成很多BBLs,导致执行的基本块比预想的要多。(主要原因是这些指令有隐式循环,所以Pin会将其拆分成多个BBLs)
kit from Intel websiteThis part is always needed by pintool, for example Zsim, Sniper.
When you meet the following situation, you should consider update your pin version even you can ignore this warning by use flags like -ifeellucky under high compatibility risk.
1 | shaojiemike@snode6 ~/github/ramulator-pim/zsim-ramulator/pin [08:05:47] |
because this will easily lead to the problem
1 | Pin app terminated abnormally due to signal 6. # or signal 4. |
PIN_Init之前调用PIN_InitSymbols。1 | for (SEC sec = IMG_SecHead(img); SEC_Valid(sec); sec = SEC_Next(sec)) |
最重要的是
TRACE_AddInstrumentFunction Add a function used to instrument at trace granularityINS_AddInstrumentFunction() Add a function used to instrument at instruction granularityIMG_AddInstrumentFunction() Use this to register a call back to catch the loading of an imageINS_InsertPredicatedCall()1 | // Forward pass over all instructions in bbl |
1 | // Visit every basic block in the trace |
1 | UINT32 memOperands = INS_MemoryOperandCount(ins); |
最重要的是
示例分析
1 | // IPOINT_BEFORE 时运行的分析函数 |
目标:以样例插桩工具的源码为对象,熟悉pin的debug流程。
以官方教程为例子:
1 | uname -a #intel64 |
测试运行
1 | ../../../pin -t obj-intel64/inscount0.so -- ./a.out #正常统计指令数 to inscount.out |
下面介绍Pin 提供的debug工具:
首先创建所需的-g的stack-debugger.so和应用fibonacci.exe
1 | cd source/tools/ManualExamples |
其中OPT=-O0选项来自官方文档Using Fast Call Linkages小节,说明需要OPT=-O0选项来屏蔽makefile中的-fomit-frame-pointer选项,使得GDB能正常显示stack trace(函数堆栈?)
1 | $ ../../../pin -appdebug -t obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000 |
使用pin的-appdebug选项,在程序第一条指令前暂停,并启动debugger窗口。在另一个窗口里gdb通过pid连接:
1 | $ gdb fibonacci #如果没指定应用obj-intel64/fibonacci.exe |
能够在上一小节的debug窗口里,通过自定义debug指令打印自定义程序相关信息(比如当前stack使用大小)
Pintool “stack-debugger” 能够监控每条分配stack空间的指令,并当stack使用达到阈值时stop at a breakpoint。
这功能由两部分代码实现,一个是插桩代码,一个是分析代码。
1 | static VOID Instruction(INS ins, VOID *) |
所需的两个函数的分析代码如下:
1 | static ADDRINT OnStackChangeIf(ADDRINT sp, ADDRINT addrInfo) |
OnStackChangeIf函数监控当前的stack使用并判断是否到达阈值。DoBreakpoint函数连接debugger窗口,然后触发breakpoint,并打印相关信息。
也可以使用-appdebug_enable参数,取消在第一条指令前开启GDB窗口的功能,而是在触发如上代码的break时,才开启GDB窗口的连接。
而上述代码中的ConnectDebugger函数实现如下:
1 | static void ConnectDebugger() |
这部分讲述了如何debug Pintool中的问题。(对Pintool的原理也能更了解
为此,pin使用了-pause_tool n 暂停n秒等待gdb连接。
1 | ../../../pin -pause_tool 10 -t /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000 |
注意gdb对象既不是pin也不是stack-debugger.so,而是intel64/bin/pinbin。原因是intel64/bin/pinbin是pin执行时的核心程序,通过htop监控可以看出。
1 | # shaojiemike @ snode6 in ~/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples on git:dev x [19:57:26] |
这时GDB缺少了stack-debugger.so的调试信息,需要手动添加。这里的add-symbol-file命令是在pin启动时打印出来的,直接复制粘贴即可。
1 | (gdb) add-symbol-file /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so 0x7f3105f24170 -s .data 0x7f31061288a0 -s .bss 0x7f3106129280 |
stack-debugger.so的调试信息,无法设置断点。暂无
暂无
Zsim模拟器是
awesome-shell里多看看。
rg (Fast & Good multi-platform compatibility) > ag > ack(ack-grep) 🔥
1 | # 当前文件夹下查找 dlog关键字 |
find . -name "*xxx*"
lazydocker
The default program entry function is main, but can be changed in two situations:
#define xxx main in header file to replace the name which maybe ignored by silly search bar in VSCODE.-exxx compile flag;)取决于上下文。if, while, for)、复合语句({}) 不需要分号。#define, #include):不需要分号,因为它们不是 C++ 语法层面的内容。} 不需要分号,但声明类或结构体时 } 后要加分号。总结来说,分号用来结束语句,包括声明、表达式和执行体等,但当你定义一个复合结构(如函数定义、控制语句)时,不需要分号来结束复合结构的定义。
1 | int getKthAncestor(int node, int k) { |
根据C++的作用域规则,内层的局部变量会覆盖外层的同名变量。因此,在第二行的语句中,node引用的是函数参数中的node,而不是你想要的之前定义的node。
为了避免这个问题,你可以修改代码,避免重复定义变量名。例如,可以将第二行的变量名改为newNode或其他不同的名称,以避免与函数参数名冲突。
运算符性质:
https://en.cppreference.com/w/cpp/language/types
https://en.cppreference.com/w/cpp/types/integer
1 | //返回与平台相关的数值类型的极值 |
1 | extern |
static 作⽤:控制变量的存储⽅式和作用范围(可⻅性)。
int MyClass::staticVariable = 10;当const修饰基本数据类型时,可以将其放置在类型说明符的前面或后面,效果是一样的。const关键字用于声明一个常量,即其值在声明后不可修改。
1 | const int constantValue1 = 10; // const在类型说明符前 |
当const关键字位于指针变量或引用变量的左侧时,它用于修饰指针所指向的变量,即指针指向的内容为常量。当const关键字位于指针变量或引用变量的右侧时,它用于修饰指针或引用本身,即指针或引用本身是常量。
修饰指针指向的变量, 它指向的值不能修改:
1 | int x = 5; |
修饰指针本身 ,它不能再指向别的变量,但指向(变量)的值可以修改。:
1 | const int y = 10; |
const int *const p3; //指向整形常量 的 常量指针 。它既不能再指向别的常量,指向的值也不能修改。
在C++, explicit 是一个关键字,用于修饰单参数构造函数,用于禁止隐式类型转换。
当一个构造函数被声明为 explicit 时,它指示编译器在使用该构造函数进行类型转换时只能使用显式调用,而不允许隐式的类型转换发生。
通过使用 explicit 关键字,可以防止一些意外的类型转换,提高代码的清晰性和安全性。它通常用于防止不必要的类型转换,特别是在单参数构造函数可能引起歧义或产生意外结果的情况下。
#include_next 的作用是b.cpp想使用stdlib.h, 那么在代码的目录下创建stdlib.h,并在该文件里#include_next "stdlib.h" 防止递归引用。#define PI 3.14159,在代码中将PI替换为3.14159。const:
const int MAX_VALUE = 100;,声明一个名为MAX_VALUE的常量。typedef:
typedef int Age;,为int类型创建了一个别名Age。inline:
inline int add(int a, int b) { return a + b; },声明了一个内联函数add。define主要用于宏定义,const用于声明常量,typedef用于创建类型别名,inline用于内联函数的声明。
为了避免同一个文件被include多次,C/C++中有两种方式,一种是#ifndef方式,一种是#pragma once方式。在能够支持这两种方式的编译器上,二者并没有太大的区别,但是两者仍然还是有一些细微的区别。
1 |
|
namespace 会影响 typedef 的作用范围,但不会直接限制 #define 宏的作用范围。
1 | //值传递 |
引用传递和指针传递的区别:
指针传递和引用传递的使用情景:
虽然理论上可以通过类似void f(bool x = true)来实现默认值。
1 | // 函数声明 |

1 | template<typename T> |
1 |
|
VA_LIST 是在C语言中解决变参问题的一组宏,变参问题是指参数的个数不定,可以是传入一个参数也可以是多个;可变参数中的每个参数的类型可以不同,也可以相同;可变参数的每个参数并没有实际的名称与之相对应,用起来是很灵活。
系统提供了vprintf系列格式化字符串的函数,用于编程人员封装自己的I/O函数。
1 | int vprintf / vscanf (const char * format, va_list ap); // 从标准输入/输出格式化字符串 |
使用结构体
1 | struct RowAndCol { int row;int col; }; |
在 C++ 中,左值(lvalue) 和 右值(rvalue) 是两个重要的概念,用来描述表达式的值和内存的关系。它们帮助开发者理解变量的生命周期、赋值和对象管理,特别是在现代 C++ 中引入了右值引用后,优化了移动语义和资源管理。
左值(lvalue,locatable value) 是指在内存中有明确地址、可持久存在的对象,可以对其进行赋值操作。通俗地说,左值是能够取地址的值,可以出现在赋值操作符的左边。
特点:
& 运算符)。右值(rvalue,readable value) 是没有明确地址、临时存在的对象,不能对其进行赋值操作。它们通常是字面值常量或表达式的结果。右值只能出现在赋值操作符的右边,表示一个临时对象或数据。
特点:
& 获取右值的地址)。C++11 引入了 右值引用,即通过 && 符号表示。这使得右值也能通过引用进行操作,特别是在实现移动语义(move semantics)和避免不必要的拷贝时非常有用。右值引用允许我们通过右值管理资源,避免性能上的损失。
通常,左值是表示持久存在的对象,可以通过取地址符 & 获取其地址,而右值是临时的、短暂存在的值,不能直接获取其地址。理解这两者对于编写高效的 C++ 代码和使用现代特性(如右值引用和移动语义)非常重要。
&&)是 C++11 引入的新特性,用来优化资源管理和避免不必要的拷贝操作。在C++98/03中我们只能对普通数组和POD(plain old data,简单来说就是可以用memcpy复制的对象)类型可以使用列表初始化,如下:
1 | //数组的初始化列表: |
在C++11中初始化列表被适用性被放大,可以作用于任何类型对象的初始化。如下:
1 | X x1 = X{1,2}; |
聚合类型可以进行直接列表初始化
聚合类型包括
对于一个聚合类型,使用列表初始化相当于使用std::initializer_list对其中的相同类型T的每个元素分别赋值处理,类似下面示例代码;
1 | struct CustomVec { |
⼩贺 C++ ⼋股⽂ PDF 的作者,电⼦书的内容整理于公众号「herongwei」
https://shaojiemike.notion.site/C-11-a94be53ca5a94d34b8c6972339e7538a
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
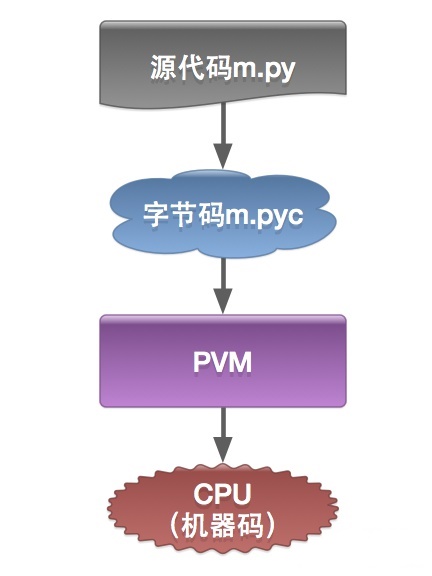
解释型语言没有严格编译汇编过程,由解释器将代码块按需要变运行边翻译给机器执行。因此解释型语言一度存在运行效率底,重复解释的问题。但是通过对解释器的优化!可以提高解释型语言的运行效率。
Python 与大多数解释型语言一样,确实是将源代码编译为一组虚拟机指令,并且 Python 解释器是针对相应的虚拟机实现的。这种中间格式被称为 “字节码”。
Python 以 .pyc 结尾的 “ 字节码(bytecode)” 文件(二进制文件),一般位于__pycache__ 的子目录中,可以避免每次运行 Python 时去重新解析源代码。
1 | python -m py_compile file.py # 生成单个pyc文件 |
pyo文件是源代码文件经过优化编译后生成的文件,是pyc文件的优化版本。编译时需要使用-O和-OO选项来生成pyo文件。在Python3.5之后,不再使用.pyo文件名,而是生成文件名类似“test.opt-n.pyc的文件。
1 | python -O -m py_compile test.py |
CPython 使用一个基于栈的虚拟机。(你可以 “推入” 一个东西到栈 “顶”,或者,从栈 “顶” 上 “弹出” 一个东西来)。
CPython 使用三种类型的栈:
运行流程区别
python的传统运行执行模式:录入的源代码转换为字节码,之后字节码在python虚拟机中运行。代码自动被编译,之后再解释成机器码在CPU中执行。
c编译器直接把c源代码编译成机器码。过程比python执行过程少了字节码生成和虚拟机执行字节码过程。所以自然比python快。
1 | list.append('Google') ## 使用 append() 添加元素 |
setup安装包的过程,请看pip package一文。
__init__.py__init__.py文件在 Python 包结构中扮演着重要角色,但是否必须存在取决于你使用的 Python 版本和具体的使用场景。
Python 2:
__init__.py 是必需的。它标志着一个目录是一个 Python 包,允许该目录中的模块被导入。Python 3:
__init__.py 不再是必需的。Python 3 支持隐式命名空间包(Implicit Namespace Packages),这意味着即使没有 __init__.py 文件,目录也可以被视为包并进行导入。__init__.py 不再是必需的,但它仍然是推荐的做法,特别是在需要执行包级别的初始化逻辑时。命名空间(namespace)可以基本理解成每个文件是一个,通过import来使用
触发 __init__.py
__init__.py 文件。如果没有这个文件,Python 会认为这个目录不是一个包,因此 import 语句会失败。__init__.py 负责初始化这个包,可以定义一些包级别的变量、函数或导入包的其他子模块。行为:
__init__.py 文件只会在第一次导入时被执行一次。如果模块已经被导入到当前的命名空间,再次 import 不会重新执行 __init__.py,除非你强制重新加载(比如用 importlib.reload())。import 的执行会触发模块的初始化,类似于 C++ 中构造函数的概念,但不是在对象级别,而是在模块级别。1 | # example/__init__.py |
1 | import example |
| 场景 | 导入方式 | 示例 |
|---|---|---|
| 导入标准库/第三方库 | 绝对导入 | import numpy as np |
| 导入项目根目录下的模块 | 绝对导入 | from my_project import config |
| 包内模块互相引用 | 相对导入 | from . import helper |
| 直接运行脚本 | 绝对导入 | python script.py |
| 作为包的一部分运行 | 相对导入或绝对导入 | python -m package.module |
在 Python 中,import 语句是否使用点号(.)取决于你使用的是 相对导入 还是 绝对导入,以及代码所处的上下文环境。以下是详细的解释:
关键点:
__init__.py)。python main.py),否则会报错:1 | ImportError: attempted relative import with no known parent package |
if __name__ == "__main__"这种写法通常出现在模块中,它的作用是控制模块的执行流程。程序结束时的清理行为(类似析构函数的操作)
在 Python 中,并没有像 C++ 那样显式的析构函数。模块或对象的清理一般通过以下方式实现:
__del__ 方法进行资源清理。这个机制类似于 C++ 的析构函数,但触发时机取决于 Python 的垃圾回收机制。1 | class MyClass: |
atexit 模块来注册一个函数,确保在程序结束时执行。示例:使用 atexit 实现模块级别的清理操作
1 | import atexit |
输出:
1 | Program is running |
atexit 模块允许你注册多个函数,它们会在解释器关闭之前按注册顺序依次执行。__init__.py 文件。这相当于模块的 “构造” 过程。__del__ 方法来管理对象的生命周期。通常情况下,当对象不再被引用时,会自动触发清理。atexit 模块来执行程序结束时的资源清理操作。你可以在模块中注册一些函数,确保在程序退出时执行清理任务。以下是 Python 和 C++ 中一些常见的运算符及其差异:
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
// |
整数除法 | a // b |
a / b (整数除法) |
% |
取模 | a % b |
a % b |
** |
幂 | a ** b |
pow(a, b) |
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
& |
按位与 | a & b |
a & b |
| ` | ` | 按位或 | `a |
^ |
按位异或 | a ^ b |
a ^ b |
~ |
按位取反 | ~a |
~a |
<< |
左移 | a << b |
a << b |
>> |
右移 | a >> b |
a >> b |
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
//= |
整数除法赋值 | a //= b |
a /= b (整数除法) |
%= |
取模赋值 | a %= b |
a %= b |
**= |
幂赋值 | a **= b |
a = pow(a, b) |
&= |
按位与赋值 | a &= b |
a &= b |
| ` | =` | 按位或赋值 | `a |
^= |
按位异或赋值 | a ^= b |
a ^= b |
<<= |
左移赋值 | a <<= b |
a <<= b |
>>= |
右移赋值 | a >>= b |
a >>= b |
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
and |
逻辑与 | a and b |
a && b |
or |
逻辑或 | a or b |
`a |
not |
逻辑非 | not a |
!a |
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
in |
成员 | a in b |
无直接等价 |
not in |
非成员 | a not in b |
无直接等价 |
| 运算符 | 描述 | Python 示例 | C++ 示例 |
|---|---|---|---|
is |
身份相同 | a is b |
无直接等价 |
is not |
身份不同 | a is not b |
无直接等价 |
@能在最小改变函数的情况下,包装新的功能。^1
1 | def use_logging(func): |
foo.__name__变成了use_logging@wraps(func)1 | def use_logging(func): |
单下划线、双下划线、头尾双下划线说明:
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 init() 之类的。_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问,不能用于 from module import *__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。* 和 ** 分别解包可迭代对象和字典。** 用于将传入的关键字参数打包成一个字典;** 则用于将字典解包为关键字参数。python 能很轻易的
开启 Python 的调试模式:
通过设置环境变量启用 Python 的调试信息,这有助于捕获异常和详细的堆栈信息。
1 | export PYTHONMALLOC=debug |
使用 faulthandler 模块:
Python 提供了一个 faulthandler 模块,可以用来捕获段错误并打印堆栈信息。你可以在程序的开头添加以下代码来启用它:
1 | import faulthandler |
这将会在段错误发生时输出堆栈跟踪。
查看 Python 调试输出:
启动 Python 程序时,通过 faulthandler 打印堆栈信息,或通过 GDB 调试 Python 解释器。如果 Python 解释器发生崩溃,faulthandler 会帮助你定位错误。
pstack remote pid , 虽然官方没说,但是可以pip install pystack 或者 pip install pstack安装
py-spy dump –pid 831568
如果程序能正常运行,优先推荐profiling理解程序逻辑。
traceback.print_stack()
1 | from viztracer import VizTracer |
或者
1 | from viztracer import VizTracer |
torch_npu.mstx.mark range_start等能实现到excel的输出,参考文档。
msprobe是MindStudio Training Tools工具链下精度调试部分的工具包,主要包括精度预检、溢出检测、精度比对和梯度监控等功能,目前适配PyTorch和MindSpore框架。具体参考文档。
1 | # 导入工具的数据采集接口。 |
另一种方式直接save任意数据对象,参考文档
1 | from msprobe.pytorch import PrecisionDebugger |
参考mstt文档
创建对比文件
1 | { |
执行 msprobe -f pytorch compare -i ./compare.json -o ./output
参考vllm文档
安装tensorborad插件 pip install tb-graph-ascend
创建compare.json
1 | { |
转换成对比图
1 | msprobe -f pytorch graph -i ./compare.json -o ./output |
启动tensorboard
1 | tensorboard --logdir output --host localhost --port 6501 |
ic.format(*args)获得ic打印的文本ic.disable()and ic.enable()ic.configureOutput(prefix='Debug | ')1 | from icecream import ic |
如果你只想捕获标准错误的输出,并将其保存到日志文件,可以使用以下命令:
1
python3.8 setup.py build bdist_wheel 1>&2 | tee compile.log
或将 `stderr` 和 `stdout` 单独重定向:
1
python3.8 setup.py build bdist_wheel 2>compile.log
定位 Python 中 setup.py 脚本运行缓慢的 热点,可以通过多种方式进行性能分析,具体步骤取决于你想了解的性能细节。以下是几种常见的方法来定位性能瓶颈。
cProfile 进行性能分析cProfile 是 Python 标准库中用于进行性能分析的工具。你可以用它来跟踪 setup.py 执行时的函数调用并找到性能瓶颈。
cProfile + snakeviz + gprof2dot
1 | ./gprof2dot.py -f pstats Diff.status | dot -Tpng -o ./output/Diff.png |
1.1 使用 cProfile 分析 setup.py
你可以通过 cProfile 运行 setup.py 并生成分析报告:
1 | python -m cProfile -o setup.prof setup.py install |
这将运行 setup.py 并将性能分析结果保存到 setup.prof 文件中。
1.2 可视化分析报告
使用 pstats 或者第三方工具 snakeviz 来分析 setup.prof:
使用 pstats 来查看分析结果:
1 | python -m pstats setup.prof |
然后,你可以在 pstats 交互式界面中输入命令,比如:
sort cumtime 按总耗时排序。stats 查看函数调用的分析结果。安装 snakeviz 来生成Web图形化报告:
1 | pip install snakeviz |
运行 snakeviz 来可视化分析结果:
1 | snakeviz setup.prof # deploy to 127.0.0.1:8080 |
这样可以生成一个图形化的界面,显示每个函数的执行时间以及调用关系,让你更直观地看到性能瓶颈。
使用 gprof2dot 生成调用关系图片:
安装 gprof2dot 工具:pip install gprof2dot
使用 gprof2dot 将 cProfile 生成的 output.prof 转换为 .dot 文件:gprof2dot -f pstats output.prof | dot -Tsvg -o output.svg
这里的 -f pstats 表示输入的格式是 cProfile 生成的 pstats 文件。这个命令会将结果转换为 SVG 格式的火焰图,保存为 output.svg。
打开生成的 SVG 文件,查看火焰图。
生成火焰图: flameprof
python flameprof.py input.prof > output.svg生成火焰图(有详细文件路径): flamegraph
flameprof --format=log requests.prof | xxx_path/flamegraph.pl > requests-flamegraph.svgline_profiler 进行逐行性能分析如果你想深入了解 setup.py 的某个函数或一组函数的逐行性能,可以使用 line_profiler 工具来分析代码的逐行执行时间。
3.1 安装 line_profiler
1 | pip install line_profiler |
3.2 添加装饰器
首先,在 setup.py 中找到你想要分析的函数,添加 @profile 装饰器(在 line_profiler 中的分析模式下使用):
1 |
|
3.3 运行 line_profiler
你可以使用 kernprof.py 来运行 setup.py 并生成逐行性能报告:
1 | kernprof -l -v setup.py install |
这将运行 setup.py 并生成一份逐行性能分析报告,显示每一行代码的耗时。
Py-Spy 进行实时性能分析(推荐!!!)Py-Spy 是一个 Python 的取样分析器,它可以在不修改代码的情况下对 Python 程序进行性能分析,并生成实时的性能报告。
4.1 安装 Py-Spy
1 | pip install py-spy |
4.2 运行 Py-Spy 对 setup.py 进行分析
你可以在执行 setup.py 的同时运行 Py-Spy 进行取样分析:
1 | py-spy top -- python setup.py install |
这会生成一个实时的报告,类似于 top 命令,显示当前正在运行的 Python 函数以及其消耗的 CPU 时间。
4.3 生成火焰图
如果你希望生成一个更直观的火焰图,可以使用 py-spy 生成火焰图文件:
1 | py-spy record -o profile.svg -- python setup.py install |
然后你可以打开 profile.svg 文件,查看一个交互式的火焰图,清晰展示函数调用的时间分布。
strace 分析系统调用如果 setup.py 涉及大量的 I/O 操作(比如读写文件或安装依赖包),可能是这些操作导致了性能瓶颈。你可以使用 strace 来分析 setup.py 的系统调用,找到 I/O 操作的瓶颈。
1 | strace -tt -T -o strace.log python setup.py install |
-tt 选项会显示每个系统调用的时间戳。-T 会显示每个系统调用耗时。-o 将结果输出到 strace.log 文件中。通过查看 strace.log,你可以找出系统调用中哪些操作耗时过长。
cProfile 或 Py-Spy 进行函数级别的性能分析,找出执行慢的函数。line_profiler 来分析慢的部分。strace 来检查系统调用。time 在脚本中插入计时代码,快速定位长时间的执行步骤。这些工具可以帮助你定位和修复 setup.py 运行缓慢的热点。
函数的单元测试
1 | python3 -m venv name |
任意变量使用pickle
1 | # 使用二进制 |
可以序列化的使用json
1 | import json |
多个变量
1 | # 将多个变量组织成字典或列表 |
其余cmake有的, Scons 也有。
Sconstruct python file as compile entryadd option for scons command
1 | AddOption('--buildDir', |
add sub scons config file and build result path using variant_dir
1 | env.SConscript("src/SConscript", variant_dir=buildDir, exports= {'env' : env.Clone()}) |
achive debug mode
using scons debug=1 command.
1 | env = Environment() |
Define the Build Environment:
In the SConstruct file, define the build environment by creating an Environment object. You can specify compiler options, flags, include paths, library paths, and other build settings within this object.
1 | env = Environment(CXX='g++', CCFLAGS=['-O2', '-Wall'], CPPPATH=['include'], LIBPATH=['lib']) |
Specify Source Files and Targets:
Define the source files for your C++ program and specify the target(s) you want to build using the Program() function.
1 | source_files = ['main.cpp', 'util.cpp', 'other.cpp'] |
In this example, main.cpp, util.cpp, and other.cpp are the source files, and my_program is the name of the target executable.
static or dynamic lib
1 | # static |
allSrcs, ".git/index", or "SConstruct") change.1 | env.Command( |
1 | scons -c # Clean |
TODO: multipim how to add a singel head file during compilation process.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
根据教程
/etc:是 Etcetera(等等) 的缩写,这个目录用来存放所有的系统管理所需要的配置文件和子目录。/lib:是 Library(库) 的缩写这个目录里存放着系统最基本的动态连接共享库,其作用类似于 Windows 里的 DLL 文件。几乎所有的应用程序都需要用到这些共享库。/opt:是 optional(可选) 的缩写,这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。/usr:是 unix shared resources(共享资源) 的缩写,这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似于 windows 下的 program files 目录。It’s install for all user./var:是 variable(变量) 的缩写,这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。TODO: during the application install, which locations those app used?
I guess it’s usr/bin or /include , opt and /lib
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无