Read more
CUDA编程水平高低的不同,会导致几十上百倍的性能差距。但是这篇将聚焦于CUDA的编程语法,编译与运行。
CUDA编程水平高低的不同,会导致几十上百倍的性能差距。但是这篇将聚焦于CUDA的编程语法,编译与运行。
第一种,指定变量类型,如果没有初始化,则变量默认为零值。
1 | //var v_name v_type |
1 | //特殊 |
第二种,根据值自行判定变量类型。
1 | //var v_name = value |
第三种,使用声明符号:=
但是如果变量已经使用 var 声明过了,再使用 := 声明变量,就产生编译错误,格式:
1 | v_name := value |
1 | for key, value := range oldMap { |
Go 语言支持并发,我们只需要通过 go 关键字来开启 goroutine 即可。
goroutine 是轻量级线程,goroutine 的调度是由 Golang 运行时进行管理的。
goroutine 语法格式:go 函数名( 参数列表 )
Go 允许使用 go 语句开启一个新的运行期线程, 即 goroutine,以一个不同的、新创建的 goroutine 来执行一个函数。 同一个程序中的所有 goroutine 共享同一个地址空间。
通道可用于两个 goroutine 之间通过传递一个指定类型的值来同步运行和通讯。操作符 <- 用于指定通道的方向,发送或接收。如果未指定方向,则为双向通道。
1 | ch <- v // 把 v 发送到通道 ch |
声明一个通道很简单,我们使用chan关键字即可,通道在使用前必须先创建:
1 | ch := make(chan int) |
1 | func countGoodRectangles(rectangles [][]int) int { |
https://github.com/swangeese/acsa-web/tree/webhook
暂无
暂无
1 | wget https://go.dev/dl/go1.18.3.linux-amd64.tar.gz |
1 | $ cd $HOME/go/src/hello |
Packages
Go packages are folders that contain one more go files.
Modules
A modules (starting with vgo and go 1.11) is a versioned collection of packages.
1 | go get github.com/andanhm/go-prettytimee |
go list -m -u all 来检查可以升级的package,
使用go get -u need-upgrade-package 升级后会将新的依赖版本更新到go.mod
也可以使用 go get -u 升级所有依赖
作者:若与
链接:https://www.jianshu.com/p/760c97ff644c
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
暂无
暂无
go modules 是 golang 1.11 新加的特性。现在1.12 已经发布了,是时候用起来了。Modules官方定义为:
模块是相关Go包的集合。modules是源代码交换和版本控制的单元。 go命令直接支持使用modules,包括记录和解析对其他模块的依赖性。modules替换旧的基于GOPATH的方法来指定在给定构建中使用哪些源文件。
1 | mkdir Gone |
对应go.mod文件
1 | module Gone |
go.mod文件一旦创建后,它的内容将会被go toolchain全面掌控。
go toolchain会在各类命令执行时,比如go get、go build、go mod等修改和维护go.mod文件。
go.mod 提供了module, require、replace和exclude 四个命令
module 语句指定包的名字(路径)
require 语句指定的依赖项模块
replace 语句可以替换依赖项模块
exclude 语句可以忽略依赖项模块
对于main.go里的import
1 | package main |
执行 go run main.go 运行代码会发现 go mod 会自动查找依赖自动下载,并修改go.mod(安装 package 的原則是先拉最新的 release tag,若无tag则拉最新的commit)
结合github很简单实现
暂无
暂无
Cuda Optimize : Vectorized Memory Access
1 | __global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) { |
简单的分块拷贝。
通过cuobjdump -sass executable.得到对应的标量copy对应的SASS代码
1 | /*0058*/ IMAD R6.CC, R0, R9, c[0x0][0x140] |
(SASS不熟悉,请看SASS一文)
其中4条IMAD指令计算出读取和存储的指令地址R6:R7和R4:R5。第4和6条指令执行32位的访存命令。
通过使用int2, int4, or float2
比如将int的指针d_in类型转换然后赋值。
1 | reinterpret_cast<int2*>(d_in) |
但是需要注意对齐问题,比如
1 | reinterpret_cast<int2*>(d_in+1) |
这样是非法的。
通过使用对齐的结构体来实现同样的目的。
1 | struct Foo {int a, int b, double c}; // 16 bytes in size |
执行for循环次数减半,注意边界处理。
1 | __global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) { |
对应汇编可以看出
1 | /*0088*/ IMAD R10.CC, R3, R5, c[0x0][0x140] |
变成了LD.E.64
执行for循环次数减半,注意边界处理。
1 | __global__ void device_copy_vector4_kernel(int* d_in, int* d_out, int N) { |
对应汇编可以看出
1 | /*0090*/ IMAD R10.CC, R3, R13, c[0x0][0x140] |
变成了LD.E.128
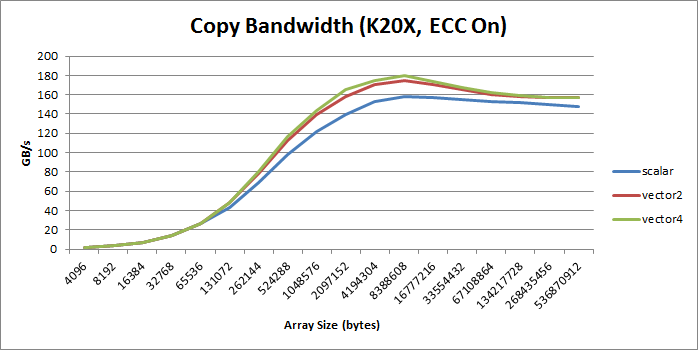
(个人感觉,提升也不大吗?也没有两倍和四倍的效果)
绝大部分情况,向量比标量好, increase bandwidth, reduce instruction count, and reduce latency. 。
但是会增加额外的寄存器(SASS里也没有看到??)和降低并行性(什么意思???)
PyG是一个基于PyTorch的用于处理不规则数据(比如图)的库,或者说是一个用于在图等数据上快速实现表征学习的框架。它的运行速度很快,训练模型速度可以达到DGL(Deep Graph Library )v0.2 的40倍(数据来自论文)。除了出色的运行速度外,PyG中也集成了很多论文中提出的方法(GCN,SGC,GAT,SAGE等等)和常用数据集。因此对于复现论文来说也是相当方便。
经典的库才有函数可以支持,自己的模型,自己根据自动微分实现。还要自己写GPU并行。
MessagePassing 是网络交互的核心
torch_geometric.data.Data (下面简称Data) 用于构建图
通过data.face来扩展Data
在 PyG 中,我们使用的不是这种写法,而是在get()函数中根据 index 返回torch_geometric.data.Data类型的数据,在Data里包含了数据和 label。
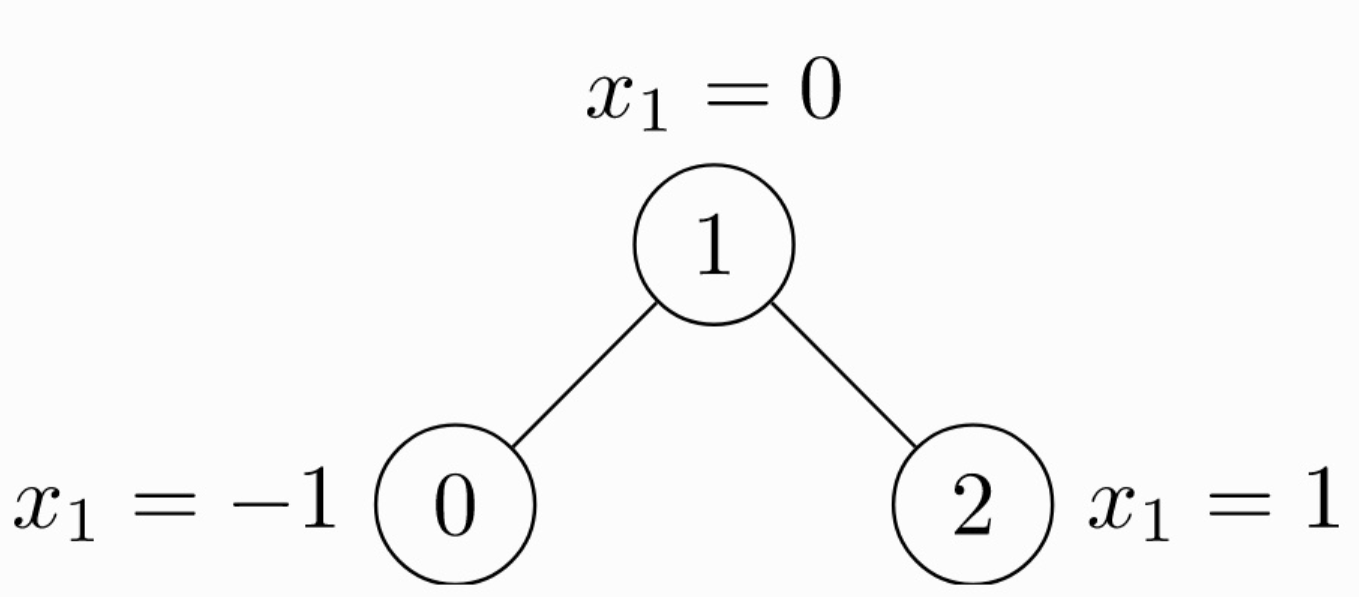
由于是无向图,因此有 4 条边:(0 -> 1), (1 -> 0), (1 -> 2), (2 -> 1)。每个节点都有自己的特征。上面这个图可以使用 torch_geometric.data.Data来表示如下:
1 | import torch |
注意edge_index中边的存储方式,有两个list,第 1 个list是边的起始点,第 2 个list是边的目标节点。注意与下面的存储方式的区别。
1 | import torch |
这种情况edge_index需要先转置然后使用contiguous()方法。关于contiguous()函数的作用,查看 PyTorch中的contiguous。
1 | import torch |
DataLoader 这个类允许你通过batch的方式feed数据。创建一个DotaLoader实例,可以简单的指定数据集和你期望的batch size。
1 | loader = DataLoader(dataset, batch_size=512, shuffle=True) |
DataLoader的每一次迭代都会产生一个Batch对象。它非常像Data对象。但是带有一个‘batch’属性。它指明了了对应图上的节点连接关系。因为DataLoader聚合来自不同图的的batch的x,y 和edge_index,所以GNN模型需要batch信息去知道那个节点属于哪一图。
1 | for batch in loader: |
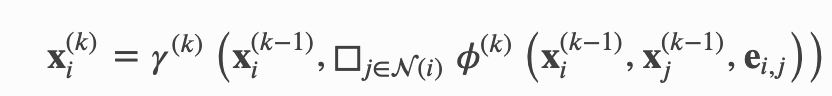
其中,x 表示表格节点的 embedding,e 表示边的特征,ϕ 表示 message 函数,□ 表示聚合 aggregation 函数,γ 表示 update 函数。上标表示层的 index,比如说,当 k = 1 时,x 则表示所有输入网络的图结构的数据。
为了实现这个,我们需要定义:
[2, num_messages], where messages from nodes in edge_index[0] are sent to nodes in edge_index[1]会根据 flow=“source_to_target”和if flow=“target_to_source”或者x_i,x_j,来区分处理的边。
x_j表示提升张量,它包含每个边的源节点特征,即每个节点的邻居。通过在变量名后添加_i或_j,可以自动提升节点特征。事实上,任何张量都可以通过这种方式转换,只要它们包含源节点或目标节点特征。
_j表示每条边的起点,_i表示每条边的终点。x_j表示的就是每条边起点的x值(也就是Feature)。如果你手动加了别的内容,那么它的_j, _i也会自动进行处理,这个自己稍微单步执行一下就知道了
在实现message的时候,节点特征会自动map到各自的source and target nodes。
aggregation scheme 只需要设置参数就好,“add”, “mean”, “min”, “max” and “mul” operations
aggregation 输出作为第一个参数,后面的参数是 propagate()的
$$
\mathbf{x}i^{(k)} = \sum{j \in \mathcal{N}(i) \cup { i }} \frac{1}{\sqrt{\deg(i)} \cdot \sqrt{\deg(j)}} \cdot \left( \mathbf{\Theta}^{\top} \cdot \mathbf{x}_j^{(k-1)} \right)
$$
该式子先将周围的节点与权重矩阵\theta相乘, 然后通过节点的度degree正则化,最后相加
步骤可以拆分如下
步骤1 和 2 需要在message passing 前被计算好。 3 - 5 可以torch_geometric.nn.MessagePassing 类。
添加self-loop的目的是让featrue在聚合的过程中加入当前节点自己的feature,没有self-loop聚合的就只有邻居节点的信息。
1 | import torch |
所有的逻辑代码都在forward()里面,当我们调用propagate()函数之后,它将会在内部调用message()和update()。
1 | conv = GCNConv(16, 32) |
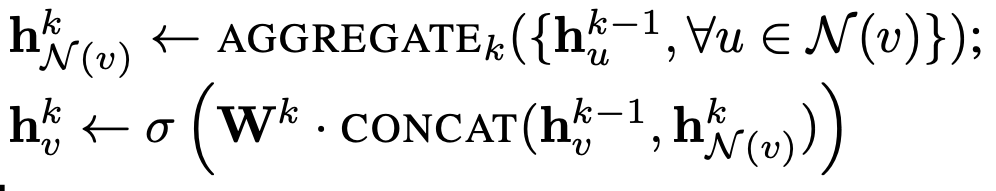
聚合函数(aggregation)我们用最大池化(max pooling),这样上述公示中的 AGGREGATE 可以写为: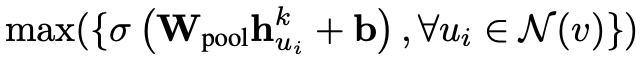
上述公式中,对于每个邻居节点,都和一个 weighted matrix 相乘,并且加上一个 bias,传给一个激活函数。相关代码如下(对应第二个图):
1 | class SAGEConv(MessagePassing): |
对于 update 方法,我们需要聚合更新每个节点的 embedding,然后加上权重矩阵和偏置(对应第一个图第二行):
1 | class SAGEConv(MessagePassing): |
综上所述,SageConv 层的定于方法如下:
1 | import torch |
GNN的batch实现和传统的有区别。
将网络复制batch次,batchSize的数据产生batchSize个Loss。通过Sum或者Max处理Loss,整体同时更新所有的网络参数。至于网络中循环输入和输出的H^(t-1)和H^t。(感觉直接平均就行了。
有几个可能的问题
通过 rescaling or padding(填充) 将相同大小的网络复制,来实现新添加维度。而新添加维度的大小就是batch_size。
但是由于图神经网络的特殊性:边和节点的表示。传统的方法要么不可行,要么会有数据的重复表示产生的大量内存消耗。
为此引入了ADVANCED MINI-BATCHING来实现对大量数据的并行。
https://pytorch-geometric.readthedocs.io/en/latest/notes/batching.html
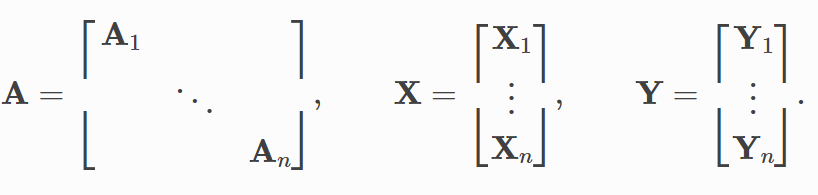
可以实现将多个图batch成一个大图。 通过重写collate()来实现,并继承了pytorch的所有参数,比如num_workers.
在合并的时候,除开edge_index [2, num_edges]通过增加第二维度。其余(节点)都是增加第一维度的个数。
1 | # 原本是[2*4] |
1 | from torch_geometric.data import Data |
1 | from torch_geometric.datasets import TUDataset |
暂无
暂无
Rust 速度惊人且内存利用率极高。由于没有运行时和垃圾回收,它能够胜任对性能要求特别高的服务,可以在嵌入式设备上运行,还能轻松和其他语言集成。
Rust 丰富的类型系统和所有权模型保证了内存安全和线程安全,让您在编译期就能够消除各种各样的错误。
异常简单,默认安装在自己.local/bin下,会自动修改bashrc/zshrc
On Linux and macOS systems, this is done as follows:
1 | curl https://sh.rustup.rs -sSf | sh |
1 | impl ClassName { |
Rust 是强类型语言,但具有自动判断变量类型的能力。
1 | //可以指定类型 |
Rust 函数声明返回值类型的方式:在参数声明之后用 -> 来声明函数返回值的类型(不是 : )。
不写return是将最后一个当作返回值?(貌似是
所有权对大多数开发者而言是一个新颖的概念,它是 Rust 语言为高效使用内存而设计的语法机制。所有权概念是为了让 Rust 在编译阶段更有效地分析内存资源的有用性以实现内存管理而诞生的概念。
如果我们定义了一个变量并给它赋予一个值,这个变量的值存在于内存中。这种情况很普遍。但如果我们需要储存的数据长度不确定(比如用户输入的一串字符串),我们就无法在定义时明确数据长度,也就无法在编译阶段令程序分配固定长度的内存空间供数据储存使用。(有人说分配尽可能大的空间可以解决问题,但这个方法很不文明)。这就需要提供一种在程序运行时程序自己申请使用内存的机制——堆。本章所讲的所有”内存资源”都指的是堆所占用的内存空间。
有分配就有释放,程序不能一直占用某个内存资源。因此决定资源是否浪费的关键因素就是资源有没有及时的释放。
我们把字符串样例程序用 C 语言等价编写:
1 | { |
很显然,Rust 中没有调用 free 函数来释放字符串 s 的资源(假设 “nhooo” 在堆中,这里)。Rust 之所以没有明示释放的步骤是因为在变量范围结束的时候,Rust 编译器自动添加了调用释放资源函数的步骤。
这种机制看似很简单了:它不过是帮助程序员在适当的地方添加了一个释放资源的函数调用而已。但这种简单的机制可以有效地解决一个史上最令程序员头疼的编程问题。
https://hashrust.com/blog/memory-safey-in-rust-part-1/
https://deathking.github.io/2020/08/03/blue-team-rust-what-is-memory-safety-really/
https://segmentfault.com/a/1190000041151698
https://bbs.huaweicloud.com/blogs/193974
暂无
暂无
容易转换成TensorRT
好像是属于NLP问题