AI Post Traning: DiffusionNFT
动机
- 似然估计困难:自回归模型的似然可精确计算,而扩散模型的似然只能以高开销近似,导致 RL 优化过程存在系统性偏差。^1
- 解释:指扩散模型的打分相对于LLM困难
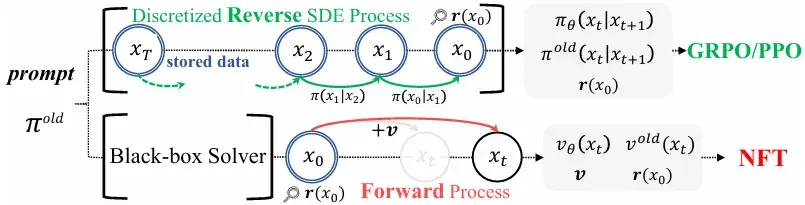
- 前向–反向不一致:现有方法仅在反向去噪过程中施加优化,没有对扩散模型原生的前向加噪过程的一致性进行约束,模型在训练后可能退化为与前向不一致的级联高斯。
- 采样器受限:需要依赖特定的一阶 SDE 采样器,无法充分发挥 ODE 或高阶求解器在效率与质量上的优势。
- CFG 依赖与复杂性:现有 RL 方案在集成无分类器引导 (CFG) 时需要在训练中对双模型进行优化,效率低下。
思路
为什么不直接在“加噪”的前向过程中融入奖励信号呢?与其在去噪的每一步艰难地“纠正”方向,不如从一开始就引导整个扩散过程,使其“避开”通往低奖励样本的路径。DiffusionNFT 将强化学习的目标巧妙地转化为一个对前向过程的微调任务,从而完全绕开了棘手的似然估计问题。
创新点
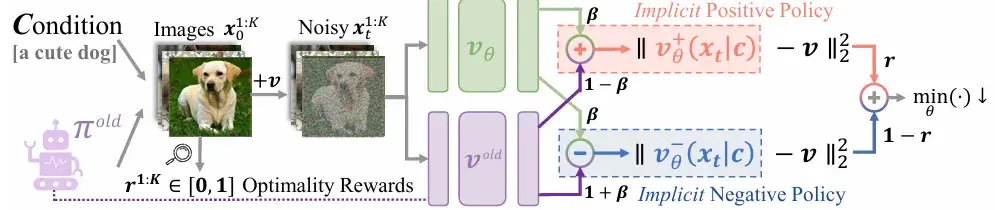
1 负例感知微调 (Negative-aware FineTuning, NFT)
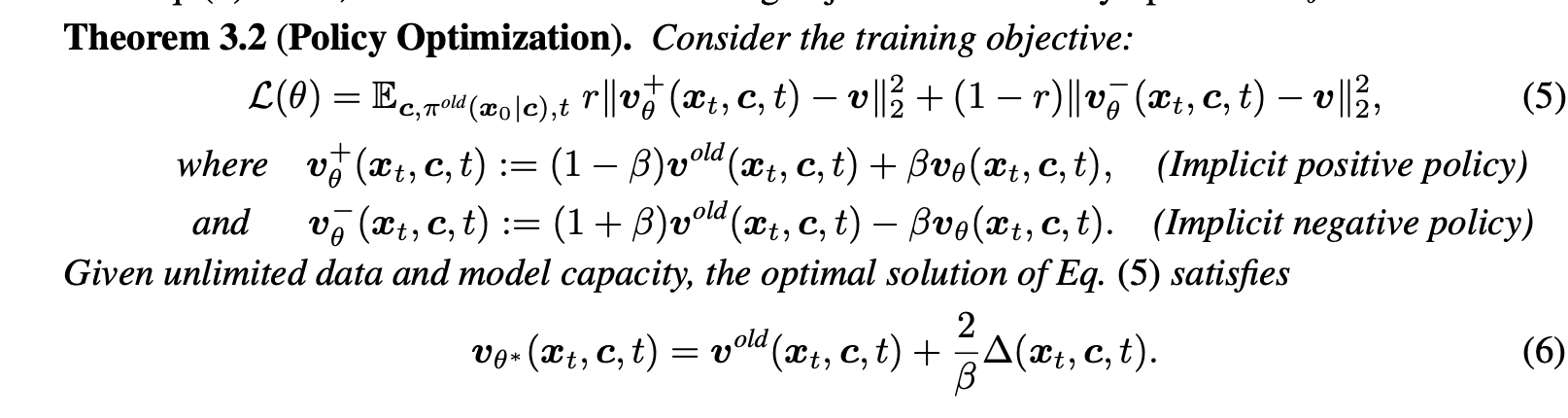
核心公式解释看^1,
代码跳读
入口scripts/train_nft_sd3.py
1 | for epoch in range(first_epoch, config.num_epochs): |
生成sampling
1 | def run_sampling( |
这部分逻辑和danceGRPO是类似的,但是训练没有对应逻辑,并且all_latents只用于计算x0
1 | x0 = train_sample_batch["latents_clean"] |
参考文献
AI Post Traning: DiffusionNFT